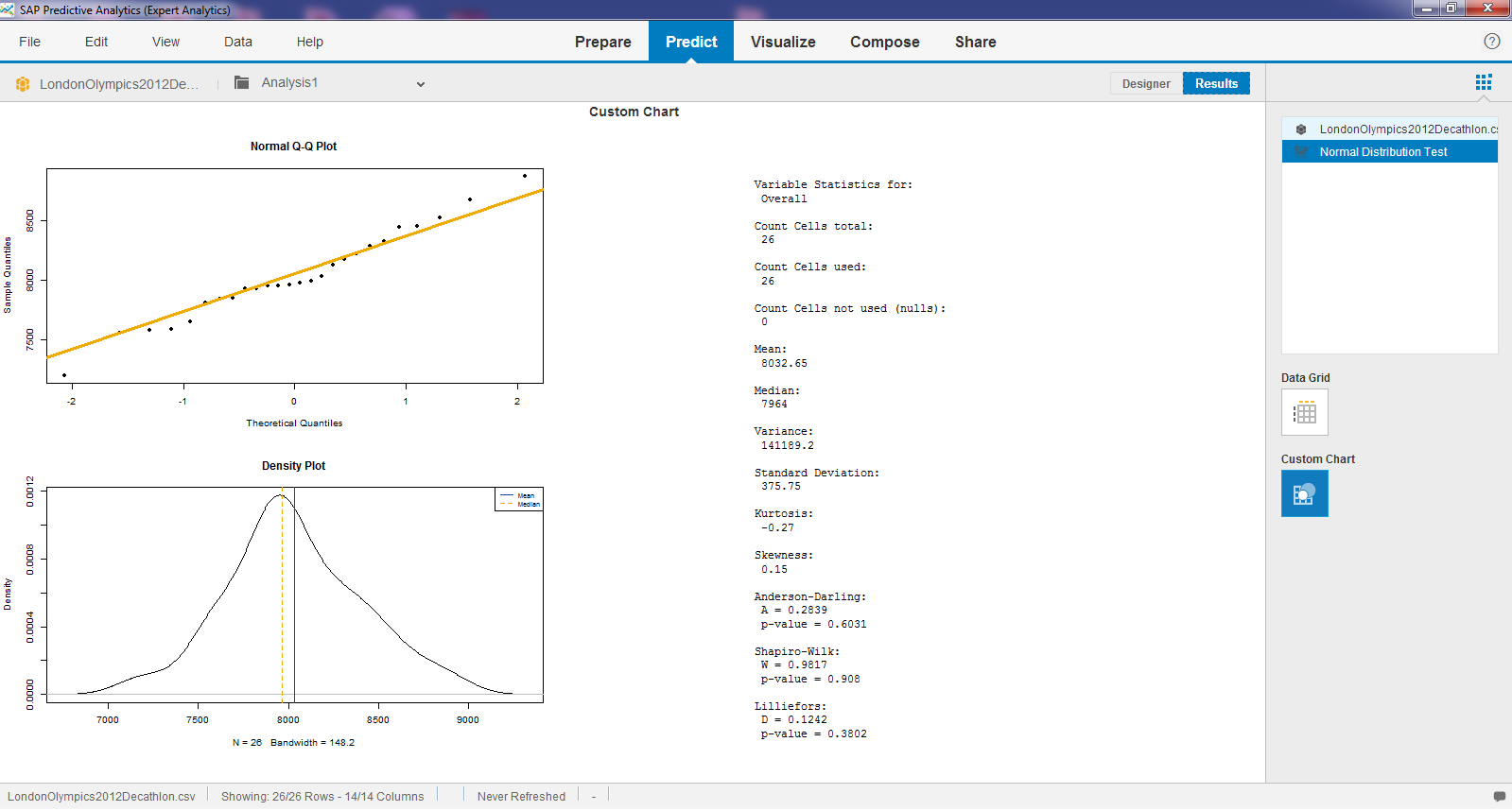
Many statistical or predictive methods assume data to be normally distributed. The residuals of a linear regression for example should be normally distributed, as should be measures that are analysed in a t-test.
This component helps understand how closely a numerical variable follows a normal distribution.
There are a number of options to assess such a resemblance. Often it is a personal choice of the user which methods to use. I personally prefer
- A density plot, that visualises the distribution
- A QQ-Plot, which should show the data points on a straight line
- Skewness as measurement for the asymmentry, which should be close to 0 for a Normal distribution.
- Kurtosis as measurement for the "peakedness" as Wikipedia puts it, which should also be close to 0 for a Normal distribution.
Other measurements calculated by this component are
- Anderson-Darling
- Shapiro-Wilk
- Lilliefors
Disclaimer
Please note that this component is not an official release by SAP and that it is provided as-is without any guarantee or support. Please test the component to ensure it works for your purposes.
Prerequisites
- R libraries e1071, gplots, nortest and stats must be installed.
Limitations
Anderson-Darling is calculated when the dataset contains more than 7 values.
Lilliefors is calculated for datasets with more than 4 values.
Shapiro-Wilk is calculated for datasets between 3 and 5000 values.
Usage
These parameters can be set by the user.
|
| Variable to test for Normal Distribution | Your numerical variable. |
No output columns added by this component.
How to Implement
The component can be downloaded as .spar file from GitHub. Then deploy it as described here. You just need to import it through the option "Import/Model Component", which you will find by clicking on the plus-sign at the bottom of the list of the available algorithms.
Example
You can try out the component wtih our own data or with the file LondonOlympics2012Decathlon.csv, which lists the number of points collected by the various athletes competing in the Decathlon at the London Olympics 2012. The total points collected for instance appear fairly close to a normal distribution (see column "Overall"). This is shown in the screenshot at the top of this article.
