
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Hadoop MapReduce as Virtual Functions in HANA
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Associate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-19-2015
7:11 AM
Note: This blog is not up to date as new functionalities have been introduced in SP10.
Hadoop offers large-scale, low-cost distributed storage called Hadoop Distributed File System (HDFS). When a large file is stored in Hadoop, it is broken into multiple fixed-size blocks and replicated across data nodes. Since the redundancy is on the small size block level, the recovery is faster and distribution is optimal. In order to process these blocks coherently, Hadoop introduced a programming paradigm called MapReduce (MR). By integrating with Hadoop, you can combine the in-memory processing power of SAP HANA with Hadoop’s ability to store and process huge amounts of data, regardless of structure.
Before SAP HANA SPS09, you can use the Smart Data Access to create virtual tables through hive ODBC driver for data federation scenarios. Start from SPS09, SAP HANA supports the integrations with Hadoop MapReduce (MR) jobs written in Java. You can create new type of User Defined Function with the direct access to HDFS and the vUDFs(Virtual User Defined Function) can be invoked from SQL directly that help customer to reuse their investments in MapReduce and solve the problems don’t fit the typical Hive usage patterns via SDA.
Here is the architecture diagram of the integration:

1. Install Hadoop adapter controller
You should have your Hadoop system installed already. SAP has created an adapter that can be installed as a delivery unit in HANA XS Engine and will be pushed to Hadoop later. This installation has been done in the system but it is good for you to understand how it works.
The controller can be downloaded from SAP Marketplace. After that, you need to assign the sap.hana.xs.lm.roles::Administrator role to your HANA user then start the HANA Application Lifecycle Manager to import it as a delivery unit.
HANA Application Lifecycle Manager URL is like below, replace the host and instance no. After login, click on Delivery Unit->Import->Browse and locate the tgz file and import it.
http://<yourhost>:80<instanceNumber>/sap/hana/xs/lm/

In the Hadoop side, the controller.jar should have been deployed at /sap/hana/mapred/<Revision>/controller/package in HDFS.
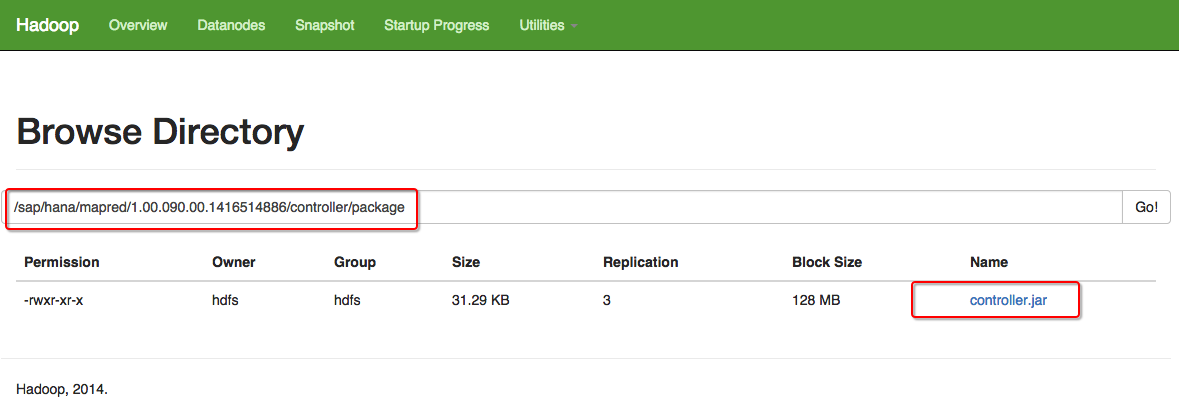
You will also need to put these two jar files at the path /sap/hana/mapred/lib in HDFS:

2. Create the MapReduce java project
You can ask to download the project from this blog. If you want to start from scratch, below are the steps.
In HANA Studio/Eclipse, create a new Java project, give it a name song_count, add the following jar files into a subdirectory lib and add them into class path of the project. You should see something like below after that.

Create the Mapper class with a name SongCountMapper.java in the package com.sfp and then copy the source code below. In the mapper, we find out the songs for each artist.
package com.sfp;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SongCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
@Override
public void map(Object key, Text value, Context output) throws IOException,
InterruptedException {
String[] song = value.toString().split(",");
output.write(new Text(song[3]), one);
}
}
Create the Reducer class with a name SongCountReducer.java in the package com.sfp and then copy the source code below. In the reducer, we aggregate the number of songs for each artist.
package com.sfp;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SongCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context output)
throws IOException, InterruptedException {
int count = 0;
for(IntWritable value: values){
count+= value.get();
}
output.write(key, new IntWritable(count));
}
}
Create the Application class with a name SongCountApplication.java and then copy the source code below. In the application, it incorporates the mapper and reducer, launch a MapReduce job the process data from the input path /sfp/song/data and put the result into path /sfp/job_result in HDFS.
package com.sfp;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SongCountApplication extends Configured implements Tool{
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new SongCountApplication(), args);
System.exit(res);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(SongCountMapper.class);
job.setReducerClass(SongCountReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("/sfp/song/data"));
FileOutputFormat.setOutputPath(job, new Path("/sfp/job_result"));
job.setJarByClass(SongCountApplication.class);
job.submit();
return 0;
}
}
Compile the java code and make sure there is no syntax error. The project should look like below now.

3. Upload the MapReduce Jobs Archive into HANA repository
In order to let HANA aware of the MapReduce code, we need to upload the jar file into HANA repository. HANA Studio can help to generate the jar file on the fly from your source code.
We firstly need to create a new package in HANA repository that we can store the jar file. Go to HANA repository(Create a new one if not created), create a new package sfp.song. Create a new general project in HANA Studio/Eclipse named song and share the project with the HANA repository. You should see a project like this after that. The project is really a placeholder for the MapReduce job archive, it is not necessary to create the .xsapp or .xsaccess file like other XS-based project deployed in HANA repository.

Select the project, click New—>Other.. and click SAP HANA—>Database Development—>Hadoop MR Jobs Archive in the pop-up window.

Click next and enter the file name as song_count then click next.

Select the Java project song_count, put the target Schema as your Schema, here is SFP and click Finish.

That will create a song_count.hdbmrjobs file, activate it and you will see it has been uploaded as a jar file in HANA repository by executing this query.


4. Create the Remote Data Source
Now it’s the time to create the remote data source by running the SQL statement below in SQL console of HANA Studio. You will need to replace the <FQDN> with your own Full Qualified Domain Name of your host that you can find it by running command hostname -f.
CREATE REMOTE SOURCE HADOOP_SOURCE
ADAPTER "hadoop"
CONFIGURATION 'webhdfs_url=http://<FQDN>:50070;webhcat_url=http://<FQDN>:50111'
WITH CREDENTIAL TYPE 'PASSWORD'
USING 'user=hdfs;password=hdfs';
Now you should see the Remote Source.

5. Create the Virtual Function
To create the virtual function, you can run the following SQL statement in SQL console of HANA Studio. The returns table structure need to be the same data types as the output structure of the Reducer, the Package System is the one you can find at view “SYS”.”VIRTUAL_FUNCTION_PACKAGES”, the configuration need to specify the input path of the MapReduce job where you put your data files in HDFS and the class name of the Mapper and Reducer.
CREATE virtual FUNCTION HADOOP_SONG_COUNT()
RETURNS TABLE ("song_artist" NVARCHAR(400), "count" INTEGER)
PACKAGE SYSTEM."sfp.song::song_count_job"
CONFIGURATION 'enable_caching=true;mapred_jobchain=[{"mapred_input":"/sfp/song/data","mapred_mapper":"com.sfp.SongCountMapper","mapred_reducer":"com.sfp.SongCountReducer"}]'
AT HADOOP_SOURCE;
6. Run the Virtual Function
Now you can simply run the virtual function like below.
SELECT * FROM HADOOP_SONG_COUNT();
It will trigger the MapReduce job and execute it in the Hadoop Cluster and populate the result into the output path of your Reducer, in this Reducer, it will be in /sfp/job_results in HDFS.

And you can find the job records in the job history UI at http://<your_hadoop_host>:19888/jobhistory

Clink the link to Download Source Code
- SAP Managed Tags:
- SAP HANA
29 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
296 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- Real time access management with SAP BTP Kyma serverless workloads in Technology Blogs by SAP
- SAP Sustainability Footprint Management: Q1-24 Updates & Highlights in Technology Blogs by SAP
- API Composition with Graph: customizing your Business Data Graphs with Model Extensions in Technology Blogs by SAP
- How to Connect a S/4HANA Cloud Private Edition System to SAP Start in Technology Blogs by SAP
- Real-Time Scenario Challenges and Solutioning for Action within Automation using S/4HANA On-Premise in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 36 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |