
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Behind the Scenes with Platform Search in Business...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-06-2014
12:00 AM
Most of people have noticed that Platform Search application works differently in Business Intelligence Platform (BI) 4.x comparing to previous release. The architecture of Platform Search has been changed significantly since BI 4.0. It provides scalable and flexible Business Objects content indexing and search infrastructure support for different proprietary BOE content types. It can be set to real time indexing, so that the user is not required to restart the Indexing every time when he wants latest indexing content. When the documents are published/modified/deleted in the repository, the application identifies those documents and they will be indexed. Alternatively, it can be set to schedule based indexing which will trigger the indexing based on the schedule time. In either way, the user can perform searching in BI Launchpad while indexing is happening. Platform Search also supports load balancing and failover for both indexing and searching in a clustered environment.
Platform Search service is the service in the Adaptive Processing Server, which has the logic to index the BOE content and search the content. It uses Apache Lucene, a free open source information retrieval software library from Apache Software Foundation. The version of Apache Lucene currently used by BI 4.0 and BI 4.1 is 2.4.1.
The functionality of the Platform Search service can be divided as Indexing and Searching. Before the content becomes searchable, the content needs to be indexed. In a large sized system with a large number of infoobjects, getting all the infoobjects fully indexed first time can be time consuming because indexing involves several sequential tasks. I will talk about the indexing process in this blog.
Indexing Process
Indexing is a continuous process that involves the following sequential tasks:
1. Use Crawling mechanism to poll the CMS repository and identifies objects that are published, modified, or deleted. It can be done in two ways: continuous and scheduled crawling.
2. Use Extracting mechanism to call the extractors based upon the document type. There is a dedicated extractor for every document type that is available in the repository. There are following extractors:
- Metadata Extractor
- Crystal Reports Extractor
- Web Intelligence Extractor
- Universe Extractor
- BI Workspace
- Agnostic Extractor (Microsoft Word/Excel/PPT, Text, RTF, PDF)
3. Use Indexing mechanism to index all the extracted content through the third-party library, Apache Lucene Engine. The time required for indexing varies, depending on the number of objects in the system, and the size and type of documents. It involves the following steps:
- The extracted content will be stored in the local file system (<BI 4 Install folder>\Data\PlatformSearchData\workplace\Temporary Surrogate Files) in an xml format called as Surrogate files.
- These surrogate files will be uploaded to Input File Repository Server (FRS) and will be removed from the local file system.
- The content of the surrogate files will be read and will be indexed by using specific index Engine into temporary location called as Delta Indexing Area (<BI 4 Install folder>\Data\PlatformSearchData\workplace\DeltaIndexes).
- The Delta index will be uploaded to Input FRS and will be deleted from the local file system.
- The Delta Index will be read and will be merged into Master Indexed Area (<BI 4 Install folder>\Data\PlatformSearchData\Lucene Index Engine\index) which is the final indexed area in the local file system.
For indexing to run successfully, the following servers must be running and enabled:
- InputFileRepositoryServer
- OutputFileRepositoryServer
- CentralManagementServer
- AdaptiveProcessingServer with Platform search service on
- AdaptiveJobServer (scheduled crawling)
- WebIntelligenceProcessingServer (content type is selected as Web Intelligence)
- CrystalReportApplicationServer (content type is selected as Crystal Reports)
4. Generating Content Store and Speller/Suggestions
After completing the Indexing task the following things will be generated:
- Content Store: The content store contains information such as id, cuid, name, kind, and instance extracted from the master index in a format that can be read easily. This helps to quicken the search.
Each AdaptiveProcessingServer creates its own content store (<BI 4 Install folder>\Data\PlatformSearchData\workplace\<NodeName>.AdaptiveProcessingServer\
ContentStores)
- Speller/Suggestions: The similar words will be created from the master indexed data and will be indexed. The speller folder will be created under “Lucene Index Engine” folder (<BI 4 Install folder>\Data\PlatformSearchData\Lucene Index Engine\speller)
Platform Search Queues
Internally, above indexing sequential tasks are handled by Platform Search Queues. When Indexing is started, an infoobject would eventually go through the following queues in this order:
To Be Extracted > Under Extraction > To Be Indexed > Indexing > Delta Index To Be Merged > Content Store Merge
If multiple Platform Search Services exist, there is only one To Be Extracted, To Be Indexed, Delta Index To Be Merged and Content Store Merge queue for all nodes. But each Platform Search Service has its own Under Extraction Queue and Indexing Queue. Only one Platform Search Service will be designated as the master service to do delta index merge into master index.
Each Platform Search Queue itself is an infoobject, the status of each Platform Search Queue can be retrieved by running the following query in the Query Builder:
SELECT * FROM CI_INFOOBJECTS,CI_APPOBJECTS,CI_SYSTEMOBJECTS WHERE SI_KIND = 'PlatformSearchQueue'
It will return the results with the following SI_NAMEs:
- Platform Search (Delta Index To Be Merged) Queue
- Platform Search (To Be Indexed) Queue
- Platform Search (To Be Extracted) Queue
- Platform Search (Exclude Documents) Queue
- Platform Search (Include Documents) Queue
- Platform Search Content Store Merge Queue
- Platform Search (Under Extraction - Enity - AcpzqPRw1thIk_GYPiEETF8)
- Platform Search (Indexing - Enity - AcpzqPRw1thIk_GYPiEETF8)
You will find a property called SI_PLATFORM_SEARCH_OBJECTS in each queue. That property displays the number of objects being processed in that queue. If SI_TOTAL of that property displays 0, it means that queue is empty.
Exclude Documents and Include Documents are two special Queues to handle the exclude documents. When you update the exclude documents in CMC > Applications > Platform Search Application > Properties > Documents Excluded from Indexing, the documents will be added to the Platform Search
(Exclude Documents) Queue. When infoobjects are extracted, they will be excluded.
When you remove the exclude documents in CMC > Applications > Platform Search Application > Properties > Documents Excluded from Indexing, the documents will be removed from exclude documents queue and added to the Platform Search (Include Documents) Queue. The crawling will only add documents to be extracted queue if only there is modification for the infoobject and its content or it is a new infoobject. In the case of those infoobjects removed from the exclude documents, they are neither new infoobject, nor modified, so they won't be picked up by crawling. They are added to this special queue, so that they will be added to the To Be Extracted queue.
From the Platform Search Queues result, you can see that Under Extraction and Indexing Queues are associated with a Platform Search Service session SI_CUID because each Platform Search Service has its own Under Extraction Queue and Indexing Queue. The information of Platform Search Service Sessions can be retrieved by running the following query in the Query Builder:
SELECT * FROM CI_INFOOBJECTS,CI_APPOBJECTS,CI_SYSTEMOBJECTS WHERE SI_KIND = 'PlatformSearchServiceSession'
Each Platform Search service should have one session. If the heartbeat (SI_PLATFORM_SEARCH_HEARTBEAT_TIMESTAMP) isn’t updated regularly on one session, other search service would try to return the hung service’s objects to the previous queue and take over unfinished work.
Here are some other useful queries you can run to get information regarding Platform Search Application.
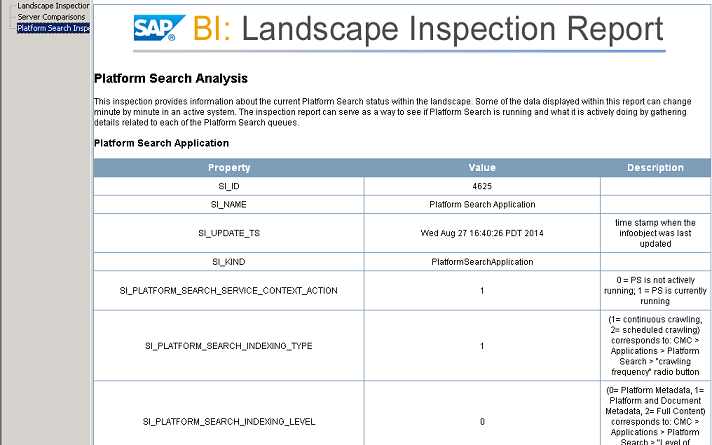
Retrieving the general information about Platform Search Application
SELECT * FROM CI_INFOOBJECTS,CI_APPOBJECTS,CI_SYSTEMOBJECTS WHERE SI_KIND = 'PlatformSearchApplication'
The property SI_PLATFORM_SEARCH_SERVICE_CONTEXT_ACTION shows if the indexing is running. 0 means Indexing is not running, 1 means Indexing is running.
Retrieving the information of Platform Search Application Status
SELECT * FROM CI_INFOOBJECTS,CI_APPOBJECTS,CI_SYSTEMOBJECTS WHERE SI_KIND = 'PlatformSearchApplicationStatus'
For example, you can check the following properties:
- SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_DAILY_MAX_OBJECT_ID
- SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_ID
- SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_MAX_ID
- SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_MAX_FOLDER_ID
- SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_UNIVERSE_ID
- SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_TIMESTAMP
SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_MAX_ID represents the SI_ID of the last infoobject which was added to the To Be Extracted queue. The infoobjects are added to the To Be Extracted queue in the batches. So if we have a batch of 100 infoobjects which are added in the To Be Extracted queue, this field will have the max SI_ID among the SI_IDs of those infoobjects.
SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_ID represents the SI_ID of the last infoobject which was added to the To Be Indexed queue. When indexing starts, this field will have the same value as SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_MAX_ID. But during the indexing if some infoobjects didn't get added to the To Be Indexed queue, then this field is updated with the max SI_ID of the infoobjects which actually got added to the To Be Indexed queue. And SI_PLATFORM_SEARCH_LAST_TO_BE_EXTRACTED_MAX_ID field is retained with the original value. For both these fields, the SI_IDs of folders are not included.
For the definition of above properties related to Platform Search, please use the latest release of the SAP BI Platform Support Tool. A new report option has been added in BI Platform Support Tool that will provide detailed information on the Platform Search and how it is performing.
I hope this blog helps you to understand how Platform Search Indexing works.
- SAP Managed Tags:
- SAP BusinessObjects Business Intelligence platform
16 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
- SAP Partners unleash Business AI potential at global Hack2Build in Technology Blogs by SAP
- It’s Official - SAP BTP is Again a Leader in G2’s Reports in Technology Blogs by SAP
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |