
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Comparing the Data Warehouse approach with CalcVie...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
werner_daehn
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-01-2014
7:38 PM
(see Comparing the Data Warehouse approach with CalcViews - Overview for the initial thoughts and the summary)
Order Entry Amount per period for a customer
Since Hana Live is the new kid on the block let us start with this. I want to know the sales order revenue per period for a given customer. The Hana Live View best suited is "_SYS_BIC"."sap.hba.ecc/SalesOrderItemNetAmountQuery" containing all the fields we need. Also, the underlying tables of the used system are quite large, 1.7 million Sales Order rows (VBAK) with 4.7 million Sales Item rows (VBAP) across multiple Clients, we filter on one Client which has 1/3rd of the data.
The query time is 0.3 seconds – perfect. Why would I ever want to copy all data to a Data Warehouse for such a query?

Order Entry amount per period for all customers
In the previous query data from a single customer was selected only. What about large amounts of data, say total revenue of all customers for 2012 and higher?
Query time is again in the sub seconds, around 0.5 seconds in fact. Amazing, isn’t it?

Order Entry amount for all periods, all customers
How about the complete data, no Where-clause at all?
This query leaves mixed feelings on my test system. Obviously that the ERP system is missing a conversion rate from RMB to EUR for the date 2011-01-25. Because of that the entire query fails.

It seems to be that single day only, as when excluding it, the query returns data.
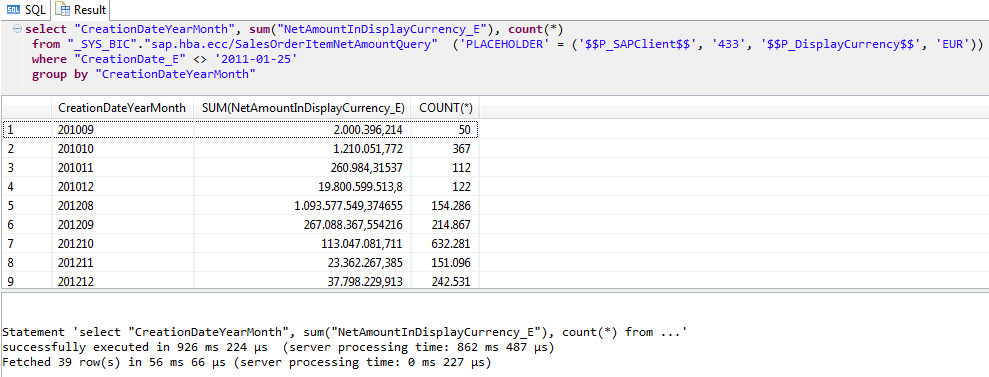
Performance wise we are getting closer to 1 second with this. Still good but if we would go for more complex queries it might be hard to stay below our goal of sub-second response times.
What can we do now? We just learned that, in exceptional cases, a currency rate might be missing. We could call up the IT department and tell them to upload the missing conversion rate. But actually this is not that uncommon, maybe the Calculation View should deal with that case itself and use the previous date’s rate? So we need to make the transformation, and therefore the Calculation View, more complex. And since the logic of a View is applied whenever somebody does query the data, performance will go down. Maybe just a little, maybe rendering the View performance inacceptable.
In a Data Warehouse these transformation would be performed whenever the changed data gets loaded. So the transformation would be done just once and the time the transformation takes is less important as no one is waiting.
Conclusion 2
When using Views you are limited in the amount of transformations. It is obvious that the more complex a View gets the longer it will take to return the data to the end user. If, on the other hand, the transformations are done upfront, while loading the Data Warehouse, the ETL run might take a second longer due to the additional logic but it would not have impact on the query performance.
Big question would be what kind of transformations are common and their impact on the performance. So let us have a look at that in the next example.
Joining master data
The most common transformation is the join. Actually each Calculation View itself requires joins of various tables already, that is the reason the queries above took so long. Now we want to add more tables, e.g. we change our query so that it does return the sales per material number and text.

Just because of one additional join the response time grew by 60%, from 0.862s to 1.117s.
Adding Customer and Customer Address did increase the response time to 1.4s.

Unfortunately you often require joins even if no data is selected from this table, because the table has the key to the next table. If for example the user wants to see the amount per customer region he would need the VBAP table as this contains the amount. From there join the VBUP table to get the customer id. This is can be translated to an address id using the KNA1 table. With the address id stored there you can join to the ADRC table containing the region code with which the T005U table can be read to get the region name.
VBAP->VBUP->KNA1->ADRC->T005U
Four joins are required in that example just to get to the region name. In a Data Warehouse you would probably store more keys in the sales line item table, e.g. the customer region key. As a result you would simply join the enriched VBAP table directly to the T005U table. Or add the address with all its sub information directly to the customer record.
Downside of that approach would be that whenever a customer gets a new address id assigned, many rows need to be updated. The order entry system would be slowed down if suddenly all the orders of the customer need to get updated, but in a Data Warehouse doing that when loading the changed data into the Data Warehouse is no problem.
Conclusion 3
Joins are surprisingly expensive operations. Does not matter if the View itself requires many tables or Views are joined together. It is the number of joins and the amount of data that matters. One of the major advantages of a Data Warehouse is the reduced number of joins required in queries.
Searching for data
A simple search might be based on a primary key, e.g. we search for one particular sales order.

Why does this take 0.6 seconds??? In the first Example the query did have a where clause on the SoldToPartyName and that completed in 0.266s! Can anybody explain?
How does a search look like in Hana?
1. Go through the ordered list of unique values of a column and find the index number for. (Key Compression)
2. Scan through the column values and find all occurrences of this index number. (Scan)
So there is one important difference between the Example 1 query and this search on the order number: The data distribution.
While 1.6 million rows in the SAP Client represent 636’000 sales orders, they all belong to just 117 customers. As a result the first step, searching in the unique values has to deal with a totally different amount of values.

But that cannot be the full explanation. In the ordered value list Hana can search for a given value very quickly and even if not, it is just 600k records, that’s nothing for Hana.
What datatype is the SalesOrder column? It is a varchar containing order numbers like ‘00001000’. The where condition we used was to compare that with an integer number. Therefore, in order to find the matching unique values, Hana cannot narrow down on the value in the ordered list, instead it had to take every single value, convert it to a number and check if the number matches the condition. That takes a few milliseconds.
Simple to proof, let’s compare with the actual string value instead: 0.088s.

In essence this example here boils down to the question of how often does the View provide the real data, how often does it return data some functions had been applied to. If you filter on the real data, using the real values in the condition (SalesOrder = ‘0004113377’), then Hana can utilize its unique value index, assuming the optimizer is clever enough. But if the column filtered on is built in on the fly, e.g. Concatenate CustomerName with CustomerID into a string like ‘Ama Inc. (00003523)’, and a filter is applied to this, then the slower approach has to be taken, in worst case the query has to be executed on all data in the table and filter later.
In a Data Warehouse these data preparation steps, convert the datatype, beautify strings, etc would all be done during the ETL phase and hence the target database would store the already converted data. Hence the search performance will be good in all cases.
Conclusion 4
Searching data coming from Views can be expensive. Sometimes as expensive as reading the entire tables even if a single record is found at the end only. On the contrary, in a Data Warehouse all columns of the view are stored in a table and hence it is a normal search using constants which Hana is excellent at.
Data consistency with foreign keys
Let’s have a look at our view, what it does actually.

It is a tree reading a table at the bottom and then joining new data to it and using projections. While many joins are inner joins, meaning e.g. a sales order line always does have a sales order header, quite a few relationships between tables are not enforced and hence require an outer join. Like Distribution Channel. Yes, a sales order can have a distribution channel but does not have to.
Executing a query that does include an outer join is usually more expensive. We can test that by simply selecting the distribution channel as well: 1.6 seconds.
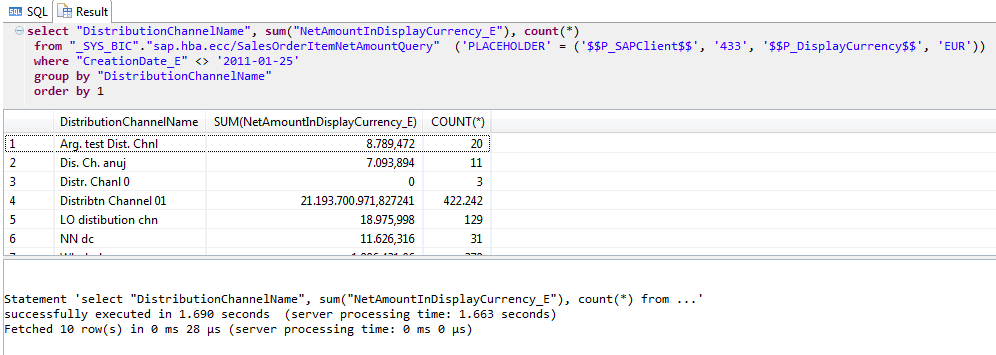
In a Data Warehouse all foreign relationships are made valid during the load. A sales order has no distribution channel? Then put the distribution channel “?” into the key column. A sales order has a value in the distribution channel column and there is no matching partner in the distribution channel table? Add a row into the distribution channel table with all values being a default, e.g. distribution channel name is “?”.
The extra time for straightening out the foreign key relationships is spent during the load of the record instead of at every single query execution.
Conclusion 5
With Views all foreign key relationships need to be dealt with at runtime. Is it impossible a key does not have a partner in the reference table? Can the key be null? What should happen if? In a Data Warehouse these issues are identified and corrected at load time, greatly speeding up the query performance.
Dealing with doubtful data
What should happen when entries in the ERP system are not correct? The classic answer is: we want to show the incorrect data so users have the motivation to correct it in the source system and hence help even the ERP processes. Sounds logical at first but we have seen that a missing currency conversion for a single day can render an entire query to fail with an error. In this case the user did not even see the wrong data, he got an error and that’s it. He cannot even fix the error himself but depends on somebody else.
The other problem we noticed already is that dealing with such problems inside the view costs considerable amounts of execution time. Not for the one erroneous row but because the query needs to be amended with logic dealing with such error just in case.
Another example is when the transformation logic itself has a problem. In the past the revenue was calculated by quantity multiplied with price. What else should it be? Yesterday a service company got acquired and now we get sales orders for service contracts, monthly payment of the service fee until the order is cancelled. Now the price * qty formula does not work anymore. This might not be noticed immediately, the query returns data and the only way to fix the problem is by changing the Calculation View.
But then there are true data errors, e.g. price is 100USD instead of 1000USD. That is something the system cannot fix and for sure it would be a good idea to correct the price in the ERP table, not manipulating the data somehow.
Then there are other data errors that can be corrected automatically, e.g. a customer has a male first name but its gender is female or missing? If we follow the rule of “data should be fixed in the ERP system”, then the user noticing the problem would send an email to the sales department, asking to provide the proper gender. As a result the sales department gets flooded with these little issues they do not even care about. All they care is the order can be shipped. Hence asking them for these tiny fixes won’t work. We can run an automated process trying to find inconsistencies and update the ERP table automatically. Sales department will not like that either when some algorithm updates the important customer record or breaks something, e.g. letter head reads “Mr. Chris Johnson” offending Christina Johnson. Dangerous.
And most important, quite often the Calculation View user does not even know he did something wrong.
A user might want to find out how many customers are in Beijing, China. Simple query: There are 15 customers.

He would now draw the conclusion that a marketing campaign in this city does not make sense and spend the money elsewhere.
What the user did not notice however, as it is not obvious, there are more rows with the CityName = BEIJING.

Just because the user did not know something, he has drawn the wrong conclusion. Is it the sales department’s fault to enter the CityName with two different spellings? Maybe. Will they correct all records? Unlikely. The shipments and the billing documents reached the destinations, from their perspective all is good.
But that is not the end of the story, the user should have actually executed below query to find 8 more customers in Beijing, the native spelling of the city name.

But even that is not all as the next query shows.

Four records have the wrong spelling, Bejing instead of Beijing. And 24 records have the correct spelling but the wrong country of DE. By looking at the street name, the postal code, the language flag you would know for sure that these are no German customers.
While for the latter case we can assume that this truly is a data error that should be corrected in the source, the spelling error is not that obvious. Of course it is wrong but does the sales department care enough to fix it?
There is a great danger in such wrong data. As long as it is obvious it is no problem. But an error the user does not recognize leads to wrong conclusions. As consequence the entire reporting solution is not trusted anymore and then the project as such is considered a failure.
In fact that is one of the main reasons why Data Warehouse projects fail, the queries produce wrong data. Not because the ETL logic is wrong, because of the source data. Just by performing the transformations in a Calculation View now, neither will it get easier nor is the problem made go away. A service order is still producing the wrong amount figures. A user not knowing the various spellings of a city name is still selecting a fraction of the data only. Actually it is worse as in a Data Warehouse additional options are available.
- Since all changed data gets processed, data consistency checks can be made. Are all sales order types the ones we expect? Is the data consistent in itself, e.g. country – postal code – city – street?
- If problems are found we can notify the source system users. To some degree the source system can be corrected automatically, for those records there is no doubt taking away lots of manual work from the people maintaining the data.
- Data can be enriched, e.g. in addition to the ERP city name an additional column with the standardized city name can be added and that is mostly.
- As the logic is executed for changed records and only once, way more sophisticated checks can be implemented.
The result would look like here where an additional column CityNameStandardized had been added. There the user can be certain only one spelling is found for each city. This does not fix bad input data somehow magically but
- Due to the standardization process faulty records have been identified and can be brought to the sales department’s attention. (Row 4 and 14)
- Valid records have a single spelling only (e.g. row 21)

Conclusion 6
While showing incorrect data in the source to make the problems visible has its merits, in reality this often leads to users not trusting the reporting solution any longer. Being able to explain each case does not help much when users do lose their faith in the solution and hence are not using it anymore.
Historical data
Imagine a query was executed yesterday, sum of revenue per country in 2011. The result was this:

Today the same query is executed but the result is a different one: Suddenly the new amount for the past did change, what belonged to Germany before is now in Austria!

All is correct, the company with that large revenue did relocate yesterday to Austria. Or in technical terms, the customer with the CustomerNumber 0000000187 got a new Address ID and this is an address in Austria. As said, everything is perfectly good, but is this what the end user wants to see?
In a Data Warehouse one of the important decisions is where to keep history, using which of the many options, where the current data is requested and where both, history and current data, is needed.
Using above example, in the Data Warehouse are two AddressIDs. The one was added to the fact table directly, so it contains the AddressID of the day of the booking. This is used for the historically correct query.

And then the customer has an AddressID, that is the current value.

Conclusion 7
Reports about past data can change at any time because most tables do not contain the full history in an ERP system. Neither needed nor wanted there. But for the user it can be a great surprise and problem if a report about past years does show other numbers, just because the master record got updated. In a Data Warehouse we have the same problem, but there we have options to decide for each data if and how to keep the history. It needs to be factored in when building the Data Warehouse however.
- SAP Managed Tags:
- SAP HANA
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
423 -
Workload Fluctuations
1
Related Content
- DTV Essentials: Key details that you should know – Part 1 in Technology Blogs by SAP
- Automate your Excel to Datasphere upload in Technology Blogs by SAP
- Generative AI for SAP. Part V: Models and Knowledge Graphs (KG) in Technology Blogs by Members
- BW Hierarchies and Flattening in BW via ABAP in Technology Blogs by Members
- SAP Datasphere News in August in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |