
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- Big Data Governance - Techniques & Technology
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-06-2014
8:06 PM
Big Data
In part one of this three part series we looked at Big Data Governance and the Three “V’s”. In part two we will take a look at different data structures consumed in Big Data scenarios, some techniques that support governance and technology considerations for storage and processing of Big Data.
Data Structures
In general, data exists in one of three types of formats, structured, semi-structured, and unstructured.
Definitions
- Structured data - refers to information with a high degree of organization, such that inclusion in a relational database is seamless and readily searchable by simple, straightforward search engine algorithms or other search operations. Structured data typically consists of defined data types, lengths, and formats – and acceptable (often predefined) set of values.2
- Semi-Structured data - is a form of structured data that does not conform to the formal structure of data models associated with relational databases or other forms of data tables, but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data.2
- Unstructured data - refers to information that either does not have a pre-defined data model or is not organized in a pre-defined manner. Unstructured information is typically text-heavy, but may contain data such as dates, numbers, facts, graphics, and spatial data. This results in irregularities and ambiguities that make it difficult to understand using traditional computer programs as compared to data stored in fielded form in databases or annotated (semantically tagged) in documents.2
Examples
- Structured data – Sensor data, machine data, mathematical model outputs, and ERP.
- Semi-Structured data – Emails, earnings reports, spreadsheets, software modules.
- Unstructured data – Text, videos, audio, graphics, images, and spatial data.
Techniques
In Big Data scenarios where there is a need to relate semi-structured or unstructured content to the more traditional structured data, one approach is to establish contextual metadata for the unstructured content as a means to relate it to the structured data. The contextual metadata for unstructured content should be oriented, if possible, towards similar known metadata of an organizations structure data. This provides the means to relate less structured Big Data content to an organizations structured data. There are a variety of techniques that can be applied to enhance the unstructured content to enhance the context and meaning of the data. Some of the techniques are described below:
- Establishing metadata and definitions - is used to help humans find specific items and is usually expressed as a set of keywords in a natural language.2
- Semantics Technology - encodes meanings separately from data and content files, and separately from the application code. This enables machines as well as people to understand, share and reason with the data at execution time.2
- Text Analysis – identifies the distribution and frequency of terms in textual content to establish keyword metadata and terms of interest.2
- Parsing– is used to refer to the formal analysis of content in strings into its constituent parts, resulting in a parse tree that shows the syntactic relationships between data and metadata, which may also contain semantic or other information.2
- Taxonomies- is the science of classification according to a pre-determined system with the resulting catalog used to provide a conceptual framework for discussion, analysis, or information retrieval.2
- Ontologies- are used to formally represent knowledge or content within a domain, information source or sources. Ontology is defined as a formal, explicit specification of a shared conceptualization of the information. It provides a common vocabulary to describe the types, properties and interrelationships of content or data within a domain or source. Ontologies tend to be broader in scope than taxonomies.2
For example, semantic technology can be used to identify keywords that help to provide context to the data. This enables organizations to more readily associate Big Data content from unstructured sources to those of traditional (structured) data and origins. Keywords can be organized into taxonomies or ontologies to further classify the Big Data content and enhance context and meaning.
Technology Considerations
Your data has a temperature. The temperature of you data affects where you store the content.
- Hot Data – Is accessed frequently and has a high value density.
- Warm Data – Is accessed less frequently or has a lower value density.
- Cold Data – Is accessed infrequently or has a low value density.
Where the data is stored, and how it is processed, is determined by the data’s temperature. When the frequency of content access and/or the data’s value density is high, In-memory appliances, such as SAP’s HANA, is often used for content storage and processing. When the frequency of access or the data’s value density is lower, High Performance Analytics Servers, such as SAP’s Sybase IQ, is used for content storage and processing. When the frequency of access and/or the data’s value density is low, low cost storage, such as Hadoop, is utilized for content storage. The following diagram depicts a model for content storage and data flows based on the data’s temperature:
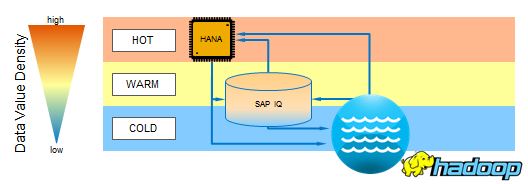
Big Data storage solutions and technologies need to take into account the temperature of the data and should be addressed as part of an organizations data retention policies and practices that manage the information lifecycle.
Is your organization managing the techniques and technology’s employed in your Big Data solutions? Have you considered the value density of Big Data content, and where it should be stored and processed? In part three, we will take a look at Big Data Governance - A New Kind of Governance.
2 Wikipedia, 2014
Related Content
- Sapphire 2024 user experience and application development sessions in Technology Blogs by SAP
- SAP Sustainability für Financial Services - Portfolio & Lösungen in Financial Management Blogs by SAP
- SAP Sustainability for Financial Services - Portfolio and Solutions in Financial Management Blogs by SAP
- GRC Tuesdays: Takeaways from the 2024 Internal Controls, Compliance and Risk Management Conference in Financial Management Blogs by SAP
- You are the Voice of HR! Participate Now in Sapient Insights Group’s 27th Annual HR Systems Survey. in Human Capital Management Blogs by SAP