
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Window function vs. self-join in SAP HANA
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-04-2014
4:17 PM
Intro
As we know, SAP HANA introduced window function since SPS05 Rev. 45. You can find this info from SAP HANA SQL (Changed) - What's New in the SAP HANA Platform (Release Notes) - SAP Library, section "New SQL Statements and Functions" as follows.
"Windows Functions (new)RANK, DENSE_RANK, ROW_NUMBER, LEAD, LAG: Divide result sets of a query into groups of rows called window partitions."
So, in this blog I want to share something about window function in SAP HANA with you. Since Window Functions - SAP HANA SQL and System Views Reference - SAP Library has already showed the syntax, the description and examples of window function in detail, I won't explain more about the basics of window function here. However, I'll focus on the comparison of window function and self-join in SAP HANA to show you why we need window function in SAP HANA.
Motivation
Recently I reviewed SAP HANA SQL and System Views Reference - SAP Library and when I read the section of window function, an question came to my mind. Can we implement the window function feature without using window function itself? Or in other words, if there is no window function in SAP HANA, how can we implement ROW_NUMBER, RANK, DENSE_RANK, etc.. these functions? Is it possible? :???: Now let's have a discussion/brain storming together.
Problems
Consider example 1 from Window Functions - SAP HANA SQL and System Views Reference - SAP Library. I just pasted the window dump as below.

Without window function in SAP HANA, can we implement ROW_NUMBER, RANK and DENSE_RANK and get the same results? It took a while for me to think about this question. Although I did not give it a shot, theoretically it should be possible if we use Cursors or ARRAY in SQLScript or we can use some methods described in SAP HANA: Dynamic Ranking using Script based (SQL Script) Vs Graphical Calculation view Vs Script ba.... However, all of these methods are a little bit complicated, since we need the knowledge of SQLScript and modeling which are not known by most new to SAP HANA. So an idea came to my mind, it's better if we can directly use SQL to implement this. So is it possible to just use one SQL statement to implement ROW_NUMBER, RANK and DENSE_RANK respectively?
In order to answer this question, first of all we need to clarify one thing. Why we need window function and what's the advantage of window function? Maybe you can point lots of reasons. Certainly you can. Here I just want to point out one reason - avoid self-join, because we can use self-join to implement most window functions. Believe it or not. Now let's give it a shot.
Scenario
For simplicity, I created a more simple scenario/table as follows and we just focus on COUNT, AVG, ROW_NUMBER, RANK and DENSE_RANK these five window functions.
CREATE COLUMN TABLE S (
CLASS VARCHAR(10),
VAL INTEGER
);
INSERT INTO S VALUES ('A', 1);
INSERT INTO S VALUES ('A', 1);
INSERT INTO S VALUES ('A', 1);
INSERT INTO S VALUES ('A', 2);
INSERT INTO S VALUES ('A', 2);
INSERT INTO S VALUES ('A', 3);
INSERT INTO S VALUES ('B', 4);
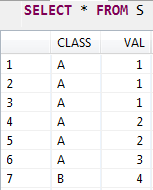
As you can see, we ignore the OFFSET column in example 1 above, since COUNT, AVG, ROW_NUMBER, RANK and DENSE_RANK do not need this column. Identical to example 1, we want to partition by CLASS and order by VAL to do some ranking stuff. In addition, I'll also show COUNT and AVG.
Window function vs. self-join
1. COUNT
Window function
SELECT CLASS, COUNT(1) OVER (PARTITION BY CLASS) CNT FROM S ORDER BY CLASS;

Self-join
SELECT A.CLASS, B.CNT FROM S A INNER JOIN
(SELECT CLASS, COUNT(1) CNT FROM S GROUP BY CLASS) B
ON A.CLASS = B.CLASS ORDER BY A.CLASS;

The logic is simple, first you create B which calculates COUNT of each class, then you make a join.
2. AVG
Window function
SELECT CLASS, AVG(VAL) OVER (PARTITION BY CLASS) AVG FROM S ORDER BY CLASS;

Self-join
SELECT A.CLASS, B.AVG FROM S A INNER JOIN
(SELECT CLASS, AVG(VAL) AVG FROM S GROUP BY CLASS) B
ON A.CLASS = B.CLASS ORDER BY A.CLASS;

The logic is similar with the example of COUNT.
3. ROW_NUMBER
Window function
SELECT CLASS, VAL, ROW_NUMBER() OVER (PARTITION BY CLASS ORDER BY VAL) ROW_NUM FROM S ORDER BY CLASS, ROW_NUM;

Self-join
SELECT A.CLASS, A.VAL, COUNT(1) ROW_NUM FROM S A INNER JOIN S B ON
A.CLASS = B.CLASS AND (A.VAL > B.VAL OR (A.VAL = B.VAL AND A."$rowid$" >= B."$rowid$"))
GROUP BY A.CLASS, A.VAL, A."$rowid$" ORDER BY CLASS, ROW_NUM;

First of all, you can see "$rowid$" is used in this example. You can find what it is from Do we have a ROWID or equivalent in HANA ? | SAP HANA. Actually "$rowid$" is undocumented and only available with column table. That's why I created column table instead of row table.
Regarding the logic, the ROW_NUM of each row is determined by "# of VAL which is less than mine" plus "# of VAL which is equal to mine and its row id is less than or equal to mine". Hope you can understand the logic. You may ask why I have to use the undocumented "$rowid$". Because S has no primary key, we need to have a "logical" primary key instead.
4. RANK
Window function
SELECT CLASS, VAL, RANK() OVER (PARTITION BY CLASS ORDER BY VAL) RANK FROM S ORDER BY CLASS, RANK;
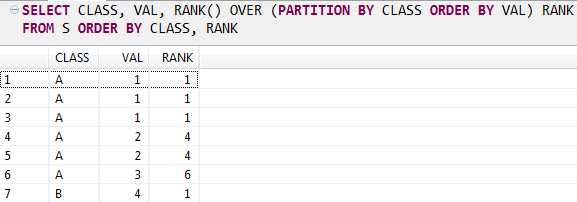
Self-join
SELECT A.CLASS, A.VAL, COUNT(1) RANK FROM S A INNER JOIN S B ON
A.CLASS = B.CLASS AND (A.VAL > B.VAL OR (A.VAL = B.VAL AND A."$rowid$" = B."$rowid$"))
GROUP BY A.CLASS, A.VAL, A."$rowid$" ORDER BY CLASS, RANK;

The logic is similar with ROW_NUMBER. Hope you can understand it.
5. DENSE_RANK
Window function
SELECT CLASS, VAL, DENSE_RANK() OVER (PARTITION BY CLASS ORDER BY VAL) DENSE_RANK
FROM S ORDER BY CLASS, DENSE_RANK;

Self-join
SELECT A.CLASS, A.VAL, COUNT(1) DENSE_RANK FROM S A
INNER JOIN (SELECT CLASS, VAL FROM S GROUP BY CLASS, VAL) B ON
A.CLASS = B.CLASS AND A.VAL >= B.VAL
GROUP BY A.CLASS, A.VAL, A."$rowid$" ORDER BY CLASS, DENSE_RANK;

As you can see, the logic is more simple than ROW_NUMBER and RANK because of the density.
Comparison of performance
Since we can implement most window functions with self-join, you may be curious about the comparison of performance between window function and self-join in SAP HANA. Therefore, I've also made some performance tests for you.
Test environment:
- SAP HANA SPS08 Rev. 80
- CPU: 8 cores
- Memory: 64GB
- Disk: 200GB
Data set:
- Identical table definition to the above scenario
- 100,000 records in total
- 1,000 classes
- ~100 values per class
| Function | Window function (ms) | Self-join (ms) | Ratio |
|---|---|---|---|
| COUNT | ~80 | ~80 | ~1X |
| AVG | ~90 | ~90 | ~1X |
| ROW_NUMBER | ~100 | ~2500 | ~25X |
| RANK | ~100 | ~2500 | ~25X |
| DENSE_RANK | ~100 | ~1500 | ~15X |
We can do some analysis from the above table.
- COUNT, AVG: You can find the performance of window function and self-join seems the same. It's true because the join condition only contains "=" which means only hash-join happened.
- ROW_NUMBER, RANK: Window function has much better performance (25X) than self-join, since the self-join contains non equi join.
- DENSE_RANK: B is kept smaller than S itself and the logic is more simple, so the ratio (15X) is smaller than ROW_NUMBER and RANK.
Conclusion
In this blog, we found a simple way (self-join in SQL) to implement the window function in SAP HANA. We implemented COUNT, AVG, ROW_NUMBER, RANK and DENSE_RANK with the self-join approach. And we compared the performance between window function and self-join in the end. For better performance, we should always use native window function in SAP HANA instead of self-join. On the other hand, if self-join exists in your SQL statement, please think about if it is possible to implement the logic with window function.
If you have any better idea how to implement the window function in SAP HANA, e.g., implement my scenario without using "$rowid$", please feel free to let me know. Look forward to your feedback on this topic.
Hope you enjoyed reading my blog. :smile:
- SAP Managed Tags:
- SAP HANA
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
92 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
298 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
421 -
Workload Fluctuations
1
Related Content
- Demystifying the Common Super Domain for SAP Mobile Start in Technology Blogs by SAP
- Problems when opening a PDF in my SAPUI5 app in Technology Q&A
- How to retrieve value from modal window? in Technology Q&A
- Connection restrictions and their relation to user groups in SAP HANA Cloud, SAP HANA Database in Technology Blogs by SAP
- Calculation View Features of 2024 QRC1 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 38 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |