
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Leveraging SAP BI4.1 with SAP HANA
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member18
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-11-2014
11:25 AM
The goal of this blog is to update you on the enhancements delivered since SAP BusinessObjects BI4.1 to leverage the SAP HANA platform. Please refer to the SAP 4.1 documentation to have more details.
This blog is covering several features introduced in SAP BI 4.1 Web Intelligence and Information Design Tool that will help you leverage your HANA investment. Please note that previous recommendations with BI 4.0 on top of SAP HANA still apply.
- SAP BI 4.1 Universes on top of HANA: HANA Business Layer authoring enhancement, HANA Multi-view universes
- HANA variables and input parameters with BI 4.1
- HANA Database Ranking with BI 4.1
- Query stripping Relational with HANA + Auto-refresh use case.
Automatic HANA universe generation (available since BI4.1 SP2)
From an authoring standpoint, the Information Design Tool (IDT) has been enhanced to facilitate Universes development on top of SAP HANA. IDT is now able to generate a HANA Business Layer automatically based on HANA Views.
The default process for creating a business layer on a data foundation containing SAP HANA views takes into account the metadata as defined in the SAP HANA information model. The New Business Layer wizard automatically creates the dimensions and attributes in each SAP HANA view in a business layer folder, and creates measures with the appropriate aggregation function.
You could do this manually prior to BI4.1 SP2. Please refer to this document for more details on the manual steps: Business Case for the BI4 Semantic layer and Web Intelligence on SAP HANA
The SAP HANA Business Layer option is available when you create a new IDT project

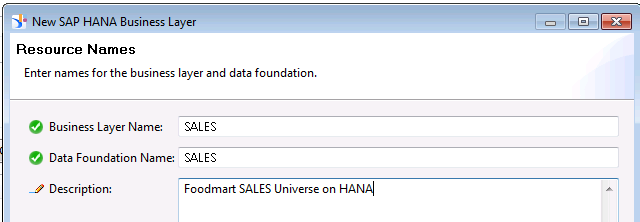

The New SAP HANA Business Layer wizard automatically creates a data foundation and business layer based on selected SAP HANA views. When multiple SAP HANA views are present in the data foundation, any dimensions and attributes that are common to different views are created as a single business layer object, and special aggregate-aware objects are generated to make queries on multiple views possible.
In the following screenshot, we are selecting 2 distinct Analytic Views
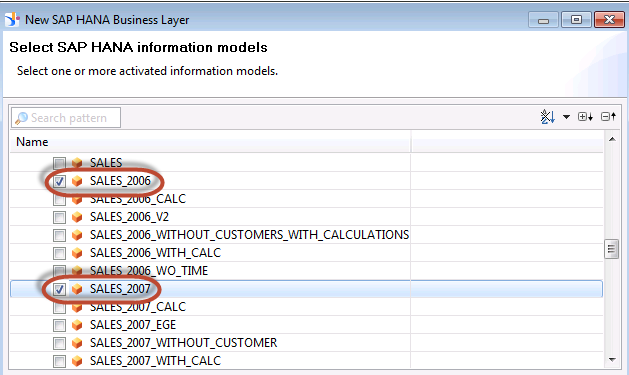
The HANA Business Layer is generated with the appropriate @Aggregate_aware function. By doing this, the Universe information engine will be able to generate the most optimal query to HANA. In this scenario, the Universe is leveraging aggregate awareness to access the HANA view in the most optimal manner.

In the Data Foundation, a self-join is generated randomly for each Analytic view. The reason behind is to avoid joining HANA views with each other as that could impact performances. As you can see in the below screenshot, a “dummy” filter will be generated in the SQL statement and the 2 HANA views are not joined.

The HANA Business Layer automatic generation will also configure the aggregate navigation’s incompatible objects for you. This will make sure the end user does not query incompatible objects from the query panel.
In the below screenshot, we can see that the incompatible objects were set automatically for each table.
- Table foodmart/SALES_2006 is incompatible with SALES_2007 objects

- Table foodmart/SALES_2007 is incompatible with SALES_2006 objects

We can test the results by creating a query with a dimension “Product” and 2 measures (“Store Sales” from the SALES_2006 HANA View and “Store Sales” from the SALES_2007 HANA View.
In the below screenshot, the Universe will generate two separate queries hitting the 2 HANA Views with a full outer join performed on the client side.


As a result, the query will generate a result set from both SQL flows in the same table whenever possible.

The goal of this functionality is to enable ad-hoc WebIntelligence reporting on top of HANA. The end user doesn’t have to know which or how many HANA views are being accessed and the Universe will generate the most optimal and performing query transparently.
HANA variables and input parameters (available since BI 4.1 SP3)
Variables and input columns defined in the SAP HANA information model are now included in the data foundation. When refreshing the data foundation, new, deleted, and updated variables in the data source are taken into account.

In Web Intelligence, SAP HANA universes behave like any other relational UNX universe; HANA variables and input parameters in SAP HANA information models are associated with the corresponding tables in the data foundation.
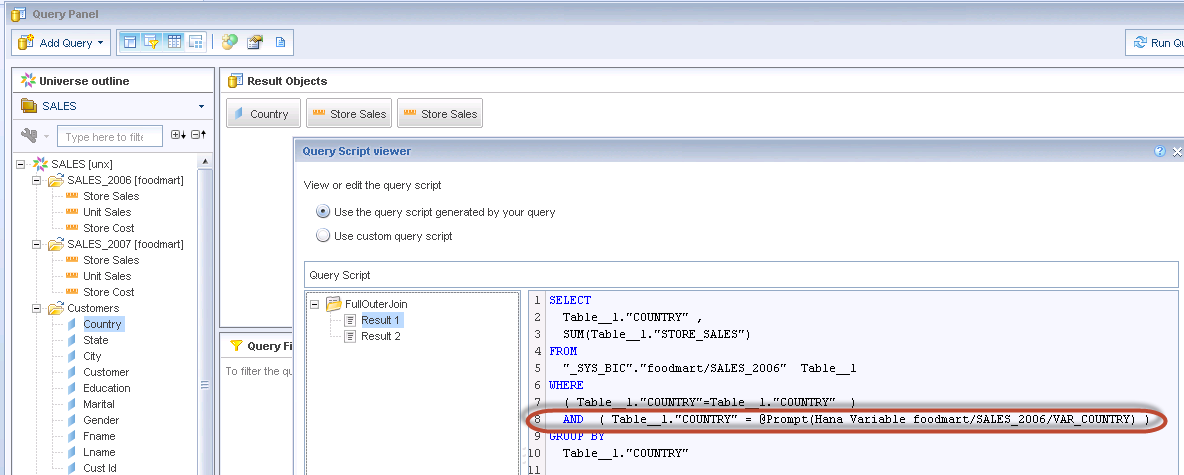
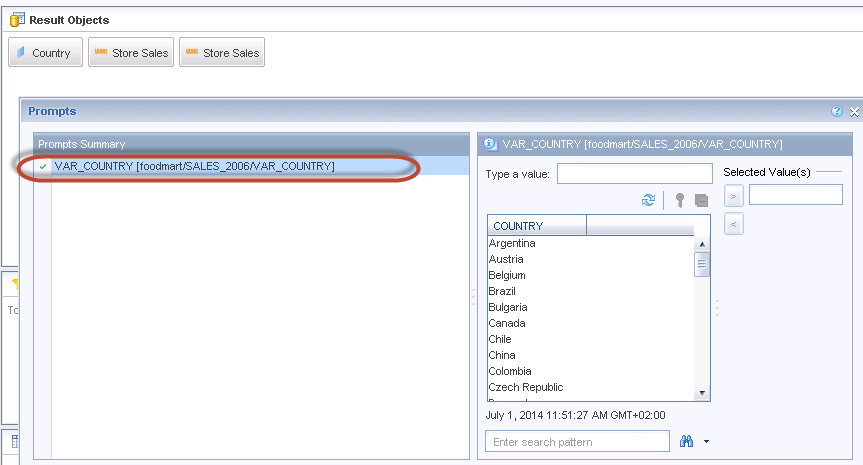
When you run a query that includes HANA variables and input parameters in the Query Panel or when a document is refreshed, prompts appear that require you to specify values for those variables and parameters. The values available in the prompts come directly from the HANA source
HANA Database Ranking (available since BI4.1 SP3)
You can now set the ranking of data in an SAP HANA universe. Queries based on objects with universe-level ranking will take less time to fetch data. You can use HANA Analytic functions such as RANK() and PERCENT_RANK for ranking filters

- SQL generation for RANK()
![]()
- SQL generation for PERCENT_RANK()
![]()
Query Stripping Relational (available since BI4.1 SP2)
Query stripping is now available for relational universes (including universes on SAP HANA) as well as OLAP universes. Query stripping is a reporting feature that can be used to optimize performance by automatically rewriting the query to retrieve only objects included in the report. It is used only by SAP BusinessObjects Web Intelligence.
The following steps will show you how to configure and enable query stripping on relational Universe (in this example a HANA Universe)
In the Business Layer Query options, check the Allow query stripping option and publish the HANA Business Layer

In the Web Intelligence query panel> Query properties, check “Enable query stripping”

In the Web Intelligence document property, check “Enable query stripping”

Create a report to test the query stripping. In the screenshot below, the dimension in bold are stripped and are not included in the SQL statement anymore unless you add them in the report canvas.

If you drag and drop a stripped dimension into the report canvas, you’ll get a #REFRESH message instead of the dimension’s data. This is normal as the dimension is not in the SQL anymore, you have to refresh the dataprovider manually by clicking “Refresh”

If you want to perform this action more transparently for the end user, you can enable the Automatic Refresh feature available since BI 4.1 :
In the CMC go to Application > Web Intelligence > Properties > Automatic Refresh

In the document property, enable the “Automatic Refresh”

Auto-refresh works only when delegated measures are involved in the report
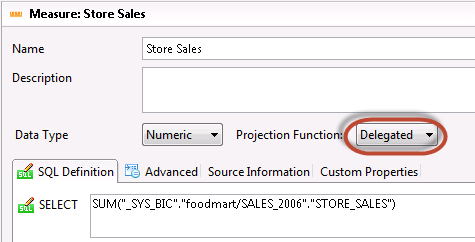
If you now drag and drop a stripped dimension into the report canvas, a refresh will automatically run so you don’t have to manually click on the refresh button.
- SAP Managed Tags:
- SAP HANA,
- SAP BusinessObjects - Web Intelligence (WebI)
10 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
103 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
69 -
Expert
1 -
Expert Insights
177 -
Expert Insights
326 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
374 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
458 -
Workload Fluctuations
1
Related Content
- SAP 分析云 2024.09 版功能更新 in Technology Blogs by SAP
- How can I change SAP schema user (e.g SAPABAP1 or SAPHANADB) password? in Technology Q&A
- What’s New in SAP Analytics Cloud Q2 2024 in Technology Blogs by SAP
- How to transform a date into calendar week in SAC within the model data in wrangling in Technology Q&A
- How to access an On premise odata service in SAP BTP in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 21 | |
| 8 | |
| 8 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 5 | |
| 5 |