
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- Reuse of existing tables using data access classes
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-02-2014
11:04 PM
Introduction
In this blog post you will read about a way to integrate your existing data models into BOPF. After some basics there will be an example of a data access class for a BO consisting of two tables containing data for a header and items.
What is the purpose of a data access class?
When moving existing developments to BOPF you will surely face the fact that you already have some data in application tables and that there will be numerous development objects accessing this database table. Next challenge will be that the key of that table will not match the requirements of tables created by BOPF. Because of other developments referencing your old table and the data within it you cannot migrate to a database table created by BOPF. To solve this issue you can implement a data access class building the bridge between the framework and the database.
Preliminary thoughts and consequences
Before starting to implement let’s think about some aspects that may influence your implementation.
Refactoring
If you look at the structure of your database table, is there something you may do different if you could design it from scratch? If your answer is yes it’s the perfect starting point to do so. The data access class is a kind of abstraction layer so you are free to make the necessary changes. A typical thing you should change is the admin data. There is a good reuse function within BOPF saving efforts of implementation. If you are not taking the chance now you will never do it.
There are only two reasons why you may not refactor the structure. That’s if you are just playing around with the framework or if you are sure you will never migrate to BOPF generated table layout. In these cases you would remain a higher complexity (due to mapping) forever.
Remaining direct references to the table
You should only stick to your old tables if BOPF is not the only development component accessing the data. If only BOPF will access the data you should always use the generated tables to get the max of the framework. Be careful with the remaining references to the table. It those are inserting, modifying or deleting entries directly be sure to prevent concurrent access leading to inconsistencies. Consider those references within your migration strategy to switch to the BOPF API with a higher priority than read accesses.
Transient vs. persistent GUIDs
The framework always uses GUIDs to identify the entities. You have the choice to create these guids only during runtime or to add them to your existing database table. If you are just playing around with the framework to gain some experience it is okay to use transient guids. Mapping transient guids during runtime costs time and is resource consuming for mass activities. Prefer to use persistent guids in your database table. It’s just a one time effort to fill the new fields.
Business logic
The purpose of the data access class is to mediate between the database and the framework and to adapt the database structure to the node structure of your BOPF BO. As a result you should never ever put any business logic into this class. Errors occurring within this layer (normally database errors) will surely lead to an abort of the current transaction.
HANA Optimization
When using your own implementation for the access of the database you are also responsible for optimizing your coding for the HANA platform. The framework cannot use it’s standard features for HANA optimization.
Class for the BO or for the node
You can choose to implement a data access class that provides the data for all nodes of the BO or for one node of the BO. In my opinion it depends on your decision to use transient or persistent GUIDs. When using persistent GUIDs it will be a good choice to create one class per node, but if you are using transient GUIDs you will need access to the internal mapping table of at least the parent node. In this case I would prefer using a single class for the complete BO.
Implementation
Before we are stating to implement the data access class (DAC) you should be familiar with the BO Builder for Experts (transaction BOBX). To get familiar with this transaction please use the getting started guide created by thea.hillenbrand.
Data model
The data model is an easy one. We have the table ZDAC_HEAD containing header data that will be the root node and we have the table ZDAC_ITEM that contains the item data.

The tables can look like this:
| usage | screenshot |
|---|---|
| header table |  |
| item table | 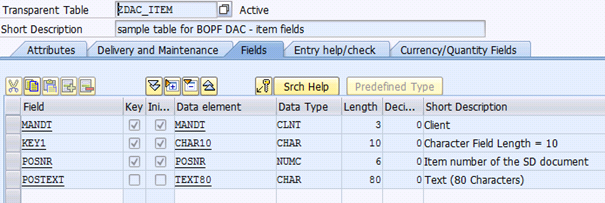 |
The BOPF model will be that easy too. It will look like this.

Within this BO you will reference the following dictionary objects:
| usage | screenshot |
|---|---|
| persistent structure for node ROOT | 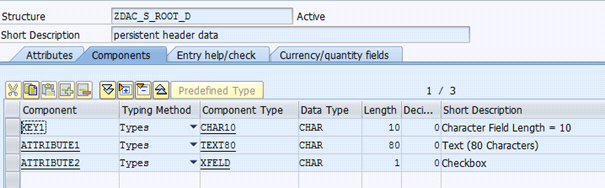 |
| persistent structure for node ITEM |  |
| alternative key for node ROOT | 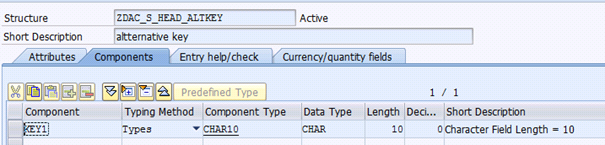 |
| table type to alternative key |  |
Creating the data access class
An attachment to this blog contains the complete source of the data access class. The sample BO will use transient guids so it will contain optional coding for this mapping. To be able to use a data access class you have to switch to the extended mode of the transaction BOBX.
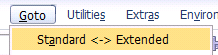
As a result you will see a new field for the data access class.

As a naming convention I would recommend ZCL_<name of BO>[_<node>]_DAC. To create the class just use the double click. The system will detect automatically if the class needs to be created.
The system will create a class with the two interfaces:
- /BOBF/IF_LIB_DATA_ACCESS (Tag Interface Data Access Class)
- /BOBF/IF_BUF_DATA_ACCESS (Interface for Database Access)
Base class /BOBF/CL_DAC_IMPLEMENTATION
In my example I will inherit from class /BOBF/CL_DAC_IMPLEMENTATION. This class provides a ready-to-use implementation of the interface method GET_INSTANCE. This method is a static method. When using this class as your base class be sure that the implementation suites your requirements. Static methods cannot be redefined. This standard implementation will return an instance per node.
Conversion Methods
Before implementing the interface methods I would recommend to create methods to handle the conversion between the persistent structure of your BO and the database table.

They will be used in the methods to read and write the BO data.
Query
In this method you will perform a select on the database to fetch the keys of the records that match the selection criteria. You can also execute authority checks for the selected data. As a result you will return a table with keys only. The detailed data will be fetched by the read method. The steps to proceed are:
- Map selection criteria to range tables
- Select keys from database
- Optional: build transient guids and fill mapping table
- Optional: perform authority checks
Read
In this method you will read the detailed data for a list of keys. If you are implementing a data access class to serve for several nodes you should delegate the call to specialized methods for each node. The steps to proceed are:
- Optional: map transient guid to database key
- Prepare the buffer line (key fields)
- Select record from database
- Create data reference for the persistent structure
- Call conversion method to transform database structure to the persistent structure
Read by Attribute
If you have specified an alternative key for your node, this method will be called to return the keys for those records in the exporting parameter ET_RESULT. In addition you can return the detailed data for those records in the export parameter ET_DATA. If the data table is empty the read method will be called later on demand. The steps to proceed are:
- Select records from database
- Optional: build transient guids and fill mapping table
- Optional: read detailed data for the records
- Return table with keys
Read Composition
This method will be called for the target node to resolve the association between a parent node and its children. You will return the child entries. To achieve this you have to proceed as follows:
- Optional: map transient guid to database key for the parent node
- Select keys for child records
- Optional: build transient guids and fill mapping table for child node
- Return key information
- Optional: read and return detailed data
If you do not read the detailed data here they will be fetched on demand by the read method.
Write
This method is responsible for updating the database records. Like in the read method you should delegate to specialized methods for each node if you are having one class for the complete BO. Each record has contains information about the change mode. There are numerous change modes within the framework. You should take care of the following change modes within this method:
- C = create
- U = update
- D = delete
If there will be old coding that can change database records as well you should take special care for data consistency. If only BOPF will have write access to these tables the framework will care for data consistency automatically. But it cannot control the world outside the framework. In the attached source code of the data access class you will find hints about extended data protection.
If the write access to the database fails you should raise an exception of the class /BOBF/CX_DAC. It already contains all you will need in this method. Please keep in mind that this exception will abort your transaction, but it’s better than having inconsistencies in your database.
Summary
Exposing your existing database tables to the framework with a data access class is easy, but it is just the starting point to get a complete BO. After those basics you will have to create your actions, determinations and validations to get a fully functional BO. In another blog post I will write about strategies on how to move your existing development to BOPF.
- SAP Managed Tags:
- ABAP Development
16 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
8 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
4 -
ABAP in Eclipse
1 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
8 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
2 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
6 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
4 -
DMS
1 -
dynamic logpoints
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
IBM watsonx
1 -
Integration & Connectivity
9 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
12 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
text editor
1 -
Tools
14 -
User Experience
4
Top kudoed authors
| User | Count |
|---|---|
| 6 | |
| 5 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |