In Part 1 of the blog, we introduced the business scenario of Data Service for SAP Lumira Cloud and the basic workflow.
In actual business, as an IT admin I don’t always want to load a full chunk of source data to the target, especially if the volume of data is big, I only want to insert the new records since my last update. Also, if my existing data has updated values, (e.g. sales revenue of the same record has changed), how can I update the desired record?
Advanced workflow using enhanced HCI upload settings
In advanced HCI upload settings, SAP Lumira Cloud introduced Primary Key to help fulfill these needs.
In the new example, we have a story called Best Run Corp Margin Analysis.
The end user created a story board based on initial data and published it to SAP Lumira Cloud.

(1) The visualization has a filter setting there which selects records for Q4 2013 only. In the example, we will not add new records for the filtered quarter but instead we will update the values of that quarter.
Steps for using advanced upload settings
- As team admin, find the dataset that you want to apply advanced settings, click “HCI Upload Settings” from its action menu.

In the pop up dialog, select one or more dimensions that will form a primary key.
Validate the Primary Key – While selecting the dimensions, you can click on the Validate button to see if the combination of dimensions has unique enough values that can form the primary key. Keep selecting and validating until you see the validation is passed. You will get a green check as in the screen below.
Apply the Primary Key – when you pass the validation, click on the Apply button so the primary key is applied to the dataset.

2. As team admin, log on HCI again and create a new task that can leverage the primary key.
Note in this example, we are using HANA DB as the source for data refresh.

Then, just as in the basic workflow, you need to select the Lumira Cloud datastore as the target in the next step.

3. Next, you will start to define the dataflow following the wizard.
Make sure you import the dataset that has the primary key you set previously.

In the next step, it is critical that you select the option of “Auto correct load based on primary key correlation”.
Note that compared to the basic data upload workflow, now this new option is enabled because HCI detects the dataset has a primary key. Selecting this option will enable UPSERT for data upload.

4. Now as team admin, you don’t want to load the full chunk of data to the target. Instead, you want to filter the desired data, e.g. all new records since Q4 2013. In this case, you need to define a variable for the data flow.
Close the previous data flow screen. Edit the task by going to the EXECUTION PROPERTIES tab, and then click the “+” button to add a variable.
Note it is important to define the name, data type and value for the variable.

5. Edit the data flow again to finish the task creation
From the screen above, click OK to close the variable definition. Click on the DATA FLOWS tab. Select the data flow and select Edit.

In the visual data flow screen, use drag and drop to
1). Add an intermediate transformation
2). Link source table to the transformation

Double click on Transform1 to do the intermediate mapping and filtering.

When the intermediate mapping is done, close the screen and continue with the final mapping as before – double click the Target_Query icon from the visual data flow, use the output columns from Transformation1 as the new input, and map them to the target columns.

6. Run the task and check the result
When the task is finished, go back to SAP Lumira Cloud.
As the end user, you can open the story again to compare the data.

7. Promote the task to production for scheduled refresh
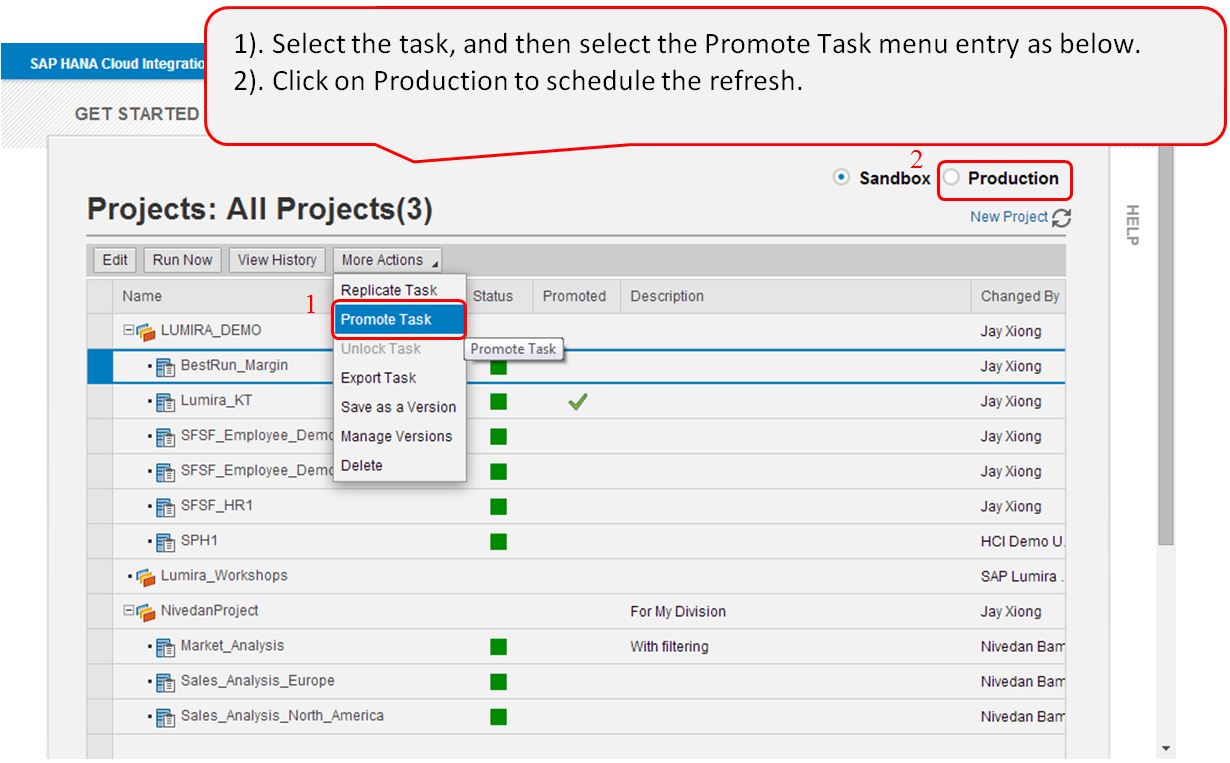
In the Production environment, select the task you want to schedule, and click the Schedule button.

In the pop up screen, enter the scheduling details.

Summary
With the introduction of data services by integrating with HCI, SAP Lumira Cloud enterprise users can now upload and refresh their data on cloud by sending the data from their enterprise database systems in a more scalable way.
The data upload and refresh job is mainly designed for IT admin type of user, therefore end users can easily delegate data refresh tasks to team admin so end users can concentrate on their own business.
Once the data upload and refresh task is setup, future refresh can be scheduled and therefore it also makes IT admin’s job easy.
In short, the new data service integration feature makes enterprise users much more empowered on SAP Lumira Cloud for always having up to date data from enterprise data sources.
