SAP BusinessObjects Data Services 4.1版本开始支持Hadoop作为数据源进行操作,包括HDFS和Hive两种作为sources和targets。相关的Hadoop组件包括:
1.Hadoop distributed file system(HDFS):在节点上存储数据,利用集群提供非常高的聚合带宽。
2. Hive:一个数据基础仓管,可以让管理员使用SQL-Like的方式操作Hadoop数据,下一篇文章将介绍如何利用Hive进行数据迁移。
3. Pig:一个高等级的数据流语言和并行计算的执行框架,处于Hadoop顶端,(Map/Reduce上层)。Data Services使用Pig脚本来读写Hadoop的数据,包括Join操作和push down操作,本文主要介绍如何配置使用Pig进行数据迁移。
4. Mapr/Reduce:一种计算范式,应用程序被划分成很多部分,每一个部分可能执行在集群的任何的节点上。Data Services使用 map/reduce处理文本数据。
在sbo411_ds_reference_en中有介绍总体步骤,但是忽略了细节部分,本文利用截图和说明的方式介绍如何配置。
配置步骤
1.安装Hadoop和 Pig(使用非root用户,例如“hadoop”)。
2. 安装IPS和Data Services(4.1)在Hadoop的Namenode节点上。
如果你使用其他用户(例如“dsuser”)安装了Data Services,那么你应该设置HDFS中的所有文件夹为的权限为777除了hdfs://namenode:9000/home/hadoop/hadoop-datastore/hadoop-hadoop/mapred/staging/dsuser/.staging(此文件夹为700)。设置本地文件夹/home/haodoop/tmp 权限为 777。
注意:IPS和Data Services应该被安装在相同的文件夹中,否则用户无法在CMC中找到Data Services项目。
3. 为了确保与Hadoop交互的环境变量设置正确,Job Server应该执行环境变量脚本,例如:
source $LINK_DIR/hadoop/bin/hadoop_env.sh –e
./svrcfg (to restart Job Service)
4. 安装Data Services Client在Windows上,并且添加一个Data Services的repository的ODBC。
注意:如果你使用HANA作为repository,user不能使用System。参见上一篇文章。
5. 使用Designer连接Data Services server。
Username: Administrator (Username of CMC)
Password:
Repository password: (HANA User’s password)
![1.png]()
![2.png]()
6. 添加一个Hadoop HDFS file format并且配置 HDFS,PIG以及Hadoop中数据的格式。

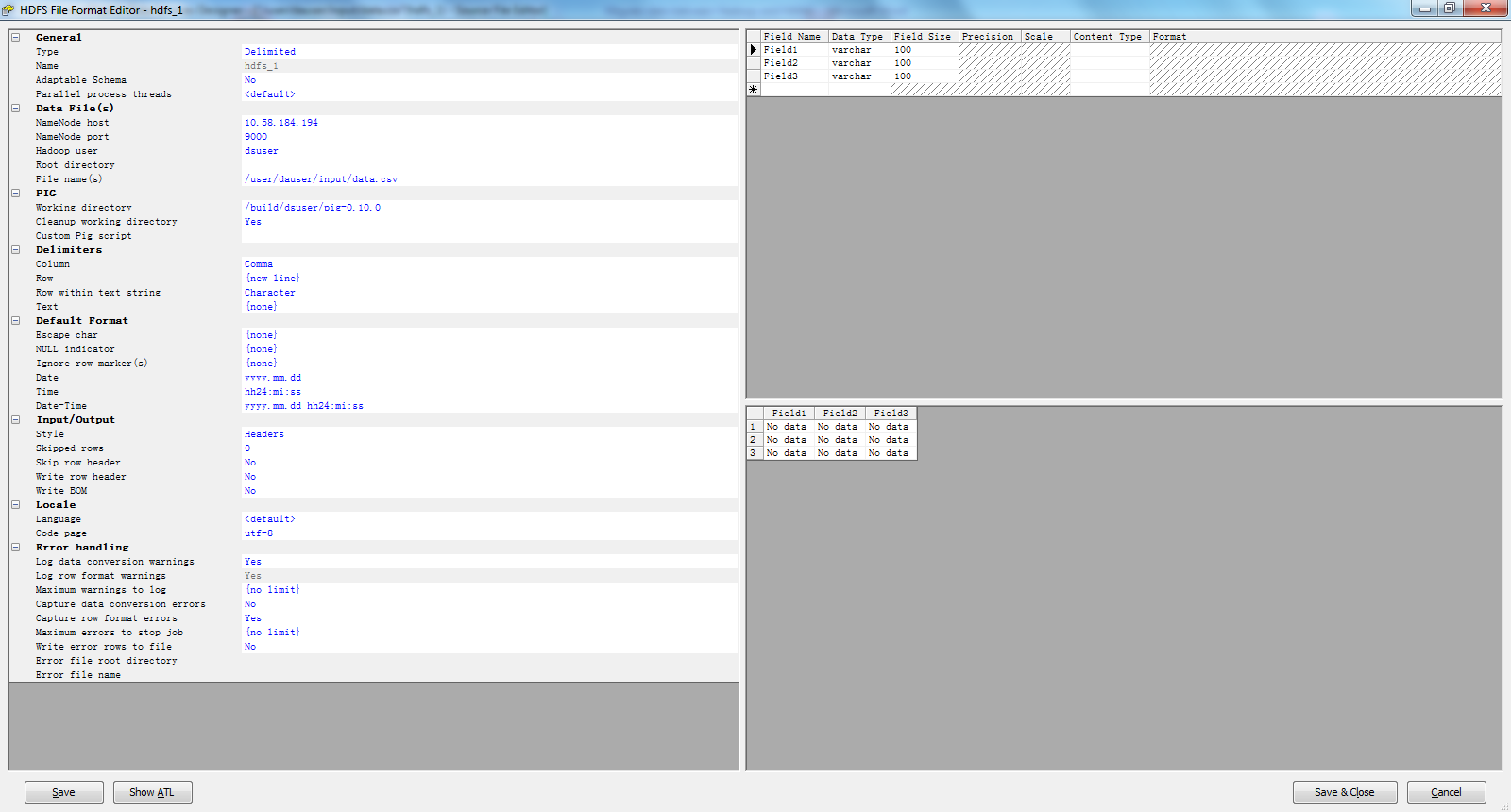
7. 创建一个HANA data store。
![5.png]()
8.创建一个query 组件以Hadoop作为源,以HANA作为目标,设定源和目标的map。![6.png]()
9.画一条Data flow 在源和目标之间
![7.png]()
10.开始迁移。
本文的测试案例所使用的SAP HANA版本为SAP HANA SPS7 Revision 70.00,SAP BusinessObjects Data Services 4.1 Support Package 1,Hadoop 1.1。想获取更多SAP HANA学习资料或有任何疑问,请关注新浪微博@HANAGeek!我们欢迎你的加入!
转载本文章请注明作者和出处<文章url>,请勿用于任何商业用途
