
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA Smart Data Access(3)—How to access Hadoop...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-02-2014
4:33 AM
We have a Chinese version(SAP HANA Smart Data Access(三)——如何利用SDA通过Hive访问Hadoop数据) of this blog.
Introduction
In previous blog of this series, we talked about how to install and configure the data source of SDA in SAP HANA Server side. As most data sources supported by SAP HANA are all database, the procedure of installation and configuration is similar. But for Hadoop data source, something is different. As a distributed data processing platform, Hadoop usually store data in HDFS file system, or in NoSQL database HBase which is also usually based on HDFS. However, both of HDFS and HBase don’t support ODBC protocol. So we need another member of Hadoop family to solve this problem, it is Hive. Hive implements SQL interface for HDFS and HBase, and HiveODBC driver is also provided. In this blog, we’ll talk about how does SDA access the Hadoop data through Hive.
Deploy Hadoop and Hive
The Official version of Hadoop supported by SAP HANA SDA is “Intel Distribution for Apache Hadoop version 2.3” (Including Apache Hadoop version 1.0.3 and Apache Hive 0.9.0). Although there’s only one version in the official supported version list, the experiment of this blog shows that SDA can also access the data stored in ordinary Apache version of Hadoop. The experiment of this blog build up a Hadoop cluster containing 3 nodes, and the version of Hadoop and Hive is : Apache Hadoop 1.1.1 and Apache Hive 0.12.0.
As the guide of deploying Hadoop and Hive can be easily found in internet, we don’t discuss it here. After deploying Hadoop and Hive, some data for experiment needs to be prepared. Here, We use a user information table, the structure of the table is :
Column Name | Data Type |
USERID | VARCHAR(20) |
GENDER | VARCHAR(6) |
AGE | INTEGER |
PROFESSION | VARCHAR(20) |
SALARY | INTEGER |
Data can be imported from csv file into hive table. Firstly, create a table using hive shell.
create table users(USERID string, GENDER string, AGE int, PROFESSION string, SALARY int)
row format delimited
fields terminated by '\t';
Then, import data from csv file to the users table:
load data local inpath '/input/file/path'
overwrite into table users;
Here, the data is imported from local file system, Hive can also import data from HDFS. In this experiment, the number of records in users table is 1,000,000. After importing, count the record number:
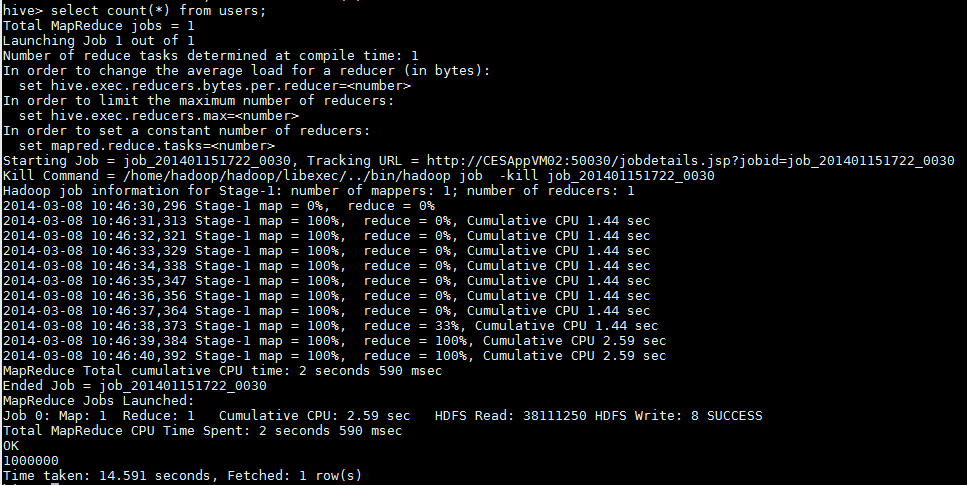
As shown in the picture above, Hive call the MapReduce to query data, and it takes 14.6 seconds to count the record number of users table. Afterwards, select out the top 10 records of the table:

As we see, it takes 0.1 second.
Installing and configuring HiveODBC Driver
Same as installing driver for other data sources, installing HiveODBC driver also requires unixODBC installed in the SAP HANA Server side. HiveODBC requires unixODBC-2.3.1 or newer version. For more details about installing unixODBX, please see the reference [2].
unixODBC installed, Begin to install HiveODBC driver. As introduced in reference [2], we use the HiveODBC provided by Simba Technologies. The procedure of installing is like below:
- Download Simba HiveODBC driver package, and decompress the package to a certain directory. Then enter the directory: /<DRIVER_INSTALL_DIR>/samba/hiveodbc/lib/64 (use 32 to replace 64 if it’s for 32-bit system) to check the driver file libsimbahiveodbc64.so.
- Login SAP HANA Server as sidadm.
- Execute “HDB stop” to stop the SAP HANA.
- Copy the file “/<DRIVER_INSTALL_DIR>/simba/hiveodbc/Setup/simba.hiveodbc.ini” to the home directory of sidadm.
- Edit the ~/.simba.hiveodbc.ini with vim.
- If there’s one row “DriverManagerEncoding=UTF-32”, change it to UTF-16.
- Check the ErrorMessagePath = /<DRIVER_INSTALL_DIR>/simba/hiveodbc/ErrorMessages, correct it if it doesn’t points to right path.
- Comment out the row: ODBCInstLib=libiodbcint.so, and add a new row: ODBCInstLib=libodbcinst.so.
- Edit the .odbc.ini file in home directory of sidadm, add a new DSN for hive, the default port for hive is 10000, here’s an example:
[hive1]
Driver=/<DRIVER_INSTALL_DIR>/simba/hiveodbc/lib/64/libsimbahiveodbc64.so
Host=<IP>
Port=10000
10. Edit the file $HOME/.customer.sh to set some environment variable:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:
/< DRIVER_INSTALL_DIR>/simba/hiveodbc/lib/64/
export ODBCINI=$HOME/.odbc.ini
11. Use isql to check whether SAP HANA Server can connect to remote data source successfully:
isql –v hive1
12. If connect successfully, execute “HDB start” to start SAP HANA.
Create hive data source
When installing and configuring HiveODBC finished, create the hive data source in SAP HANA Studio following the steps introduced in Reference [1]. Here, you need to choose the HIVEODBC as the adapter.
After hive data source created, you can view the tables in hive, as shown in picture below:

Query Hive virtual table
Add a new virtual table which maps to table users in Hive following the steps introduced in Reference [1]. Then count the record number of the virtual table:

As shown above, it takes 14.1 seconds to count the virtual table in SAP HANA Studio, which is close to the time it cost in Hive side. The result tells us that SAP HANA SDA doesn’t influence the performance of operation in remote data source when little data transmission involved.
Conclusion
In this blog, we illustrate how SAP HANA SDA access the Hive table stored in Hadoop using a simple example. Hive is a tool which provide SQL interface for Hadoop. From the experiment result, querying the virtual table in SAP HANA Studio and querying the Hive table in Hive side is very close in performance when little data transmission involved.
Reference
- SAP Managed Tags:
- SAP HANA
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
92 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
298 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
421 -
Workload Fluctuations
1
Related Content
- SAP IQ を利用した SAP Information Lifecycle Management(ILM) in Technology Blogs by SAP
- 全ての SAP BW、SAP BW/4HANA リリースの SAP ニアラインストレージ(NLS)ソリューション – SAP IQ in Technology Blogs by SAP
- SAP IQ – 隠れた宝物 … in Technology Blogs by SAP
- SAP AI Core with pyspark in Technology Blogs by SAP
- Extend the Power of Data for SAP RISE Customers: data federation with SAP in multi-cloud GCP in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 38 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |