Some of the new features of Modeler are listed below:-
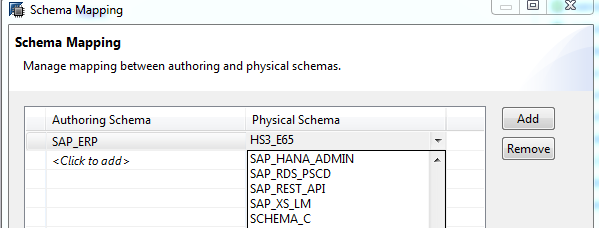
Schema mapping changes
In schema mapping dialog selection of physical schema is based on drop down. Moreover there are additional ‘checks’ in the wizard and
you will not be allowed to create schema mapping for schema which exists in the system as authoring schema. Also it is not possible to create schema mapping for same authoring schema more than once.
Package authoring schema:-
SP8 onwards it should be possible to set a package authoring schema by running SQL as
below:
Insert into "_SYS_BI"."M_PACKAGE_DEFAULT_SCHEMA" values ('<yourpackage>', '<schema name>');
This feature is useful when you have multiple schema mapping to same physical schema and then you have to edit a HANA model by adding a table from the physical schema.At this moment if you do not have package authoring schema set, the physical schema will be set as authoring schema. And then if you transport this model to some other system you will run into errors. But if you set the package authoring schema your models will continue to work after you transport the models into another system.
Mass copy changes
Now you can select sub packages as target in mass copy wizard. Also as a user you can decide where to store the mappings either in Global catalog table or in your local workspace. This option can be set in Mass copy wizard as shown below

Allow the sorting of parent child hierarchies by attributes
As you already know, in SP7 you could supply an ORDER BY <column> even on parent child hierarchy and this would override default ordering on the child column. Now in SP8 you can specify ORDER BY with sort direction in hierarchy wizard
Allow decimal/float type without specifying length
We are now allowed use data type DECIMAL and FLOAT in calculated column, input parameters etc.. without specifying length and scale .
If length and scale are not specified, DECIMAL becomes a floating-point decimal number. FLOAT can be used without specifying a length.
If length is not declared, it becomes a 64-bit double data type by default.
Parameter mapping to external views for value help
Now Modeler supports input parameter mapping for external views for value help while creating variables and input parameters. So whenever you perform data preview, the values for the ‘value help’ can be fetched from the mapped input parameter of the external information view. This is supported in analytic and calculation views.
Optimize join columns
The join optimization will be enabled in the view model from SP08 on (only for calculation views). It is offered in the Join properties. The default for a new join (node) will be optimizeJoinColumns=’false’

Join columns are usually kept during the instantiation process of the calculation engine. This makes sure the join attributes are always kept and passed down to the underlying nodes no matter which attributes from the joined tables are requested. This ensures that aggregations below are always executed on the same level and the aggregated values are not changed purely depending on the selected nodes.
However for calculation views with a star join this is usually not required and these models usually have a huge number of join attributes. To optimize these kinds of views one can set this flag to true, which enables the optimization of the join attributes. I.e. join attributes are removed and not passed down to the underlying layers in case they aren't requested in the query.
Note: When this property is set to true for a join, left outer & right outer joins as well as text joins alone are supported for following cardinalities:
left outer join or text join (which is deployed as a left
outer join as well on the calc engine level): 1:1 or n:1 cardinality
right outer join: 1:1 or 1:n cardinality
Higher precision for currency conversion
You can specify data type of a measure with currency conversion. This will only be possible for base measures, not for calculated measures. The motivation is that the inherited data type might have too few decimal places resulting in rounding errors after the conversion. With the new feature a data type with sufficient decimal places can be specified
Show alert for productive system
When the usage type of a system is 'Production', the user will be alerted while performing a specific activity which will affect the system state or consumption of artifacts.
In modeler, there are various activities that show this alert, for example Activation & Redeploy, Schema mapping, Generate Time Data, Delivery unit import, Refactor, BW Model import etc..
The system can be set as production system while installing or later in system configuration
Once the system is set as ‘production’ then you will get alert while performing specific activity in modeler as mentioned above.

Support for Unicode characters
HANA Modeler will allow creation of information view(s), column names in Unicode characters. For this you need to set the preference in Field name preferences
Performance work bench
User can configure the threshold for the number of rows for a data source in the preferences page, which if crossed for a particular data
source, there is a warning icon displayed for that data source in the scenario panel. The threshold cannot be greater than 2 billion, as HANA itself allows a
maximum of 2 billion rows in a table and if a table exceeds that limit it has to be partitioned.
Also the user will be allowed to choose if he/she wants to work in performance analysis mode or the usual one. With the performance analysis mode switched on,
- User can see number of records in a table, with warning icon beside it if it crosses the threshold set in the preferences for the number of rows.
- Detailed partition information of all the catalog table at that node
The user can switch on the performance mode through a tool bar toggle button in editor.

Thanks
Shreepathi
