
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- How does table record numbers influence performanc...
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-10-2014
5:57 AM
Test environment and test data preparation
Read via Index field, single record returned for each table
Read via table key field OS_GUID
Read via Non-index fields, one record returned
Read via Index fields, multiple and different number of records returned for each table
Read via Index fields, multiple and fixed number of records returned
Read via Non-index fields, multiple and fixed number of records returned
Table entry mass update
Summary
Recently we are handling with one customer complaint about performance issue in their production system. We are investigating from both ABAP side and DB side to seek potential improvement. Regarding DB side, we are working together with customer on possible DB index optimization.
On the other hand, we observed the database tables which causes the performance pain have a huge number of records ( among 50 ~ 200+ millions ). We do see the possibility to achive some history data, however we are not sure whether customer could get the performance gain after achiving.
So I did a small experiment to try to get the draft idea about the relationship between table record number and performance.
Test environment and test data preparation
Database: HANA DB with release 1.00.74.00.390550. The test is done on our internal system. It makes more sense to test in customer's system since customer is currently using a NON_HANA DB but unfortunately I cannot achieve it - I need to write several reports to generate the massive test data and my request to ask for a user in their sandbox system didn't get approved. I hope finally I could have the chance to repeat this experiment on customer sandbox system.
The table causing performance issue is PPFTTRIGG, which is a standard table in SAP CRM, storing transaction data of action framework processing detail.
In customer system it has 75 million records. In ST12 its DB time always ranks the first in trace result.
For the table itself:
Red color: Key field
Blue color: Index field
Yellow color: Non index field

I copy the standard table into ten new Z table with exactly the same technical settings, and fill each Z table with 10 millons ~ 100 millons records.
For field os_guid, appl_oid and medium_oid, I use function module GUID_CREATE to generate new guid and assign to them.
For other field like applctn, context and ttype, I read all possible values from their value table and assign to table records evenly.
Table name | ZPPFTTRIGG1 | ZPPFTTRIGG2 | ZPPFTTRIGG3 | ZPPFTTRIGG4 | ZPPFTTRIGG5 | ZPPFTTRIGG6 | ZPPFTTRIGG7 | ZPPFTTRIGG8 | ZPPFTTRIGG9 | ZPPFTTRIGG10 |
Table record | 10 millons | 20 millons | 30 millons | 40 millons | 50 millons | 60 millons | 70 millons | 80 millons | 90 millons | 100 millons |
The following measurement are done against the ten Z tables. All the time recorded in this blog is measured in millisecond by default.
Read via Index field, single record returned for each table
I use index field appl_oid, which could ensure only unique record returned for each Z table. The time is measured in microsecond.

I test it repeatedly and the result always shows that the time does not increase linearly according to the number of table records.
Read via table key field OS_GUID
The time is measured in microsecond.
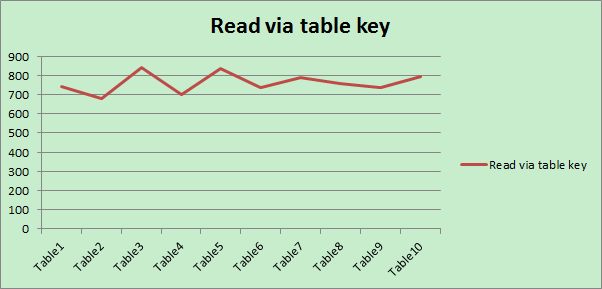
The result shows it is on average a little faster to read via table key field compared with reading via index field.
Read via Non-index fields, one record returned
In this case I query the ten tables via non-index field MEDIUM_OID. Each query only returns one result for each Z table. The time is measured in microsecond.

All three kinds of read operation could ensure the unique record returned by SQL statement, sorting based on efficiency: read via key > read via index field > read via non-index field
Read via Index fields, multiple and different number of records returned for each table
The read is performed on index field applctn and context.

The X axis represents the number of records returned via SELECT * INTO TABLE <record set> FROM <ztable > WHERE applctn = XX AND context = XXX for each Z table.
Read via Index fields, multiple and fixed number of records returned
Similar as test above, but added UP TO 6000 rows to force the SQL on each Z table always returned the fixed number of records.

Read via Non-index fields, multiple and fixed number of records returned
I perform the read to retrieve all records for each table which has flag is_changed marked as abap_true. Before testing, I manually change the table entries for each Z table to ensure all ten tables have the exactly the same number of records with is_changed marked as abap_true.

Table entry mass update
The update operation is done on the non-index field is_changed. First I use SELECT UP TO XX to retrieve the given record set which has is_changed = abap_true, and then use UPDATE <Z table> FROM TABLE <record set> to update the table. The execution time of statement UPDATE <Z table> FROM TABLE <record set> is measured:
when doing mass change on the ten tables one by one in the same session, <record set> contains 10000 entries to be updated:



before my testing, my assumption is that the consuming time for updating will increase linearly according to numbers of table records.
However it seems according to this test result that the number of table records will not degrade the update performance at least in HANA DB.
Summary
Based on this test result, it seems in HANA DB, there would be no significant performance improvement for read operation which only returns a unique record, even if number of table records reduces dramatically( reduction from 100 millions to 10 millions ). The same holds true for update operation via UPDATE <DB table> FROM TABLE <record set>.
For read operation with multiple records returned, no matter index or non-index fields is used, fixed or different number of records are returned, the time consumed for read always increses almost linearly with number of table entries. In this case customer could still get the benefit from table archiving.
- SAP Managed Tags:
- ABAP Development
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
8 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
4 -
ABAP in Eclipse
1 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
8 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
4 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
7 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
4 -
DMS
1 -
dynamic logpoints
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
General
1 -
Getting Started
1 -
IBM watsonx
1 -
Integration & Connectivity
10 -
Introduction
1 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
13 -
Restful webservices Using POST MAN
1 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
text editor
1 -
Tools
17 -
User Experience
5
Top kudoed authors
| User | Count |
|---|---|
| 5 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 |