Just recently, I got dragged - yet again - into a debate on whether data warehousing is out-dated or not. I tried to boil it down to one amongst many problems that data warehousing solves. As that helped to direct the discussion into a constructive and less ideological debate, I've put it into this short blog.
The problem is trivial and very old: as you need data from multiple sources why not accessing the data directly in those sources whenever needed! That guarantees real-time. Let's assume that the sources are powerful, network bandwidths at the top of technology and overall query performance be excellent. So: why not? In fact, this is absolutely valid but there is one more thing to consider, namely that all sources to be accessed need to be available. What is the mathematical probability for that? Even small analytic systems (aka data marts) access 30, 40, 50 data sources. For bigger data warehouses this goes to the 100s. That does not mean that every query accesses all those sources but naturally a significantly smaller subset. However, from an admin perspective it is clearly not viable to continuously translate source availability to query availability. One must assume that end users would want to access all sources continuously as it is required.
Figure 1 pictures 3 graphs that show the probability of all sources (= all data) being available, depending on the average availability of a source. For the latter 99%, 98% and 95% were considered to cater for planned and unplanned downtimes, network and other infrastructure failures. Even if a service-level agreement (SLA) of 80% availability (see dotted line) is assumed, it becomes obvious that such an SLA can be achieved only for a modest number of sources. N.b. that this applies even when data is synchronously replicated into an RDBMS because replication will obviously fail if the source is down or not accessible.
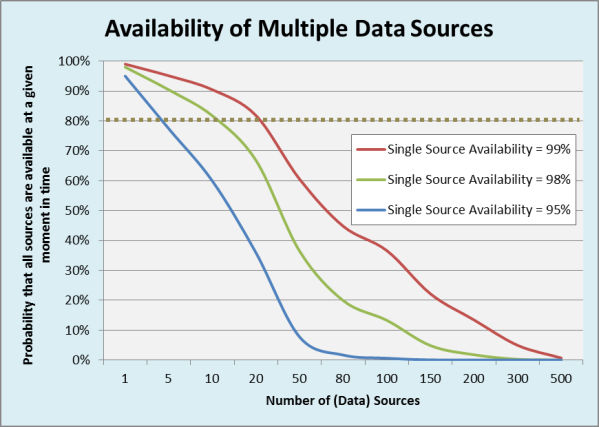
Fig. 1: Probability that all (data) sources are available given an average availability for a single source.
In a data warehouse (DW), this problem is addressed by regularly and asynchronously copying (extracting) data from the source into the DW. This is a controlled, managed and monitored process that can be made transparent to the admin of a source system who can then cater for downtimes or any other non-availability of his system. As such, a big problem for one admin - i.e. availability of allsources - is broken down to smaller chunks that can be managed in a simpler, de-central way. Once, the data is in the DW, it is available independent from planned / unplanned downtimes or network failures of the source systems.
Please do not read this blog as a counter argument to federation. No, I simply intend to create awareness for an instance that is solved by a data warehouse and that must not be under-estimated or neglected.
This blog has been cross-published here. You can follow me on Twitter under @tfxz.

