FUZZY SEARCH不仅可以针对单列进行搜索,而且可以同时针对多列进行搜索。首先创建表companies并插入一些数据:
CREATE COLUMN TABLE companies
(
id INTEGER PRIMARY KEY,
companyname SHORTTEXT(200) FUZZY SEARCH INDEX ON,
contact SHORTTEXT(100) FUZZY SEARCH INDEX ON
);
INSERT INTO companies VALUES (1, 'SAP Corp', 'Mister Master');
INSERT INTO companies VALUES (2, 'SAP in Walldorf Corp', 'Master Mister');
INSERT INTO companies VALUES (3, 'ASAP', 'Nister Naster');
INSERT INTO companies VALUES (4, 'ASAP Corp', 'Mixter Maxter');
INSERT INTO companies VALUES (5, 'BSAP orp', 'Imster Marter');
INSERT INTO companies VALUES (6, 'IBM Corp', 'M. Master');
接着我们进行如下的多列搜索:
SELECT SCORE() AS score, * FROM companies
WHERE CONTAINS(companyname, 'IBM',
FUZZY(0.7,'textSearch=compare,bestMatchingTokenWeight=0.7'))
AND CONTAINS(contact, 'Master',
FUZZY(0.7,'textSearch=compare,bestMatchingTokenWeight=0.7'))
ORDER BY score DESC

该方式返回的分数值两列分数值得平均值。我们也可以采用如下自由搜索方式:
SELECT SCORE() AS score, * FROM companies
WHERE CONTAINS((companyname,contact), 'IBM Master', FUZZY(0.7))
ORDER BY score DESC;
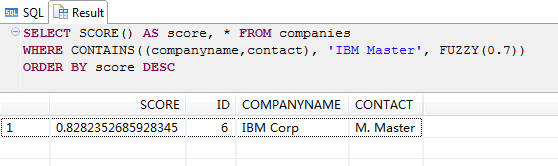
我们可以看出上述两种搜索结果的分数值不同;这是因为自由搜索方式通常使用TF/IDF来计算分数值,而不支持像'textSearch=compare'和'bestMatchingTokenWeight=0.7'等参数。
similarCalculationMode
similarCalculationMode用来控制怎样计算两个字符串的相似度。通常两个字符串的相似度通过计算在搜索字符串中错误字符、多余字符的个数以及在表中记录多余字符的个数而得到。因此FUZZY SEARCH支持如下计算模式:
模式 | 错误字符(影响因子) | 搜索字符多余字符 | 原字符多余字符 |
search | 高 | 高 | 低 |
compare | 中 | 高 | 高 |
symmetricsearch | 高 | 中 | 中 |
substringsearch | 高 | 高 | 低 |
例如:
TRUNCATE TABLE "TEST"."SEARCH_TEXT";
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('HANAGEEK');
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('HANAGEEKER');
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('HANAGEK');
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('HANAGAEK');
我们使用compare模式搜索:
SELECT SCORE() AS SCORE,*
FROM "TEST"."SEARCH_TEXT"
WHERE CONTAINS(CONTENT,'HANAGEEK',FUZZY(0.5,'similarCalculationMode=compare'))
ORDER BY SCORE DESC;

我们再使用search模式进行搜索,结果如下所示:
SELECT SCORE() AS SCORE,*
FROM "TEST"."SEARCH_TEXT"
WHERE CONTAINS(CONTENT,'HANAGEEK',FUZZY(0.5,'similarCalculationMode=search'))
ORDER BY SCORE DESC;

通过对比我们可以看出差异,对于原字符串比搜索字符串多字符时,compare搜索模式比search搜索模式影响更大;而对于错误字符,search模式比compare模式影响更大。所以,如果我们希望搜索’SAP’而不是’SPA,我们就就应该使用search模式:
TRUNCATE TABLE "TEST"."SEARCH_TEXT";
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('SAP');
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('SAP HANA');
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('SPA');
Search模式
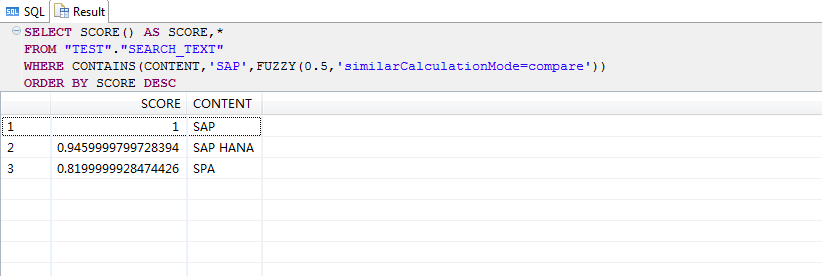
SELECT SCORE() AS SCORE,*
FROM "TEST"."SEARCH_TEXT"
WHERE CONTAINS(CONTENT,'SAP',FUZZY(0.5,'similarCalculationMode=search'))
ORDER BY SCORE DESC;

Compare模式
spellCheckFactor选项
该选项用于定义那些字符串不相等,但是FUZZY SCORE为1.0的分数。例如:单词Café和cafe得分为1.0,但是它们本身不相等。该选项主要由以下两种场景:
- 该选项容许你设置那些不相同但100%匹配的单词的分数值。例如单词'Café'和'cafe'。
- 可以设置那些不能被模糊匹配算法区分的单词,例如'abaca' and 'acaba'。
spellCheckFactor在String和TEXT上的效果是不同的,例如我们分别创建包含varchar类型和text类型的表SEARCH_TEXT_CHAR,SEARCH_TEXT并插入同样的数据Café和cafe:
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('Café');
INSERT INTO "TEST"."SEARCH_TEXT" VALUES('cafe');
INSERT INTO "TEST"."SEARCH_TEXT_CHAR" VALUES('Café');
INSERT INTO "TEST"."SEARCH_TEXT_CHAR" VALUES('cafe');
然后分别搜索如下所示:
SELECT SCORE() AS SCORE,*
FROM "TEST"."SEARCH_TEXT"
WHERE CONTAINS(CONTENT,'cafe',FUZZY(0.5))
ORDER BY SCORE DESC;

SELECT SCORE() AS SCORE,*
FROM "TEST"."SEARCH_TEXT_CHAR"
WHERE CONTAINS(CONTENT,'cafe',FUZZY(0.5))
ORDER BY SCORE DESC;

然后我们再用spellCheckFactor选项进行搜索:
SELECT SCORE() AS SCORE,*
FROM "TEST"."SEARCH_TEXT"
WHERE CONTAINS(CONTENT,'cafe',FUZZY(0.5,'spellCheckFactor=0.8'))
ORDER BY SCORE DESC;

SELECT SCORE() AS SCORE,*
FROM "TEST"."SEARCH_TEXT_CHAR"
WHERE CONTAINS(CONTENT,'cafe',FUZZY(0.5,'spellCheckFactor=0.8'))
ORDER BY SCORE DESC;
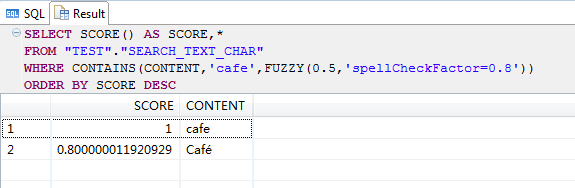
由此可见,场景1值对String有效,对text无效。之所以造成这种原因,是因为SAP HANA内部会进行字符标准化。但是如果我们又想区分它们该怎么办呢,这时spellCheckFactor就派上用场了。
interScriptMatching选项
该选项interScriptMatching=on用于通过拉丁字母匹配非拉丁字母或者相反。目前仅支持中文。当搜索字符时拉丁字符时,数据库中的非拉丁字符会被用拉丁拼音代替进行搜索。而搜索字符时非拉丁字符时,数据库中的拉丁字符会与输入字符的拉丁拼音进行匹配;而数据库中的非拉丁字符则与搜索原字符进行匹配。例如:
CREATE COLUMN TABLE interscript
(
str NVARCHAR(100) PRIMARY KEY
);
INSERT INTO interscript VALUES ('Shanghai');
INSERT INTO interscript VALUES ('上海');
INSERT INTO interscript VALUES ('Beijing');
INSERT INTO interscript VALUES ('北京');
INSERT INTO interscript VALUES ('背景');
不使用interScriptMatching进行搜索:
SELECT TO_DECIMAL(SCORE(),3,2), * FROM interscript WHERE CONTAINS(str, 'shanghai',
FUZZY(0.7)) ORDER BY SCORE() DESC;

使用interScriptMatching进行搜索:
SELECT TO_DECIMAL(SCORE(),3,2), * FROM interscript WHERE CONTAINS(str, 'shanghai',
FUZZY(0.7,'interScriptMatching=on')) ORDER BY SCORE() DESC

我们再搜索beijing,会发现北京和背景都会被搜出来:
SELECT TO_DECIMAL(SCORE(),3,2), * FROM interscript WHERE CONTAINS(str, 'beijing',
FUZZY(0.7,'interScriptMatching=on')) ORDER BY SCORE() DESC
![11.png]()
[本文的测试案例所使用的SAP HANA版本为SAP HANA SPS7 Revision 70.00。]
想获取更多SAP HANA学习资料或有任何疑问,请关注新浪微博@HANAGeek!我们欢迎你的加入!
转载本文章请注明作者和出处<文章url>,请勿用于任何商业用途。
