
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by Members
- OrgChart 4.1 Quick Search Syntax for Power Users
Enterprise Resource Planning Blogs by Members
Gain new perspectives and knowledge about enterprise resource planning in blog posts from community members. Share your own comments and ERP insights today!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
StephenMillard
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-03-2014
9:10 AM
![]()
Following on from the previous post, Quick Search Essentials, I’m going to take a look at some of the syntax that will allow you to construct more advanced queries and help you get the most out of SOVN OrgChart 4.1’s new Quick Search feature.
Search Operands
First of all let’s take a look at the basic search operation when using multiple terms.

Using two consecutive search terms can be seen to combine the terms as an “OR” since we have some results that contain both “anja” and “muller”, some that contain just “anja” and some that contain just “muller”.
So the obvious question becomes how could we restrict the search to results where both (/all) terms are present? Inserting the word “and” between the terms simply then returns results that also contain the letters “and” (note the inclusion of Andrea Radziwill below).

Wrapping the terms in double quotes also yields the same results, though oddly it does include null values for fields it wasn’t previously including … an edge case I’ve highlighted to Nakisa.

However I did have some success when I replaced the “and” with a double ampersand – “&&”.

So what if you want to exclude a search term? As you might expect from the results above, trying to use “NOT” simply included it as another search term. However if instead you prefix the term with an exclamation mark (“!”), then this will yield the desired result.

Forced Terms
As well as “AND”, “OR” and “NOT”, we also have options to force terms.
The first method is to force an exclusion which has the same effect as the exclamation mark above. To do this we use a hyphen (“-“).

Here the results set are employees whose information contains “anja” and never containing “muller”.
Things become more interesting however when we opt to force an inclusion. We can do so by using a plus (“+”).

Here the results set are employees whose information always contains “muller” and optionally contains “anja”. This isn’t the same as using “&&”. Using “&&” would force a mandatory inclusion of both terms either side of the “&&”, whereas using the “+” only makes one of the terms mandatory and the additional terms will be used for improving the ranking/ordering in the search results.
Double Quotes
In the previous use of search operands I used double quotes to try and highlight terms. Typically in search query terms double quotes are used to define a literal search string. For example if you were trying to return employees called “Jack Jones” and exclude “Jackie Jones”, you might simply try putting the your search into double quotes.
Sticking with “anja muller”, we would potentially expect the following double quoted search to yield at least one result…

… a curious result of no employees. However if we reverse the order of the search terms we have our single result (though the null field values have appeared again).

So this might suggest that the search is actually against [last name first name] rather than [first name last name]. However when I repeated this for Andrea Radziwill …


… both returned an identical result. I then tried truncating the last name and got the following.


I also tried capitalising the appropriate first letters of each name, but this made no difference.
Returning to Anja for a moment on what was admittedly a bit of a whim I tried repeating the searches using Müller rather than Muller. The results were curious to say the least.


This is the entirely opposite result to the Muller based searches.
So the only conclusion I could draw from this was that if searching for a name containing an accented character, the ordering of the names and the inclusion of the accented character will have a bearing on whether you get the result you are after returned in your list of results.
So the behaviour here is a little frustrating.
Fuzzy Matching
Quick search supports the use of a fuzzy matching operator – the tilde (“~”). This uses a string matching algorithm to try and identify similar words. The tilde is appended to the end of a search term to apply the fuzzy match.

Using muller as our base search term again, we can see results returned where single characters differ and where additional characters are included. So this has even more flexibility than the use of wild cards, but with more control of the matching given over to the matching algorithm.
The algorithm used does actually accept an additional parameter after the tilde or a numeric value between 0 and 1. As the number approaches zero it gets closer to an exact match. As the number moves away from one, the match gets looser. When the parameter isn’t specified it should be the mid-point (i.e. 0.5).


I tried varying the numeric value and the word I was searching on, but irrespective of the value I found that for anything other than zero, the result set was always the same. Since zero is in effect the same as searching with no tilde there seems to be no appreciable benefit to using the numeric parameter for quick search.
Note also that by using a fuzzy search, it is not ranking Anja Müller at the top. Changing the search to Müller~ made no difference. Once fuzzy matching is applied you do not rank an exact match higher than a fuzzy match. The ranking in fact appears consistent, but random in the sample sets of results I examined.
Searching Fields
The QuickSearchDisplayableFields.txt file in the SettingsResources directory lists the fields that Quick Search can display to the end user. These fields are also matched to the fields that can be searched as follows:
- SNAME = Employee Name.
- CITY = Location.
- EMAIL = E-mail.
- TELEPHONE = Telephone.
- CELL = Cell Phone.
- FAX = Fax.
We can specify a particular field to search by including it as an operator followed by a colon and then the term we wish to search for.
For example, I’d spotted an odd looking e-mail address whilst conducting some of my tests. The e-mail address didn’t seem to match up to the name. Using an e-mail address field search highlights this (note the Daniela Weiss result).

Note that the field name is entered in upper case (exactly as it is specified in QuickSearchDisplayableFields.txt). Entering it in lower case will not yield any results.
This becomes more useful when we want to specify something that could appear in multiple fields. For example a partial phone number that we want to distinguish from a cell/mobile phone or fax number, or where a city name could also be a person’s name.



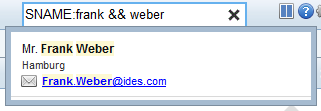
Multiple fields can be combined in a single search query, so we could create a search based on name and a mobile phone number for example.

Something interesting that I noted that around e-mail address searches was that searching for “EMAIL:*mull” yielded no results. However “EMAIL:*mull*” does return results. At first I had thought that the trailing wildcard was not being automatically added, but then I tried “EMAIL:*muller” and this did return results.
Having noted some IDES.COM domain e-mail addresses in the search results I then tried “EMAIL:*des” and “EMAIL:*des*”. This had the same sort of result and so this led me to think that the e-mail addresses are actually split into constituent parts by the search index based around the separator characters (“.” and “@”). So this is another thing to keep in mind for e-mail field searches.
Term Boosting
When you are carrying out a search, it is also possible to modify the weighting each term has. Within a search query, all terms are equal by default and are taken to have a weighting of 1. By appending a circumflex/hat (“^”) to the end of the term and assigning it a numeric value.
So for example a basic search for three terms (effectively “OR’d” together) yields a result set.

If we apply some weightings to the search terms to boost the second and third terms (the second higher than the third), we can see the order of the result set change to reflect the boost.

You can see a couple of interesting things form this. The first is that Anja Muller result has both the anja and frank terms present in its data and so is ranking higher than the Eunice Douglas result. So from this it could be that the matching to multiple terms gives it the edge over Eunice even though the eun term has a higher weighting.
i.e.
Matched 1 point term + Matched 2 point term > Matched 3 point term
… since it matches on multiple terms.
However I also noted that “2” and “3” were also highlighted in the Anja Muller result’s telephone number. This made me wonder if these were also being matched against.
i.e.
3 x (Matched 1 point term) + Matched 2 point term > Matched 3 point term
… since it would then be 5 points vs. 3 points.
Increasing the weighting of the second term however does shift Eunice Douglas to the top.


So increasing the weighting further can outweigh the multiple term matching.
Note also that by adding a fractional part to the weighting that it is no longer matched to the telephone number. This meant that I could rule out any possibility of the numeric values being used in the matching process. They were simply being picked up for highlighting in the result set.
Query Grouping
It is also possible to group query terms together to make sub queries using parentheses (“()”). For example if I wanted to carry out a fuzzy search for Muller and combine it with the results of a search for Frank Weber and to put the results for Frank Weber at the top I might create a search query like this.

Summary
I’ve produced a small crib table below to try and summarise some of the key points from this post and the Quick Search Essentials post.
| Area | Notes | Examples |
|---|---|---|
| Character Case | Search terms are case insensitive. | Anja = anja = AnJa = ANJA |
| Extended characters | Using accented characters in a search will return just results containing the accented character. Using unaccented characters in a search will also return results containing equivalent accented characters. | Müller vs. Muller |
Wild Card Mandatory Single Character | Use a question mark to take the place of exactly one character. | Mull?r |
Wild Card Optional Multiple Character | Use an asterisk to take the place of any number of characters (including zero). | M*er |
| OR | Place a space between the two search terms to be OR’d. | Anja Muller |
| AND | Place && between the two search terms to be AND’d. | Anja && Muller |
| NOT | Place an exclamation mark or a hyphen before the search term to be negated. | Anja !Mull or Anja -Mull |
| Forced Inclusion | Place a plus before the search term to be forced for inclusion. | Anja +Mull |
| Double Quotes | Binds multiple terms into one. However, variable quality of use and may be unreliable where extended characters are held as matching then can become dependent upon order of terms and use of accented vs. unaccented characters. | “Andrea Radziwill” |
| Fuzzy Match | Match terms that are the same as or similar to the one specified by appending a tilde. A numeric parameter can be applied but yielded no appreciable difference to the result set. | Muller~ |
| Search Fields | To search a specific field, prefix the search term with the name of the field in upper case and a colon. E-mail searches may benefit from delimiting the term with asterisks if it does not start a “part” of the e-mail address. | SNAME:frank CITY:frank EMAIL:anja TELEPHONE:01 CELL:01 FAX:01 |
| Term Boosting | Increase (or decrease) the weighting of a search term by appending a circumflex and numeric value against 1. The higher the value, the greater the weighting, the more strongly it will be pushed towards the first results in the result set. | Anja^0.5 Muller^10 |
| Query Grouping | Combine multiple queries into a single query by wrapping a sub query in parentheses. | (anja muller) (frank && weber)^2 |
Conclusion
SOVN OrgChart’s new Quick Search feature for live and hybrid architectures in my opinion is a fantastic new feature. As well as providing *quick* access to some people based searching it also offers a rich new set of search options that are simply not available in the standard Directory functionality.
The results sets may not always be perfect with null values for result set items creeping in here and there; but this doesn’t really detract from the functionality and I’m sure Nakisa will tighten this up in a future release.
I also hope that we might see this functionality extended into other applications and perhaps other types – similar searches for org units and positions are the most obvious candidates. The ability to easily customise the range of fields searched against and displayed would also be a good choice for Nakisa to apply some development time to. Being able to tailor the search functionality would probably allow the Directory Listing functionality to be replaced entirely … well except for exporting listings – that would be rather useful to retain!
I hope that you found this and the previous blog post useful and if you have any thoughts about the functionality or if you discover anything additional in this first or future versions of Quick Search please do consider leaving a comment and letting everyone know what you think/found.
- SAP Managed Tags:
- SAP ERP
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"mm02"
1 -
A_PurchaseOrderItem additional fields
1 -
ABAP
1 -
ABAP Extensibility
1 -
ACCOSTRATE
1 -
ACDOCP
1 -
Adding your country in SPRO - Project Administration
1 -
Advance Return Management
1 -
AI and RPA in SAP Upgrades
1 -
Approval Workflows
1 -
ARM
1 -
ASN
1 -
Asset Management
1 -
Associations in CDS Views
1 -
auditlog
1 -
Authorization
1 -
Availability date
1 -
Azure Center for SAP Solutions
1 -
AzureSentinel
2 -
Bank
1 -
BAPI_SALESORDER_CREATEFROMDAT2
1 -
BRF+
1 -
BRFPLUS
1 -
Bundled Cloud Services
1 -
business participation
1 -
Business Processes
1 -
CAPM
1 -
Carbon
1 -
Cental Finance
1 -
CFIN
1 -
CFIN Document Splitting
1 -
Cloud ALM
1 -
Cloud Integration
1 -
condition contract management
1 -
Connection - The default connection string cannot be used.
1 -
Custom Table Creation
1 -
Customer Screen in Production Order
1 -
Data Quality Management
1 -
Date required
1 -
Decisions
1 -
desafios4hana
1 -
Developing with SAP Integration Suite
1 -
Direct Outbound Delivery
1 -
DMOVE2S4
1 -
EAM
1 -
EDI
2 -
EDI 850
1 -
EDI 856
1 -
edocument
1 -
EHS Product Structure
1 -
Emergency Access Management
1 -
Energy
1 -
EPC
1 -
Financial Operations
1 -
Find
1 -
FINSSKF
1 -
Fiori
1 -
Flexible Workflow
1 -
Gas
1 -
Gen AI enabled SAP Upgrades
1 -
General
1 -
generate_xlsx_file
1 -
Getting Started
1 -
HomogeneousDMO
1 -
IDOC
2 -
Integration
1 -
Learning Content
2 -
LogicApps
2 -
low touchproject
1 -
Maintenance
1 -
management
1 -
Material creation
1 -
Material Management
1 -
MD04
1 -
MD61
1 -
methodology
1 -
Microsoft
2 -
MicrosoftSentinel
2 -
Migration
1 -
MRP
1 -
MS Teams
2 -
MT940
1 -
Newcomer
1 -
Notifications
1 -
Oil
1 -
open connectors
1 -
Order Change Log
1 -
ORDERS
2 -
OSS Note 390635
1 -
outbound delivery
1 -
outsourcing
1 -
PCE
1 -
Permit to Work
1 -
PIR Consumption Mode
1 -
PIR's
1 -
PIRs
1 -
PIRs Consumption
1 -
PIRs Reduction
1 -
Plan Independent Requirement
1 -
Premium Plus
1 -
pricing
1 -
Primavera P6
1 -
Process Excellence
1 -
Process Management
1 -
Process Order Change Log
1 -
Process purchase requisitions
1 -
Product Information
1 -
Production Order Change Log
1 -
Purchase requisition
1 -
Purchasing Lead Time
1 -
Redwood for SAP Job execution Setup
1 -
RISE with SAP
1 -
RisewithSAP
1 -
Rizing
1 -
S4 Cost Center Planning
1 -
S4 HANA
1 -
S4HANA
3 -
Sales and Distribution
1 -
Sales Commission
1 -
sales order
1 -
SAP
2 -
SAP Best Practices
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Cloud ALM
1 -
SAP Data Quality Management
1 -
SAP Maintenance resource scheduling
2 -
SAP Note 390635
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud private edition
1 -
SAP Upgrade Automation
1 -
SAP WCM
1 -
SAP Work Clearance Management
1 -
Schedule Agreement
1 -
SDM
1 -
security
2 -
Settlement Management
1 -
soar
2 -
SSIS
1 -
SU01
1 -
SUM2.0SP17
1 -
SUMDMO
1 -
Teams
2 -
User Administration
1 -
User Participation
1 -
Utilities
1 -
va01
1 -
vendor
1 -
vl01n
1 -
vl02n
1 -
WCM
1 -
X12 850
1 -
xlsx_file_abap
1 -
YTD|MTD|QTD in CDs views using Date Function
1
- « Previous
- Next »
Related Content
- Customize the ABAP Editor Theme in SAP NetWeaver in Enterprise Resource Planning Blogs by Members
- ABAP Platform for SAP S/4HANA 2023 in Enterprise Resource Planning Blogs by SAP
- Invoice Entry without Purchase Order with flexible workflow for supplier invoice in SAP S/4HANA On premise 2021 in Enterprise Resource Planning Blogs by Members
- Why and How to adopt ABAP Custom code on HANA Database? in Enterprise Resource Planning Blogs by Members
- Syntax Error Formatted Search Delivery Order in Enterprise Resource Planning Q&A
Top kudoed authors
| User | Count |
|---|---|
| 5 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 |