
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- SAP HANA SQL 函数简介及使用(2)
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-02-2014
8:45 AM
上一篇博客我们介绍了SAP HANA 提供的4类SQL函数:1.数据类型转换函数 2.日期函数 3.全文函数 4.数值处理函数。这一篇博客里我们接着介绍剩下的3类函数:1.字符串函数 2.窗口函数 3.杂项函数。本文的测试案例所使用的SAP HANA版本为SAP HANA SPS7 Revision 70.00。
1.字符串函数
SAP HANA 提供了数量众多的字符串函数以方便用户,包括
ASCII BINTOSTR CHAR CONCAT LCASE LEFT LENGTH LOCATE LOWER LPAD LTRIM NCHAR REPLACE RIGHT RPAD RTRIM STRTOBIN SUBSTR_AFTER SUBSTR_BEFORE SUBSTRING TRIM UCASE UNICODE UPPER |
其中有些函数我们在MySQL里也见过,有些看名字就知道是做什么用的及如何使用,比如CONCAT用于字符串连接,LENGTH返回一个字符串的长度,UPPER将字符串转换为大写,TRIM去掉字符串两边的空白字符,LTRIM只去掉左边的空白字符,RTRIM只去掉右边的空白字符等,LCASE将字符串转换为小写,等等。我们只介绍值得注意的字符串函数。
ASCII函数返回一个ASCII字符串的首字母的ASCII码值。

BINTOSTR返回VARBINARY类型的字符串对应的字符串。注意这个函数在SAP HANA SP6不支持。

相反地有STRTOBIN函数,STRTOBIN (str, codepage)将字符串中所有字符转换为codepage对应的编码表示。

CHAR (n) 将ASCII值转变为对应的字符。和CHAR类似,NCHAR是一个更通用的函数,NCHAR(n)返回整数n对应的unicode字符。
LEFT (str, n)返回字符串str左边开始的n个字符的子串。RIGHT(str, n)和此类似。

LOCATE (haystack, needle) 返回字符串needle在haystack的出现位置,注意下标位置从1而非从0开始,0用于表示未找到的返回值。
LPAD (str, n [, pattern]) 有一个可选参数,如果未提供,则用空格填充字符串str的左边,否则循环使用pattern填充,直到整个字符串的长度为n。


RPAD和LAPD类似,只是方向相反。
LTRIM(str [, remove_set]) 有个可选参数remove_set,若未指定,则删除字符串左边的前导空格,直到遇到非空格位置;若指定remove_set,则从左边开始一直删除字符串中在remove_set的字符直到一个不在remove_set中的字符终止。

SUBSTR_AFTER (str, pattern) 返回pattern出现之后的str子串。如果没有找到,返回空串。如果pattern为空,返回str。如果pattern为NULL,返回NULL。

SUBSTR_BEFORE (str, pattern)功能与此类似。
其它函数请参考SAP HANA SQL and System View Reference文档。
2. 窗口函数
窗口函数使得用户能够将查询的结果集分成由不同行构成的组,这样的划分被称为窗口划分,窗口函数由此得名。窗口划分在OVER子句中通过一个或多个表达式指定。
其中包括
RANK DENSE_RANK ROW_NUMBER PEERCENT_RANK CUME_DIST LEAD LAG NTILE FIRST_VALUE LAST_VALUE NTH_VALUE |
为了示例其用法,我们先建一个表T,其中包括class、val和offset三个字段。
create table T (class char(10), val int, offset int); insert into T values('A', 1, 1); insert into T values('A', 3, 3); insert into T values('A', 5, null); insert into T values('A', 5, 2); insert into T values('A', 10, 0); insert into T values('B', 1, 3); insert into T values('B', 1, 1); insert into T values('B', 7, 1); |
然后我们使用ROW_NUMBER和RANK函数。其中RANK函数返回一个一行在其划分中的排序,从1开始,ROW_NUMBER返回某行在划分中的行号,也从1开始。
select class, val, ROW_NUMBER() over (partition by class order by val) as row_num, RANK() over (partition by class order by val) as rank, DENSE_RANK() over (partition by class order by val) as dense_rank from T; |
比如以上查询,按class值划分,不同的class在不同分组中,分组中的行按val排序,所以CLASS为A,VAL为1的行排在分组中第一,因此ROW_NUM和RANK都是1,VAL相同的RANK相同,但是ROW_NUMBER不同。

另一个例子,SQL如下,查询结果如下图所示。
select class, val, offset, COUNT(*) over (partition by class) as c1, COUNT(offset) over (partition by class) as c2, COUNT(*) over (partition by class order by val) as c3, COUNT(offset) over (partition by class order by val) as c4, MAX(val) over (partition by class) as m1, MAX(val) over (partition by class order by val) as m2 from T; |
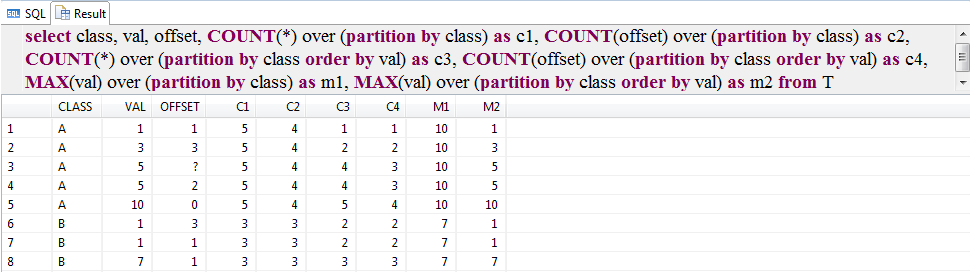
关于其他函数的使用请参考SAP HANA SQL and System View Reference。
3.杂项函数
包含了一些没法分在其它类别的实用函数,包括
COALESCE CONVERT_CURRENCY CURRENT_CONNECTION CURRENT_SCHEMA CURRENT_TRANSACTION_ISOLATION_LEVEL CURRENT_USER GREATEST GROUPING GROUPING_ID HASH_SHA256 IFNULL LEAST MAP NULLIF SESSION_CONTEXT SESSION_USER SYSUUID |
其中有几个和判断参数是否和NULL有关,如
COALESCE (expression_list) 返回expression_list中首个非NULL的结果,如果都是NULL则返回NULL。

IFNULL (exp1, exp2)返回exp1和exp2中的非NULL值。如果exp1非NULL,返回exp1;否则如果exp2非NULL,返回exp2;否则返回NULL。
NULLIF (exp1, exp2)比较exp1是否和exp2相等,若相等则返回NULL,否则返回exp1。
另有几个和当前连接信息有关的函数。
CURRENT_CONNECTION 返回当前连接的ID。
CURRENT_SCHEMA 返回当前的SCHEMA名称,注意,调用的时候不需要加括号,以下CURRENT_TRANSACTION_ISOLATION_LEVEL和CURRENT_USER也是如此。CURRENT_TRANSACTION_ISOLATION_LEVEL 返回当前的事物隔离级别,如READ COMMITTED等。CURRENT_USER 返回登录的当前用户名。
GREATEST返回几个数或者字符串中的最大值,字符串按字典序比较,参数个数可变。

LEAST类似GREAEST,不过返回几个数或者字符串中的最小值。
GROUPING(column) 用于判断指定column是否用于grouping
HASH_SHA256 (<argument> [{, <argument>}...]) 可用于计算一个字符串的哈希码,或者计算几个字符串合起来的哈希码。
MAP (<exp>, <exp1>, <r1> [{, <exp2>, <r2>}...] [, default]) 类似SQL中的CASE WHEN结构,如果exp的值等于exp1,返回r1,如果和exp2相等,返回r2,…,否则返回default。如果没有指定default,则返回NULL。

SESSION_CONTEXT(session_variable) 返回由session_variable指定的会话变量对应的会话值。会话变量既可以是预定义的也可以是用户定义的。定义会话变量可通过SET SESSION <variable_name>=<value>。
SESSION_USER返回当前会话的用户名。

SYSUUID返回一个全局唯一标识符,可用于生成唯一键。
在这一篇日志里,我们介绍了SAP HANA的SQL函数里的字符串处理函数、窗口函数、杂项函数。至此,我们关于SAP HANA的SQL函数的介绍就全部结束了,如果对于细节还有不清楚的,可以参考SAP HANA SQL and System View Reference文档。
想获取更多SAP HANA学习资料或有任何疑问,请关注新浪微博@HANAGeek!我们欢迎你的加入!
转载本文章请注明作者和出处http://scn.sap.com/community/chinese/hana/blog/2014/04/02/sap-hana-sql-%E5%87%BD%E6%95%B0%E7%AE%80%E...,请勿用于任何商业用途。
- SAP Managed Tags:
- SAP HANA
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
1 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
learning content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
2 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Python RAG sample for beginners using SAP HANA Cloud and SAP AI Core in Technology Blogs by SAP
- What is the preferred way of data fetch from HANA view in ABAP Program in Technology Q&A
- NCO 2.0 and UNICODE compatibility in Technology Q&A
- How to send email in SAP S/4 HANA Cloud public on creation of Purchase order to approve in Technology Q&A
- Behind the compatibility - What are the compatibility means between GRC and the plugins in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 11 | |
| 7 | |
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 |