Blog posts are a great way for SAP, customers, and partners to share advice, insights into career trends, new opportunities, and personal success stories.
So we had D-Code in Bangalore recently. By its very inherent nature of being informative and a cornucopia of knowledge, D-Code Bangalore summed up being a podium of complete entertainment. I will share my experience during participation in the D-Code hackathon challenge.
EDIT:: I won the first runner-up award for the submission.
SAP D-Code What The Hack Challenges
I was strongly inclined towards challenge #2. There was a provision for showcasing the demo for the hackathon just two days later. So, I had two days to build something up. TWO DAYS….
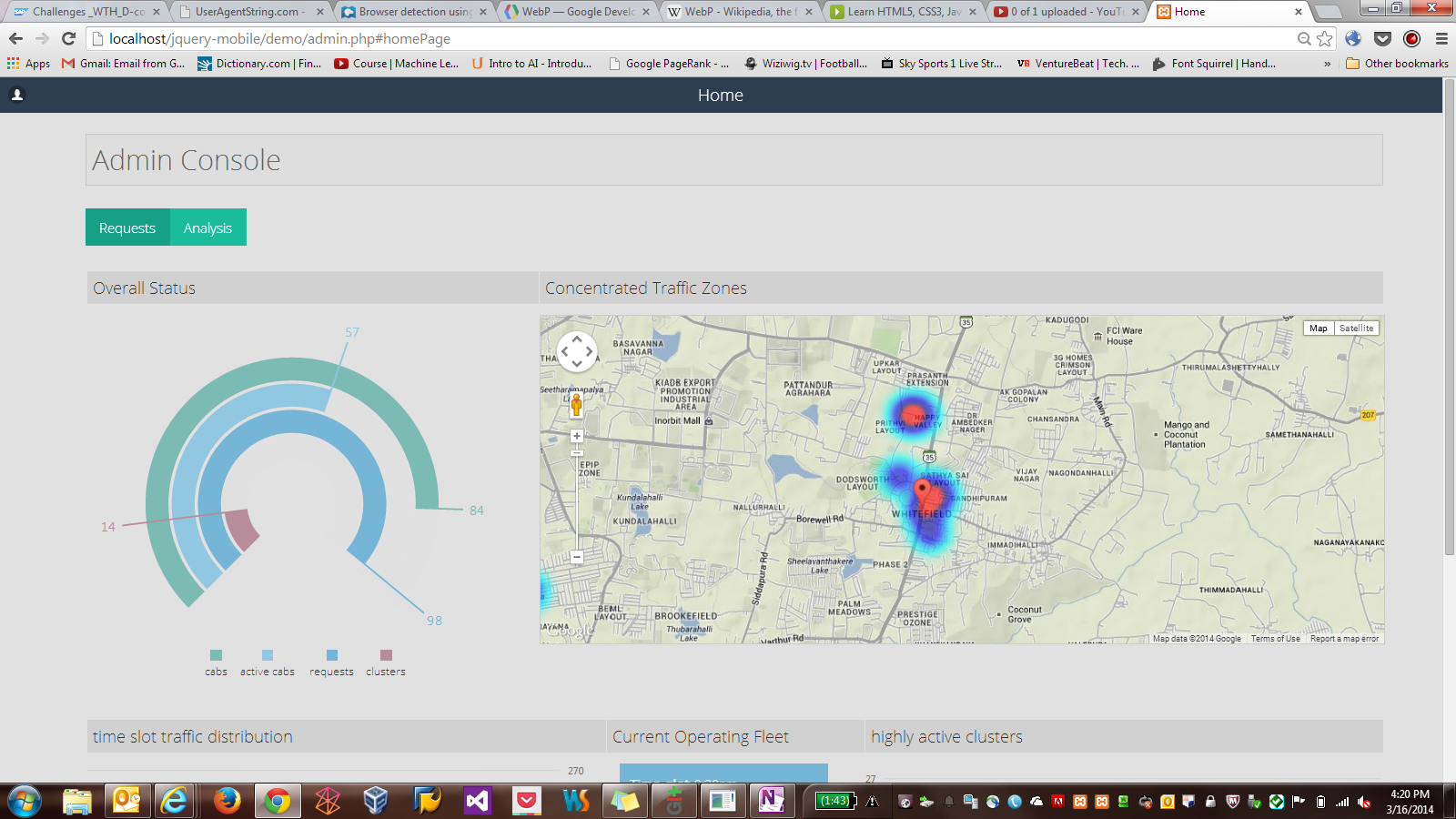
The Final App
Okay, lets go back to square one and prepare the set of requirements:
1. Mobile app for employees for raising requests
2. Desktop app for admin for consolidating the requests
3. Route optimization
4. Analytics and charts
5. Performance
Mobile App
I am a web developer, so it's going to be a web app. I love developing for mobile. I am quite well versed with jQuery Mobile (jQM) (and a couple of frameworks) and hence instantly it was my choice. It being a CSS3 and JavaScript framework takes away a lot of pain from the developers related to design. So jQM decorated with Flat UI theme is what I need.
Desktop App
jQM is a CSS3 and JavaScript framework which ALSO works magnificently on mobile devices. Hence, building a desktop app using jQM was not something to be circumspect about. So, both of the (web) apps (employee and admin) were going to be built using jQM.
The Technology Stack
1. Front end - jQM
2. Server - Node.js
3. Database - MongoDb
Route Optimization and consolidation
Now this is a big problem. I think that manual consolidation was the cause behind non-optimized routes. Real time traffic or blockades are contingencies which we are not looking at right now. I decided to focus on automated consolidation.
So, employees could raise requests for availing the service with departure time set to either 9:30pm, 10:30 pm or 11:30pm. Then the admin gets the list of requests. Now, the process of automation should first group the requests based on their time slot and then club them in an efficient way and let the admin allot cabs to each group. I also thought it would be good if the admin also had control over the groups formation. Clustering was what I needed to implement.
Request List
Process
1. Grouping/clustering will depend on proximity of the destination drop points.
2. Geocodedestination addresses to get <lat, lng> vectors :: I used Google's API for client side geocoding
3. Haversine formula to compute distance between two <lat, lng> pair :: this link helped me
4. k-Means to cluster the destination points :: thanks to the data mining graduation course I took :smile:
I asked a couple of my colleagues who are regular consumers of this service. They provided some insights about the approximate volume of requests per time slot (which turned out to be ~ 120-140). Okay that's not a big number. I was wondering if I could try out pushing the cluster computation to the client. The number suggested me that I could.
k-Means in the browser
The admin console would be average at read/writes. So, from performance POV, I thought it’s a nice use case for testing multi-threading environment in the browser. Web Workers !
The k-Means implementation runs in a worker thread and the main app is completely hassle free. It computes the clusters and communicates the same to the main app thread.
Okay, now I had the clusters. I had to call them something, right? Best way I thought was to find the centroid of each cluster (which is a <lat, lng> pair) and reverse geocode it to find the address of the centroid. So, my clusters looked like:
Admin control:
Now, to implement admin enhanced control, I thought of letting the admin transfer employees from one cluster to another. For e.g., the "Brookfield, Bangalore" cluster and the "Whitefield, Bangalore" cluster are not that far (even though the containing points are not in the same cluster). So, the admin could transfer the employee under the latter cluster to the former (drag and drop html5 API).
The "select a cab" allows the admin to manually allot (multiple) cabs to the cluster.
Notification:
The NOTIFY button on each cluster will send email notification to all employees contained. I used nodemailer node module for achieving this. The notification mail contains the departure time and the taxi number allotted to the user.
Analytics and Charts
The analytics include:
1. Monitoring traffic/request volume for each time slot.
2. Monitoring the active clusters.
Performance
1. Text and data compression was enabled at the node.js server to send fewer bytes on the wire.
2. The app is not image heavy which makes it light weight. Conditional usage of WebP image format (if user-agent is Chrome) helps send 26% smaller lossless images.
3. At the db layer, the final information stored contains an assorted document containing clusters, the employees within them and the cabs allotted to them. This justifies the usage of Mongodb over MySQL making it conducive for lesser aggregation queries and better response time.
4. The fact that there are at most ~120-140 employees per time slot, the decision of pushing clustering to the client reduces server round trips.
5. Taking advantage of multi-threading capabilities using HTML5 Web Workers API, the performance of the main thread is not compromised.
So, overall a wonderful experience. It also served as a theoretical computer science refresher for me. Looking forward to listening from your side !!