
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA中PAL算法使用入门
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-10-2014
3:19 AM
1 应用场合
SAP HANA作为一款内存数据库产品, 使得数据常驻内存, 物理磁盘的存储作为数据备份与日志记录, 以防断电内存中数据丢失. 这种构架大大的缩短了数据存取的时间, 使得SAP HANA很”高速”.
在传统数据模型中,数据库只是作为存取数据一个工具,对于类似下图所示的应用, 客户端从Database获取数据,然后计算,最后再把结果写回Database, 如果数据量过大, 数据传输的开销过大,并且如果客户端的内存不够, 计算分析的过程也将非常缓慢.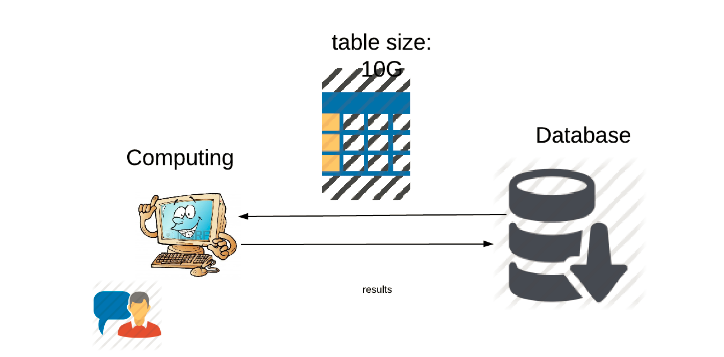
借助于大内存的优势, SAP HANA的解决方案是把数据敏感的相关计算逻辑都移动到SAP HANA内, 从而省去了数据传输的开销. 典型的框架如下:

对于一些简单的计算分析, 可以利用SQLScript脚本完成, SQLScript提供了基本的变量定义语句,流程控制语句. 但是对于复杂的分析与计算, 单纯使用SQLScript可能不是特别方便, 比如对1T的数据表作聚类分析. 为此 ,SAP HANA提供 AFL (Application Function Library) , 把一些常见的分析任务用C++实现,作为库函数的形式, 提供给SQLScript调用,极大地丰富了SQLScript的功能.
2 PAL简介
PAL (Predictive Analysis Library)是SAP HANA中AFL (Application Function Library)框架下的一个函数库, 主要用于数据预测与分析, 提供了很多数据挖掘算法的实现. 按应用的场景进行分类,PAL函数主要包括以下类别:
Ø 聚类
Ø 分类
Ø 关联分析
Ø 时间序列分析
Ø 数据预处理
Ø 统计分析
Ø 社会网络分析
具体到每个类别下面, 有常见算法的实现, 比如聚类下面的K-means算法.
值得一提的是, AFL是一个单独的包, 需要另外进行安装. 另外AFL 的版本号需要与SAP HANA的版本号匹配.
3 基本使用步骤
PAL函数的使用包括三个步骤:
(1) 生成AFL_WRAPPER_GENERATOR 与 AFL_WRAPPER_ERASER存储过程.
对于具体的某个算法, 在使用之前,利用AFL_WRAPPER_GENERATOR生成该算法的一个包装器,然后才能进行调用, 可以理解为生成该算法的一个实例, AFL_WRAPPER_ERASER作用是删除这个算法的实例.
这两个存储过程的生成很简单. 在AFL插件的目录下有afl_wrapper_generator.sql, afl_wrapper_eraser.sql两个脚文文件, 把它们的内容拷贝到SAP HANA Studio的SQL Console,然后执行以及即可.然后为用户分配执行权限:
GRANT EXECUTE ON system.afl_wrapper_generator to USER1;
GRANT EXECUTE ON system.afl_wrapper_eraser to USER1;
这个步骤只需要首次利用使用AFL时执行一次,对于后续其他的算法使用,就不需要执行了.
(2) 生成算法的实例
CALL SYSTEM.AFL_WRAPPER_GENERATOR(
'<procedure_name>',
'<area_name>',
'<function_name>', <signature_table>);
Procedure_name:自定义的名称;
Area_name:通常为AFLPAL;
Function_name:算法名称;
Signature_table:指定一个用户表,作为方法签名的信息;
(3) 调用算法实例
CALL <procedure_name>(
<data_input_table> {,…},
<parameter_table>,
<output_table> {,…}) with overview;
Procedure_name:算法实例名;
Data_input_table:输入数据表;
Parameter_table:参数表;
Output_table:输出表;
4 示例Demo
下面以DBSCAN聚类算法来说明说PAL算法的调用过程.(因测试机AFL_WRAPPER_GENERATOR存储过程已经存在,故第一步不再执行,另假定Schema为TEST)
DBSCAN聚类算法是一个基于密度的聚类算法,该算法有很好的降噪能力,有关该算法的更多介绍,请参考http://en.wikipedia.org/wiki/DBSCAN
/*创建数据表类型 ,id,属性1,属性2 */
CREATE TYPE PAL_DBSCAN_DATA_T AS TABLE ( ID integer, ATTRIB1 double, ATTRIB2
double);
/*创建算法控制参数类型*/
CREATE TYPE PAL_CONTROL_T AS TABLE( NAME varchar(50), INTARGS integer, DOUBLEARGS
double, STRINGARGS varchar(100));
/*结构表类型,ID,类簇编号*/
CREATE TYPE PAL_DBSCAN_RESULTS_T AS TABLE( ID integer, RESULT integer);
/*创建方法参数表*/
CREATE COLUMN TABLE PAL_DBSCAN_PDATA_TBL( "ID" INT, "TYPENAME" VARCHAR(100), "DIRECTION" VARCHAR(100) );
/*向参数表中插入相关参数数据*/
INSERT INTO PAL_DBSCAN_PDATA_TBL VALUES (1, 'TEST.PAL_DBSCAN_DATA_T', 'in');
INSERT INTO PAL_DBSCAN_PDATA_TBL VALUES (2, 'TEST.PAL_CONTROL_T', 'in');
INSERT INTO PAL_DBSCAN_PDATA_TBL VALUES (3, 'TEST.PAL_DBSCAN_RESULTS_T', 'out');
/*分配权限*/
GRANT SELECT ON DM_PAL.PAL_DBSCAN_PDATA_TBL to SYSTEM;
/*生成PAL_DBSCAN9算法实例*/
call SYSTEM.afl_wrapper_eraser('PAL_DBSCAN9');
call SYSTEM.afl_wrapper_generator('PAL_DBSCAN9', 'AFLPAL', 'DBSCAN', PAL_DBSCAN_PDATA_TBL);
/* 创建数据表*/
CREATE COLUMN TABLE PAL_DBSCAN_DATA_TBL ( ID integer, ATTRIB1 double, ATTRIB2 double);
/*插入测试数据*/
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(1,0.10,0.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(2,0.11,0.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(3,0.10,0.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(4,0.11,0.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(5,0.12,0.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(6,0.11,0.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(7,0.12,0.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(8,0.12,0.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(9,0.13,0.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(10,0.13,0.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(11,0.13,0.14);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(12,0.14,0.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(13,10.10,10.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(14,10.11,10.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(15,10.10,10.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(16,10.11,10.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(17,10.11,10.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(18,10.12,10.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(19,10.12,10.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(20,10.12,10.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(21,10.13,10.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(22,10.13,10.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(23,10.13,10.14);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(24,10.14,10.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(25,4.10,4.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(26,7.11,7.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(27,-3.10,-3.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(28,16.11,16.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(29,20.11,20.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(30,15.12,15.11);
/*用临时表来存储算法的输入参数*/
CREATE LOCAL TEMPORARY COLUMN TABLE #PAL_CONTROL_TBL( NAME varchar(50), INTARGS
integer, DOUBLEARGS double, STRINGARGS varchar(100));
/*指定DBSCAN算法的输入参数*/
/*线程数18*/
INSERT INTO #PAL_CONTROL_TBL VALUES('THREAD_NUMBER',18,null,null);
/*自动确定MINPTS与RADIUS参数*/
INSERT INTO #PAL_CONTROL_TBL VALUES('AUTO_PARAM',null,null,'true');
/*点与点之间的距离采用Manhattan距离*/
INSERT INTO #PAL_CONTROL_TBL VALUES('DISTANCE_METHOD',1,null,null);
/*结果表*/
CREATE COLUMN TABLE PAL_DBSCAN_RESULTS_TBL( ID integer, RESULT integer);
/*调用DBSCAN算法*/
CALL _SYS_AFL.PAL_DBSCAN9(PAL_DBSCAN_DATA_TBL, "#PAL_CONTROL_TBL",
PAL_DBSCAN_RESULTS_TBL) with overview;
/*查看结果*/
SELECT * FROM PAL_DBSCAN_RESULTS_TBL;
/*创建数据表类型 ,id,属性1,属性2 */
CREATE TYPE PAL_DBSCAN_DATA_T AS TABLE ( ID integer, ATTRIB1 double, ATTRIB2
double);
/*创建算法控制参数类型*/
CREATE TYPE PAL_CONTROL_T AS TABLE( NAME varchar(50), INTARGS integer, DOUBLEARGS
double, STRINGARGS varchar(100));
/*结构表类型,ID,类簇编号*/
CREATE TYPE PAL_DBSCAN_RESULTS_T AS TABLE( ID integer, RESULT integer);
/*创建方法参数表*/
CREATE COLUMN TABLE PAL_DBSCAN_PDATA_TBL( "ID" INT, "TYPENAME" VARCHAR(100), "DIRECTION" VARCHAR(100) );
/*向参数表中插入相关参数数据*/
INSERT INTO PAL_DBSCAN_PDATA_TBL VALUES (1, 'TEST.PAL_DBSCAN_DATA_T', 'in');
INSERT INTO PAL_DBSCAN_PDATA_TBL VALUES (2, 'TEST.PAL_CONTROL_T', 'in');
INSERT INTO PAL_DBSCAN_PDATA_TBL VALUES (3, 'TEST.PAL_DBSCAN_RESULTS_T', 'out');
/*分配权限*/
GRANT SELECT ON DM_PAL.PAL_DBSCAN_PDATA_TBL to SYSTEM;
/*生成PAL_DBSCAN9算法实例*/
call SYSTEM.afl_wrapper_eraser('PAL_DBSCAN9');
call SYSTEM.afl_wrapper_generator('PAL_DBSCAN9', 'AFLPAL', 'DBSCAN', PAL_DBSCAN_PDATA_TBL);
/* 创建数据表*/
CREATE COLUMN TABLE PAL_DBSCAN_DATA_TBL ( ID integer, ATTRIB1 double, ATTRIB2 double);
/*插入测试数据*/
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(1,0.10,0.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(2,0.11,0.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(3,0.10,0.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(4,0.11,0.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(5,0.12,0.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(6,0.11,0.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(7,0.12,0.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(8,0.12,0.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(9,0.13,0.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(10,0.13,0.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(11,0.13,0.14);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(12,0.14,0.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(13,10.10,10.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(14,10.11,10.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(15,10.10,10.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(16,10.11,10.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(17,10.11,10.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(18,10.12,10.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(19,10.12,10.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(20,10.12,10.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(21,10.13,10.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(22,10.13,10.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(23,10.13,10.14);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(24,10.14,10.13);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(25,4.10,4.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(26,7.11,7.10);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(27,-3.10,-3.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(28,16.11,16.11);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(29,20.11,20.12);
INSERT INTO PAL_DBSCAN_DATA_TBL VALUES(30,15.12,15.11);
/*用临时表来存储算法的输入参数*/
CREATE LOCAL TEMPORARY COLUMN TABLE #PAL_CONTROL_TBL( NAME varchar(50), INTARGS
integer, DOUBLEARGS double, STRINGARGS varchar(100));
/*指定DBSCAN算法的输入参数*/
/*线程数18*/
INSERT INTO #PAL_CONTROL_TBL VALUES('THREAD_NUMBER',18,null,null);
/*自动确定MINPTS与RADIUS参数*/
INSERT INTO #PAL_CONTROL_TBL VALUES('AUTO_PARAM',null,null,'true');
/*点与点之间的距离采用Manhattan距离*/
INSERT INTO #PAL_CONTROL_TBL VALUES('DISTANCE_METHOD',1,null,null);
/*结果表*/
CREATE COLUMN TABLE PAL_DBSCAN_RESULTS_TBL( ID integer, RESULT integer);
/*调用DBSCAN算法*/
CALL _SYS_AFL.PAL_DBSCAN9(PAL_DBSCAN_DATA_TBL, "#PAL_CONTROL_TBL",
PAL_DBSCAN_RESULTS_TBL) with overview;
/*查看结果*/
SELECT * FROM PAL_DBSCAN_RESULTS_TBL;

如果执行无误,将看到如上图所示的结果,记录被聚成三类,0,1,-1各代表一个类簇.
5结束语
本文介绍了SAP HANA中PAL算法的使用,以DBSCAN聚类算法作为具体的实现例子.其他的相关算法使用流程上与上述流程都相似,主要的工作在于准备数据表,根据算法的接口文档定义相关的参数,并将参数存入参数表.最后调用算法实例即可.
从效率上讲,在SAP HANA中使用PAL,一方面利用了大内存的优势,另一方面利用了C++作为编译型语言本身的高效性,如果使用得当,对于大数据的相关分析任务,在速度上将会有一个很大的飞跃!
[注: 本文的测试案例所使用的SAP HANA版本为SAP HANA SPS06]
想获取更多SAP HANA学习资料或有任何疑问,请关注新浪微博@HANAGeek!我们欢迎你的加入!
- SAP Managed Tags:
- SAP HANA
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
345 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
425 -
Workload Fluctuations
1
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |