
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Data Services, Information Steward, and Master Dat...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member18
Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-06-2014
6:25 PM
The following recaps an ASUG webcast delivered by hemant.puranik, cchan, and lars.rueter. For more details, you can always attend an ASUG pre-conference session on Big Data or Information Governance.
Integration use cases
As we talk through the EIM wheel of Architect to Archive, we always mention that the tools are integrated in pretty darn cool ways. The next question is always How? This session will show how some of the key master data products are integrated: Data Services and Data Quality , SAP Information Steward and SAP Master Data Governance (called MDG from here on out).
The main use cases addressed are these:
- Data integration and provisioning
- Data remediation
- Validation and improvement
- Data monitoring and alerting
Information policies inform many of these areas, too.
Provisioning process
Use case: connect an additional system to your master data governance hub.

On the left are the source systems, and on the right is the master data hub. When doing so, you want to make sure only accurate and clean data is moving into the hub.
- Extract the master data from the business systems in flat files and then load these flat files into MDG without any changes.
- Use the Enterprise Service Bus to load data into MDG.
- Use SAP Migration Workbench to load data into MDG.
All of these options take the data as is, without any cleaning or transformation. You should clean, consolidate, and check against governance rules. To do this, you should use the Consolidation and Data Quality Services. Our suggestion is Information Steward to inspect the data, and then Data Services to cleanse the data.
If you already have data in your MDG hub, then you need to extract data from the hub before you can find duplicates, cleanse, and then re-load into the hub. This is shown by the Extractor Framework box on the right. The focus of this session, though, is the Consolidation framework.

Provisioning: Profile and assess quality

Here Information Steward is helping you understand your data, and then build the validation rules that can be used in Data Services and MDG.
Provisioning: Extract, cleanse, improve, and auto-merge records

Once in Data Services, you can extract from multiple sources, enrich, cleanse, and find matches. These transformations are done automatically based on rules, not one-at-a-time. In some cases, you’ll want to create a bucket of records that you need to manually review.
When you have a large data load, you can automatically cleanse and match a large portion of the data. For those manual review records, you can have the data stewards interact inside of Information Steward to make those decisions.
Provisioning: Review and consolidate best records

Again, this process is for the initial load of a large group of records that may end up in MDG. As individual records come into MDG, you would use the governance workflows inside of MDG.
Provisioning: Load master data into MDG

You can load into MDG from Data Services. The Data Import Framework of MDG is used during the data load into the master data hub. Data can be loaded into the active area and into the staging area. If you consolidate the data before the upload, you normally need to present the data in IDOC/SOA message format for the Data Import Framework (for example MATMAS IDOC for Material). In addition, you can prepare a separate file for key-mapping information if you have created golden records with Data Services. By using custom converters, you can even upload the data in CSV format. For more details, check this link:
Architecture of the File Upload Framework:

You can use the Data Import Framework for all MDG domains. This option always uses a file-based interface and is the most flexible way to do a mass load. For the MDG domains Business-Partner, Supplier, Customer, Material and Financials you can use web services to load data, but that method does not offer the flexibility, performance and error handling offered by the Data Import Framework. For a mass load of data, you should stick to the file-based interface.
Provisioning: Refine master data in MDG and distribute
The final step is to refine the master records inside of MDG and distribute them to the subscribing systems, using the MDG framework.
Remediation and Scorecard integrations
We need data remediation inside of MDG when business rules change. We offer a UI that combines Information Steward scorecarding with MDG workflow processes.

Here you would start at the scorecard and then work back to the individual records that were failing the rules. For example, when currencies change, MDG could be configured to only accept Euros for currency as new records come in. But all of the existing records would still need to be fixed, which is where you would need data quality remediation.
Data Quality Remediation provides the process-integration of identifying erroneous master data in a data quality tool and its correction in MDG. Start with detecting the data quality issues inside of Information Steward. From there, you partition the objects and star the remediation process with MDG. Also in MDG, you’d remedy the data quality issues, so you can get to corrected data.
Remediation: Failed records
Notice that Business Client has the Information Steward scorecard embedded.

In this case, we are drilling down to the red areas on the scorecard. At the bottom, you’ll see the records that have caused the issue.
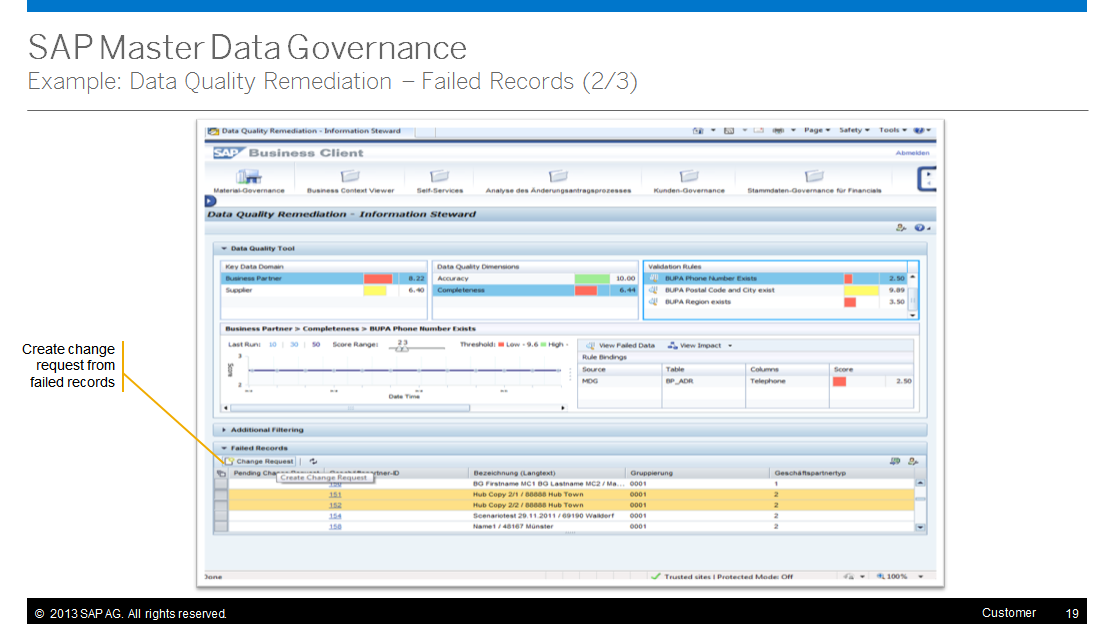
Now we can mark the records that can be fixed together.

With those records selected, we create a change request. At that point, the standard workflow will kick in to take care of these records.
Remediation example: Data quality

The Connector implementation is connecting to Information Steward, and you need the dashboard URL to embed the scorecard inside of the
Business Client UI. We have a SAP Rapid Deployment Solutions that provides this implementation between MDG and Information Steward.
Quality and enrichment integrations
How can these tools then work together on validation during the Creation process?
Process flow archetype

Notice that this archetype starts with maintenance, but validation checks are run throughout the process. We check against back-end ERP rules (since MDG is on top of ERP, we leverage these already-existing checks), and also Data Services matching, enrichment, and addressing checks. We call out to these external services in MDG.
For example, these enrichment spots are where you can call Information Steward validations. Follow this process:
- Write a validation rule in Information Steward.
- Expose the validation rule in Data Services as a web service.
- In MDG, call the Data Services web services job in an enrichment spot.
However, it does not work the other way. You cannot expose a validation rule in ERP in Data Services and Information Steward.
There is also an option to connect your own external services.
Current solution
You can use Data quality to check for duplicates, execute validations, and for address enrichment. These capabilities are supported out-of-the-box.
- Prevent creation of duplicates for increased effectiveness and efficiency
- Checked early and embedded in the process
- High detection quality of matching using Enterprise Search or Data Services
- Validations
- Re-use of existing validation logic in ERP
- Custom validations can be modeled and programmed (e.g. code lists, simple checks, or modeled rules via BRF+)
- Address Enrichment
- Simple check and selection lists
- Integration with content provided by Data Services
- Automatically adding Tax Jurisdiction Code re-using existing interfaces / providers

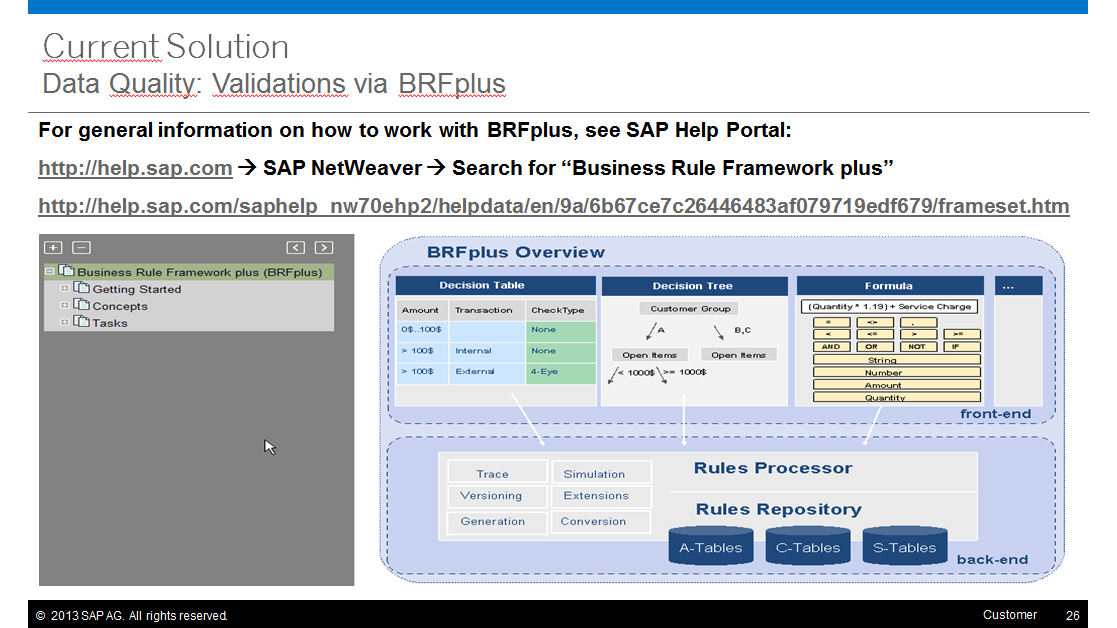
DQ framework for data enrichment spots
- Data Enrichment Spots
- Flexible framework to define enrichment spots
- Is used by SAP for e.g. Address Validation / Enrichment and will be used for further spots in future
- Can be used by customers to define further enhancement spots (e.g. D&B services)
You can use enrichment spots to provide your own implementation for validation. For example, when creating a material, you can call an enrichment spot to enhance the information the user entered or perform a standard check against an external provider.

In this way, you can re-use the business rules created in Information Steward or Data Services directly within MDG.
Data monitoring and alerting

Here we have a MDG hub. We have created consistent and compliant data on the hub, and then distribute to connected business systems. They all receive this clean data. But then not all systems can be locked down, so master data can be changed in one of the downstream systems. MDG will not notice this. This is how inconsistency can happen in your landscape. (Notice the red boxes in these now non-compliant systems.) What is even worse is that now end-to-end business processes that go across several systems might now use this inaccurate data.
One way to address this is to use Information Steward. Define the information policies and relevant rules. Then monitor master data from all of these systems against the rules specified in Information Steward. You can then view a dashboard that shows if any of these systems are no longer meeting the rules. React on these problematic records with the Data Quality remediation outlined above.
You can see that there are many integration points between these tools, and we are developing more all of the time. Are there other use cases you are wondering about?
- SAP Managed Tags:
- SAP Data Services,
- SAP Information Steward,
- SAP Master Data Governance
- ASUG
- brf+
- data governance
- data integrator
- Data Provisioning
- data quality
- data quality management
- data services
- eim
- enrichment controller
- enterprise information management
- enterprise service bus
- extractors
- information governance
- information steward
- Integrations
- master data governance
- MDG
- rds
- Retagging Required
- SAP Data Services
- SAP Information Steward
- SAP Master Data Governance
- SAP Rapid Deployment Solutions
- Validation
14 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
12 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
340 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
417 -
Workload Fluctuations
1
Related Content
- FAQ for C4C Certificate Renewal in Technology Blogs by SAP
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
- It’s Official - SAP BTP is Again a Leader in G2’s Reports in Technology Blogs by SAP
- Empowering Retail Business with a Seamless Data Migration to SAP S/4HANA in Technology Blogs by Members
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 7 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 34 | |
| 25 | |
| 12 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |