
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- [Oracle] DB Optimizer Part X - Looking under the h...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
stefan_koehler
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-19-2014
12:21 PM
Introduction
In the first part of the "Adaptive Query Optimization" series we looked at the feature set called "Adaptive Plans", which is completely new in Oracle 12c. However Adaptive Query Optimization consists of two feature sets called "Adaptive Plans" and "Adaptive Statistics". The latter (or better said the new features of it) should be the main topic in this blog post. Some of these automatic and "under the hood" changes may have influences on your SQL execution plans and statistic runs in consequence without even knowing their existence at all. Dynamic statistics already exists to a certain point with Oracle 11g (and were even called that way since 11.2.0.4), but the terminology itself has changed and the scope was extended with Oracle 12c.
What are we talking about?
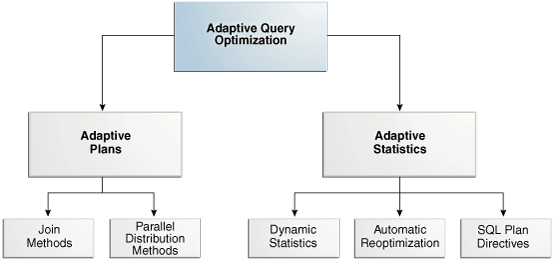

*** The right graphic is a screenshot from Kerry Osborne's presentation "Adaptive Optimization" for better illustration and differentiation
As previously mentioned we already have investigated the feature set called "Adaptive Plans" (left tree) and now we will take a closer look at the "Adaptive Statistics" on the right tree side. Please remember, that the feature set "Adaptive Plans" should improve the performance of the initial execution of a SQL and the feature set "Adaptive Statistics" should mainly improve the performance of the subsequent executions. Before we dig into the official Oracle documentation and the corresponding white papers - let's clarify some new Oracle terms first.
Oracle terminology
| Oracle 12c | Oracle 11g |
|---|---|
| Statistics Feedback | Cardinality Feedback |
| Dynamic Statistics | Dynamic Sampling |
| SQL Plan Directives | Not available in 11g |
Oracle Documentation
Dynamic Statistics
During the compilation of a SQL statement, the optimizer decides whether to use dynamic statistics by considering whether the available statistics are sufficient to generate an optimal execution plan. If the available statistics are insufficient, then the optimizer uses dynamic statistics to augment the statistics. One type of dynamic statistics is the information gathered by dynamic sampling. The optimizer can use dynamic statistics for table scans, index access, joins, and GROUP BY operations, thus improving the quality of optimizer decisions.
About Dynamic Statistics Levels (adjusted / new level 11)
The dynamic statistics level controls both when the database gathers dynamic statistics, and the size of the sample that the optimizer uses to gather the statistics. Set the dynamic statistics level using either the OPTIMIZER_DYNAMIC_SAMPLING initialization parameter (dynamic statistics were called dynamic sampling in releases earlier than Oracle Database 12c) or a statement hint.
Level 11 - Use dynamic statistics automatically when the optimizer deems it necessary. The resulting statistics are persistent in the statistics repository, making them available to other queries.
When OPTIMIZER_DYNAMIC_SAMPLING is set to 11, the optimizer will use dynamic statistics to verify cardinality estimates for all SQL operators, and it will determine an internal time limit to spend verifying the estimates. There are cases where the optimizer will automatically decide to use 11, for example:
- The query will run in parallel
- The query was executed before and its history is available (from the cursor cache, Automatic Workload Repository, or the SQL Management Base).
Automatic Reoptimization
Whereas adaptive plans help decide between multiple subplans, they are not feasible for all kinds of plan changes. For example, a query with an inefficient join order might perform suboptimally, but adaptive plans do not support adapting the join order during execution. In these cases, the optimizer considers automatic reoptimization. In contrast to adaptive plans, automatic reoptimization changes a plan on subsequent executions after the initial execution. At the end of the first execution of a SQL statement, the optimizer uses the information gathered during execution to determine whether automatic reoptimization is worthwhile. If execution informations differs significantly from optimizer estimates, then the optimizer looks for a replacement plan on the next execution. The optimizer uses the information gathered during the previous execution to help determine an alternative plan. The optimizer can reoptimize a query several times, each time learning more and further improving the plan.
Reoptimization: Statistics Feedback
A form of reoptimization known as statistics feedback (formerly known as cardinality feedback) automatically improves plans for repeated queries that have cardinality misestimates. The optimizer can estimate cardinalities incorrectly for many reasons, such as missing statistics, inaccurate statistics, or complex predicates.
Reoptimization: Performance Feedback
Another form of reoptimization is performance feedback. This reoptimization helps improve the degree of parallelism automatically chosen for repeated SQL statements when PARALLEL_DEGREE_POLICY is set to ADAPTIVE.
SQL Plan Directives
A SQL plan directive is additional information that the optimizer uses to generate a more optimal plan. For example, during query optimization, when deciding whether the table is a candidate for dynamic statistics, the database queries the statistics repository for directives on a table. If the query joins two tables that have a data skew in their join columns, a SQL plan directive can direct the optimizer to use dynamic statistics to obtain an accurate cardinality estimate.The optimizer collects SQL plan directives on query expressions rather than at the statement level. In this way, the optimizer can apply directives to multiple SQL statements. The database automatically maintains directives, and stores them in the SYSAUX tablespace. You can manage directives using the package DBMS_SPD.
DBMS_SPD - Overview
SPD are objects generated automatically by Oracle. For example, if Oracle detects that the single table cardinality estimated made by the optimizer is different from the actual number of rows returned when accessing the table, it will automatically create a directive to perform dynamic statistics for the table. When any SQL statement referencing the table is compiled, the optimizer will perform dynamic statistics for the table to get a more accurate estimate.
Oracle White Paper - Optimizer with Oracle Database 12c
SQL plan directives
SQL plan directives are automatically created based on information learnt via Automatic Reoptimization.
Currently there is only one type of SQL plan directive, ‘DYNAMIC_SAMPLING’. This tells the optimizer that when it sees a particular query expression it should use dynamic sampling to address the cardinality misestimate. SQL plan directives are also used by Oracle to determine if extended statistics, specifically column groups, are missing and would resolve the cardinality misestimates.
After a SQL directive is used the optimizer decides if the cardinality misestimate could be resolved with a column group. If so, it will automatically create that column group the next time statistics are gathered on the appropriate table. The extended statistics will then be used in place of the SQL plan directive when possible (equality predicates, group bys etc.). If the SQL plan directive is no longer necessary it will be automatically purged after 53 weeks.
Oracle White Paper - Understanding Optimizer Statistics with Oracle Database 12c
Dynamic Statistics (previously known as dynamic sampling)
Dynamic sampling was introduced in Oracle Database 9i Release 2 to collect additional statement-specific object statistics during the optimization of a SQL statement. The most common misconception is that dynamic sampling can be used as a substitute for Optimizer statistics. The goal of dynamic sampling is to augment the existing statistics; it is used when regular statistics are not sufficient to get good quality cardinality estimates.
In Oracle Database 12c dynamic sampling has been enhanced to become dynamic statistics. Dynamic statistics allow the optimizer to augment existing statistics to get more accurate cardinality estimates for not only single table accesses but also joins and group-by predicates
So, how and when will dynamic statistics be used? During the compilation of a SQL statement, the Optimizer decides whether to use dynamic statistics or not by considering whether the available statistics are sufficient to generate a good execution plan. If the available statistics are not enough, dynamic sampling will be used. It is typically used to compensate for missing or insufficient statistics that would otherwise lead to a very bad plan. For the case where one or more of the tables in the query does not have statistics, dynamic sampling is used by the Optimizer to gather basic statistics on these tables before optimizing the statement. The second scenario where dynamic statistics can be used is when the statement contains a complex predicate expression, and extended statistics are not available, or cannot be used.
Dynamic sampling is controlled by the parameter OPTIMIZER_DYNAMIC_SAMPLING, which can be set to different levels (0-11). These levels control two different things; when dynamic sampling kicks in, and how large a sample size will be used to gather the statistics. The greater the sample size, the bigger impact dynamic sampling has on the compilation time of a query.
When set to 11 the Optimizer will automatically decide if dynamic statistics will be useful, and what dynamic sampling level will be used for SQL statements The optimizer bases its decision, to use dynamic statistics, on the complexity of the predicates used, the existing base statistics, and the total execution time expected for the SQL statement. For example, dynamic statistics will kick in for situations where the Optimizer previously would have used a guess.
Given these criteria it’s likely that when set to level 11, dynamic sampling will kick-in more often than it did before. This will extend the parse time of a statement. In order to minimize the performance impact, the results of the dynamic sampling queries will be persisted in the cache, as dynamic statistics, allowing other SQL statements to share these statistics.
So far enough from the official Oracle documentation and white papers, but that amount of basic information was necessary to understand the following content.
In the following blog part i will focus on the optimizer enhancement "SQL Plan Directives" and its implementation as it is completely new and not just renamed by Oracle :wink:
"SQL Plan Directives" demo
The following demo was run on an Oracle database (12.1.0.1) on OEL 6.4 (2.6.39-400.109.1.el6uek.x86_64) and with an Oracle schema called "TESTUSER". At first we need to clarify some specific types and states before we setup the demo data and run the SQL examples.
Types in view DBA_SQL_PLAN_DIRECTIVES:
- DYNAMIC_SAMPLING is currently the only supported type for SQL plan directives (definition of base view _BASE_OPT_DIRECTIVE is "decode(type, 1, 'DYNAMIC_SAMPLING', 'UNKNOWN')")
States in view DBA_SQL_PLAN_DIRECTIVES
- NEW - Newly created directive
- MISSING_STATS - Directive object does not have relevant statistics (and needs extended statistics)
- HAS_STATS - Objects have extended statistics
- CANDIDATE - Candidate directive, the server to evaluate effectiveness
- PERMANENT - A permanent directive determined by the server to be effective and useful as predicates can not be handled by extended statistics. Remember that the optimizer uses column group statistics for equality predicates, inlist predicates, and for estimating the group by cardinality.
CBO settings and dynamic statistics level
SQL> show parameter optimizer_adaptive_features
SQL> show parameter optimizer_dynamic_sampling
SQL> show parameter optimizer_features_enable

Create the base table and data set (it is the same correlated data set as in my previous blog post [Oracle] DB Optimizer Part V - Introduction of dynamic sampling and why it is used in SAP BI environ...)
SQL> create table DYNTEST (COUNTRY VARCHAR2(40), WERKS VARCHAR(20),
TEXT VARCHAR(4000));
SQL> exec DBMS_STATS.GATHER_TABLE_STATS(USER, 'DYNTEST');

SQL> select OWNER, TABLE_NAME, COLUMN_ID as CNT, COLUMN_NAME,
DATA_TYPE, DATA_LENGTH as LENGTH, AVG_COL_LEN, NUM_DISTINCT as DSCNT,
DENSITY, NUM_NULLS, HISTOGRAM, NUM_BUCKETS as BUCKETS
from DBA_TAB_COLUMNS
where OWNER = 'TESTUSER' and TABLE_NAME = 'DYNTEST'
order by OWNER, TABLE_NAME, COLUMN_ID;

SQL> select OWNER, TABLE_NAME, COLUMN_NAME, AVG_COL_LEN,
NUM_DISTINCT as DSCNT, LOW_VALUE, HIGH_VALUE, DENSITY, NUM_NULLS,
HISTOGRAM, NUM_BUCKETS as BUCKETS, LAST_ANALYZED
from ALL_TAB_COL_STATISTICS
where OWNER = 'TESTUSER' and TABLE_NAME = 'DYNTEST' and COLUMN_NAME like 'SYS_%'
order by OWNER, TABLE_NAME, COLUMN_NAME;
no rows selected
SQL> select TABLE_NAME, EXTENSION_NAME, EXTENSION from DBA_STAT_EXTENSIONS
where OWNER = 'TESTUSER' and TABLE_NAME = 'DYNTEST';
no rows selected
SQL> exec DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE();
SQL> select * from DBA_SQL_PLAN_DIR_OBJECTS where OWNER = 'TESTUSER';
no rows selected
First execution of SQL with correlated columns
SQL> select /*+ gather_plan_statistics */ * from DYNTEST where COUNTRY = 'DE' and WERKS = '1200';

The cost based optimizer is way off by design and its limits (273 estimated rows in contrast to 1.000 actually returned rows).
SQL> select CHILD_NUMBER, IS_REOPTIMIZABLE from V$SQL where SQL_ID = '6jr7pwrk2tszg';

According to the documentation of column IS_REOPTIMIZABLE in view V$SQL. This columns shows whether the next execution matching this child cursor will trigger a reoptimization. The values are:
- Y: If the next execution will trigger a reoptimization
- R: If the child cursor contains reoptimization information, but will not trigger reoptimization because the cursor was compiled in reporting mode
- N: If the child cursor has no reoptimization information
Flush SQL plan directives from memory to disk manually (automatically done every 15 minutes by default)
SQL> exec DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE();
SQL> select * from DBA_SQL_PLAN_DIR_OBJECTS where OWNER = 'TESTUSER';

A SQL plan directive was automatically created to correct the cardinality misestimate on the DYNTEST table caused by correlation between the multiple single-column predicates.
select * from DBA_SQL_PLAN_DIRECTIVES where DIRECTIVE_ID = 4423171997703515062;

This particular SQL plan directive has the state "NEW" (check detailed explanation above) and the reason for this directive is a "SINGLE TABLE CARDINALITY MISESTIMATE" which makes sense as well. Please note that this SQL plan directive was just created and not used at all.
Second execution of the same SQL with correlated columns
SQL> select /*+ gather_plan_statistics */ * from DYNTEST where COUNTRY = 'DE' and WERKS = '1200';

A new child cursor was created and the estimated rows are in the right ball park (based on statistics feedback) now, but there is still no indication for the instruction usage of SQL plan directives. However the reason for this can be found in the CBO trace file with the comment "Not using dynamic sampling since cardinality or selectivity hint present and no NDV needed". So basically the SQL plan directive instruction is already well known, but not followed due to hint OPT_ESTIMATE by statistics feedback.
SQL> select CHILD_NUMBER, IS_REOPTIMIZABLE from V$SQL where SQL_ID = '6jr7pwrk2tszg';

Flush SQL plan directives from memory to disk manually (automatically done every 15 minutes by default)
SQL> exec DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE();
SQL> select * from DBA_SQL_PLAN_DIRECTIVES where DIRECTIVE_ID = 4423171997703515062;

This particular SQL plan directive has the state "MISSING_STATS" (check detailed explanation above) now and was adjusted by the last SQL execution (with statistics feedback).
Simulate "SQL statement flush out" and execute it with existing SQL plan directive
SQL> alter system flush shared_pool;
SQL> select /*+ gather_plan_statistics */ * from DYNTEST where COUNTRY = 'DE' and WERKS = '1200';

Look at this - the row estimates are correct now right from the start (after the SQL has been aged out from the library cache and need to be parsed again). The note section states that a SQL plan directive was used and that dynamic sampling (= instruction from the SQL plan directive) was performed.
CBO trace with SQL plan directives (in MISSING_STATS state)
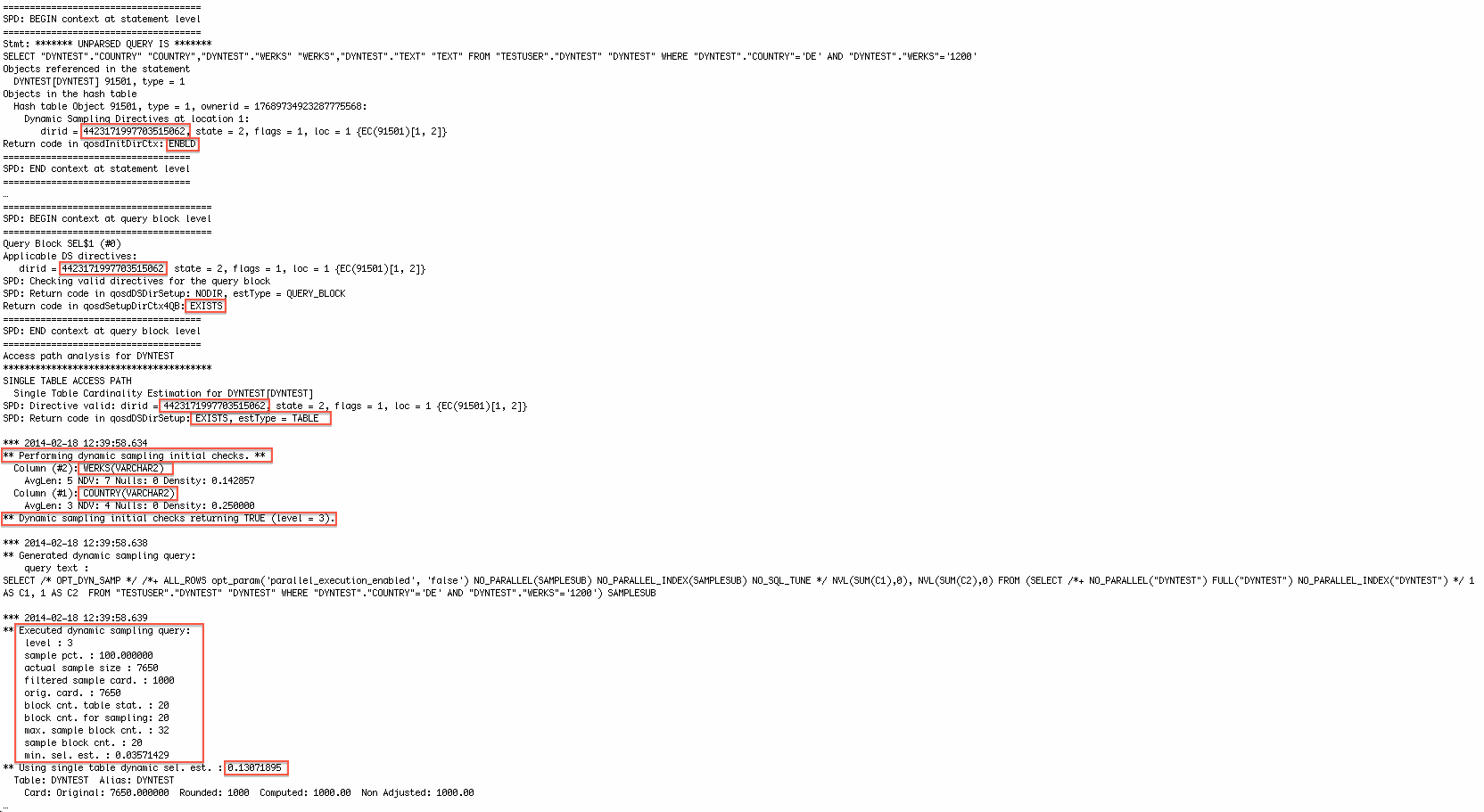
Gather statistics with DBMS_STATS and existing SQL plan directive
SQL> exec DBMS_STATS.GATHER_TABLE_STATS(USER, 'DYNTEST');
SQL> select OWNER, TABLE_NAME, COLUMN_ID as CNT, COLUMN_NAME,
DATA_TYPE, DATA_LENGTH as LENGTH, AVG_COL_LEN, NUM_DISTINCT as DSCNT,
DENSITY, NUM_NULLS, HISTOGRAM, NUM_BUCKETS as BUCKETS
from DBA_TAB_COLUMNS
where OWNER = 'TESTUSER' and TABLE_NAME = 'DYNTEST'
order by OWNER, TABLE_NAME, COLUMN_ID;

The histograms on columns COUNTRY and WERKS are an "old behavior" (SYS.COL_USAGE$) and not new at this point.
SQL> select OWNER, TABLE_NAME, COLUMN_NAME, AVG_COL_LEN,
NUM_DISTINCT as DSCNT, LOW_VALUE, HIGH_VALUE, DENSITY, NUM_NULLS,
HISTOGRAM, NUM_BUCKETS as BUCKETS, LAST_ANALYZED
from ALL_TAB_COL_STATISTICS
where OWNER = 'TESTUSER' and TABLE_NAME = 'DYNTEST' and COLUMN_NAME like 'SYS_%'
order by OWNER, TABLE_NAME, COLUMN_NAME;

Oracle has automatically created extended statistics (column group statistics) for the previous used correlated columns in the WHERE clause.
SQL> select TABLE_NAME, EXTENSION_NAME, EXTENSION from DBA_STAT_EXTENSIONS
where OWNER = 'TESTUSER' and TABLE_NAME = 'DYNTEST';

The extension "SYS_STSNGS_X_L#DNTEN#KCGN#426H" is based on the two columns as mentioned previously.
Flush SQL plan directives from memory to disk manually (automatically done every 15 minutes by default)
SQL> exec DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE();
SQL> select * from DBA_SQL_PLAN_DIRECTIVES where DIRECTIVE_ID = 4423171997703515062;

That is kind of strange. The last DBMS_STATS run has gathered extended statistics, but the state is still "MISSING_STATS".
Simulate "SQL statement flush out" and execute it with existing SQL plan directive and extended statistics
SQL> alter system flush shared_pool;
SQL> select /*+ gather_plan_statistics */ * from DYNTEST where COUNTRY = 'DE' and WERKS = '1200';
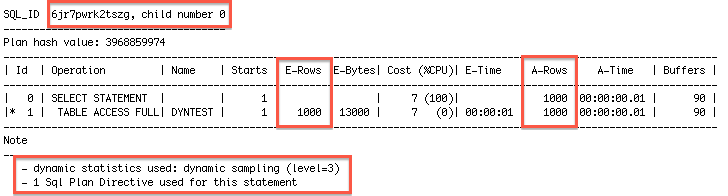
The same behavior as before the DBMS_STATS run. The SQL plan directive with the dynamic sampling instruction is still used instead of the available column group statistics.
Flush SQL plan directives from memory to disk manually (automatically done every 15 minutes by default)
SQL> exec DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE();
SQL> select * from DBA_SQL_PLAN_DIRECTIVES where DIRECTIVE_ID = 4423171997703515062;

But now the SQL plan directive has the state "HAS_STATS". So this basically means that the plan directive is only modified by the SQL execution itself. At last let's run the same SQL once again with this new state.
Simulate "SQL statement flush out" and execute it with existing SQL plan directive and extended statistics
SQL> alter system flush shared_pool;
SQL> select /*+ gather_plan_statistics */ * from DYNTEST where COUNTRY = 'DE' and WERKS = '1200';

Now the extended statistics are used by the cost based optimizer and the SQL plan directive is "ignored".
CBO trace with SQL plan directives (in HAS_STATS state)

Purging / Automatic clean up of SQL plan directives
SQL plan directives are automatically purged (by default), if they are not used for more than SPD_RETENTION_WEEKS.
SQL> select DBMS_SPD.GET_PREFS('SPD_RETENTION_WEEKS') from dual;
DBMS_SPD.GET_PREFS('SPD_RETENTION_WEEKS')
-------------------------------------------
53
Summary
Nowadays SQL plan directives are basically something like a persistent dynamic sampling instruction with possible further influences on DBMS_STATS runs. On one side SQL plan directives introduce a new level of complexity by understanding the CBO behavior and troubleshooting (dynamic) execution plans, but on the other side it can help to improve the performance of subsequent "first" executions (e.g. after flushed out of memory) of a SQL statement as it does not have to go through the whole "re-optimization" process after it has been aged out from library cache. However it becomes more and more important to determine the exact state at a given point in time by troubleshooting performance and execution plan issues, which can be very tricky of course.
In my experience (based on my Oracle 12c troubleshooting request so far) this feature set is not well known and the clients are surprised when they discover the "system generated" statistics extensions or the execution plan changes on subsequent first executions.
If you have any further questions - please feel free to ask or get in contact directly, if you need assistance by troubleshooting Oracle database (performance) issues or in any case of Oracle 12c projects / tasks.
References
- Kerry Osborne - Adaptive Optimization presentation
- Kerry Osborne - Adaptive Optimization webinar
- Oracle Documentation - Adaptive Statistics
- Oracle Documentation - Controlling Dynamic Statistics
- Oracle Documentation - Parameter OPTIMIZER_DYNAMIC_SAMPLING
- Oracle Documentation - PL/SQL package DBMS_SPD
- Oracle Documentation - View DBA_SQL_PLAN_DIRECTIVES
- Oracle Documentation - View DBA_SQL_PLAN_DIR_OBJECTS
- Oracle Documentation - View V$SQL
- Oracle White Paper - Optimizer with Oracle Database 12c
- Oracle White Paper - Understanding Optimizer Statistics with Oracle Database 12c
- SAP Managed Tags:
- Oracle Database
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
General Splitter
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
learning content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
10 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
14 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Analyze Expensive ABAP Workload in the Cloud with Work Process Sampling in Technology Blogs by SAP
- Workload Analysis for HANA Platform Series - 1. Define and Understand the Workload Pattern in Technology Blogs by SAP
- Workload Analysis for HANA Platform Series - 2. Analyze the CPU, Threads and Numa Utilizations in Technology Blogs by SAP
- Safeguard your SAP BW conversion with SAP Enterprise Support services in Technology Blogs by SAP
- Performance tuning in SAP Data Service in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 10 | |
| 9 | |
| 5 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |