
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- From the Archives: The Window Operator and Window ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-28-2014
11:08 PM
In this post, originally written by Glenn Paulley and posted to sybase.com in March of 2009, Glenn talks about some of the advanced functionality available for performing analytical operations in SQL Anywhere, and how the query optimizer can take advantage of these constructs.
OLAP (On-Line Analytical Processing) functions were first published as an addendum to the ISO SQL:1999 standard, and since have been completely incorporated into both the SQL:2003 and the recently-published SQL:2008 ISO SQL Standards. SQL Anywhere has included OLAP functionality since the 9.0.1 release (February 2004), which comprises grammar and query processing support for:
GROUP BY [ CUBE | ROLLUP | GROUPING SETS ]- the
WINDOWclause and windowed aggregate functions, including window versions of the basic aggregate functions (SUM(), AVG(), MAX(), MIN(), COUNT()) and additional OLAP window aggregate functions includingRANK()andDENSE_RANK() - the row-numbering function
ROW_NUMBER(); - functions supporting more advanced statistical analysis, particularly linear regression analysis functions.
Unfortunately, WINDOW functions remain beyond the experience of the majority of application developers, who typically have a working knowledge of the considerably simpler SQL:1992 standard.
What is a window?
Brendan Lucier and I authored a whitepaper entitled "Analytic Functions in SQL Anywhere" that explains windows and window functions in detail. Here is an excerpt:
The SQL/OLAP windowing extensions allow a user to divide the result set of a query into groups of rows called partitions. Logically, as part of the semantics of computing the result of a query specification, partitions are created after the groups defined by the GROUP BY clause are created, but before the evaluation of the final SELECT list and the query's ORDER BY clause. Consequently, the order of evaluation of the clauses within an SQL statement becomes:From => Where => Group by => Having => Window => Distinct => Order by.
Because window partitioning follows a GROUP BY operator, the result of any aggregate function, such as SUM(), AVG(), and VARIANCE(), is available to the computation done for a partition. Hence a window provides another opportunity to perform grouping and ordering operations in addition to a query's GROUP BY and ORDER BY clauses. However, any computation involving a window function's result. for example, using it in a predicate will require a more complex statement construction. Typically that construction will require a derived table to compute the window function result(s), with the derived table's outer SELECT block containing the desired WHERE clause predicates. A window's partition can consist of the entire input, a single row, or something in between. The advantage of a 'window' construct is that the rows within the partition can then be sorted to support the additional expressive power provided by window functions.
The advantage of using window functions is that it can considerably simplify query processing by eliminating nested queries and/or self-joins. Ideally, it shouldn't matter how one writes an SQL statement, since it's the job of the query optimizer to determine the best way to compute the query's result. There are classes of statements where the optimizer will convert nested queries to ones using a WINDOW operator, but not all semantic transformations are handled automatically; on occasion, a specific syntactic rewrite is necessary.
An Example using Window
As an example, suppose we wish to compute the following from the "Demo" sporting goods retailer sample database: List all product orders where a product's order quantity was the maximum of any order for that product. Here's one way to do that:
SELECT soi.ProductID, so."ID", so.CustomerID, soi.LineID, soi.quantity
FROM SalesOrders so JOIN SalesOrderItems soi ON(soi."ID" = so."ID")
WHERE EXISTS( SELECT 1
FROM (SELECT soi2.ProductID, max(soi2.quantity) as maxQ
FROM SalesOrderItems soi2
GROUP BY soi2.ProductID ) as V
WHERE v.maxQ = soi.quantity AND
soi.ProductID = v.ProductID )
ORDER BY 1,2In the nested SQL query above, the existentially-quantified subquery computes the maximum quantity for each product over all orders; these maximums are then compared to each individual order line-item, and if there is a match, that row becomes part of the result. Here is the query plan:

Note the resulting plan contains two joins: the nested GROUP BY query has been converted by the query optimizer into a derived table, which is (self) joined using a Hash Semijoin operator with the SalesOrderItems table from the original outer SQL block. The access plan for the statement is fine - but if we instead use a window function to compute the maximal product orders, we can eliminate the nested query block and the self-join entirely. Here's the rewritten query using a window function:
SELECT maxO.ProductID, so."ID", so.CustomerID, maxO.LineID, maxO.quantity
FROM SalesOrders so JOIN
(SELECT soi."ID", soi.LineID, soi.ProductID, soi.quantity,
MAX(soi.quantity) OVER (PARTITION BY soi.ProductID) as maxQ
FROM SalesOrderItems soi ) as maxO( "ID", LineID, ProductID, quantity, maxQ)
ON(so."ID" = maxo."ID")
WHERE maxo.quantity = maxo.maxQ
ORDER BY maxo.ProductID, so."ID"
In this query, MAX() is a window aggregate function, specified to compute maximum quantities over an unnamed window (OVER) for all product orders with the same ProductID. Logically, a window is computed after the tuples from SalesOrderItems are processed. The window partitions (groups) the input tuples by ProductID, much like a GROUP BY clause would--the difference is that with a window the original attributes from each SalesOrderItems tuple are retained in the output. The SELECT computes the window aggregate function MAX(quantity), which like the nested query computes the maximum order quantity for that product, but concatenates each that maximum quantity (for that specific product) to each SalesOrderItems tuple.
Here is the access plan for this query, utilizing the window function which is computed via a window plan operator:

With only two quantifiers, we now (only) have a single join (a cheap nested-loop join) between the SalesOrder table and the derived table that delivers both the attributes from the SalesOrderItems table and the maximum order quantity for each product line item.
Using window functions in this way can substantially benefit complex queries since it can eliminate an expensive self-join that may be difficult for the optimizer to optimize properly. Moreover, it can often eliminate outright a quantified subquery from the original statement, so that set operations are utilized as much as possible.
However, in other instances (or when using tools that do not generate WINDOW queries) coding using nested queries may still be the way to go. In some cases, the SQL Anywhere query optimizer will recognize cases where the use of a quantified subquery can be turned into a windowed query, and it does so on a cost-basis. Here's a rewritten version of the first query above, written so as to remove the GROUP BY clause within the nested block:
SELECT soi.ProductID, so."ID", so.CustomerID, soi.LineID, soi.quantity
FROM SalesOrders so JOIN SalesOrderItems soi ON(soi."ID" = so."ID")
WHERE soi.quantity = (SELECT MAX(soi2.quantity)
FROM SalesOrderItems soi2
WHERE soi2.ProductID = soi.ProductID)
ORDER BY soi.ProductID, so."ID"
The query optimizer has a choice: it can retain the nested iteration semantics, or on a cost basis determine if rewriting this nested query as a join and utilizing a WINDOW operator may be beneficial. In this case, the optimizer chooses the latter; note the similarity of this access plan to the one above for the WINDOW query:

As yet another alternative, one can use a universally-quantified subquery to find only those rows from SalesOrderItems that contain maximal orders:
SELECT soi.ProductID, so."ID", so.CustomerID, soi.LineID, soi.quantity
FROM SalesOrders so JOIN SalesOrderItems soi ON(soi."ID" = so."ID")
WHERE NOT EXISTS( SELECT 1
FROM SalesOrderItems soi2
WHERE soi2.ProductID = soi.ProductID and soi2.quantity > soi.quantity )
ORDER BY 1,2Ordinarily, universally-quantified subqueries are difficult to get one's head around, and their optimization can be problematic. However, in this case the optimizer has a number of choices at its disposal: strict nested iteration, leaving the subquery intact but whose multiple executions can be mitigated by subquery memoization; an anti-semijoin, perhaps a hash-based anti-semijoin; or a rewrite using one or more window functions, again all on a cost basis. The advantage here is that the MAX() aggregate function is eliminated outright, replaced with a simple inequality between quantity amounts which, hopefully, leads to better join selectivity estimates and avoids poor execution strategies:
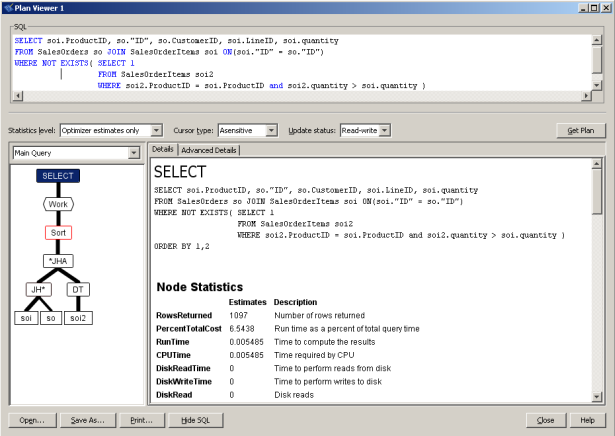
In this instance, SQL Anywhere's query optimizer has chosen a hash anti-join operator to filter those SalesOrderItems rows that are not maximal.
In summary: SQL is a complex language that permits a wide variety of formulations to compute the same result. At a theoretical level, Window operations don't add expressive power to the SQL language because other constructions, which may require multiple statements, can provide the same functionality as window functions. However, on a pragmatic basis, window functions have the potential to lead to better query execution plans by eliminating joins and nested queries, yet retaining the simplicity of a single SQL statement.
My thanks to Ivan Bowman for discussions on this topic, and for rounding-out the discussion with the NOT EXISTS example.
- SAP Managed Tags:
- SAP SQL Anywhere
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Data Flows - The Python Script Operator and why you should avoid it in Technology Blogs by Members
- Connection restrictions and their relation to user groups in SAP HANA Cloud, SAP HANA Database in Technology Blogs by SAP
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- Sorting issue with STRING_AGG in Hana Table function in Technology Q&A
- Fiori elements list report: Aggregate functions are not allowed in transactional views? in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |