I was going through the se93 transaction and came across Utility-->Call Graph
This Give us the hierarchical view of the source code. As an example go to se93 and put in a transaction code and click on Utility-->Call Graph.

The following screen would come.

Clicking on the + will expand as follows
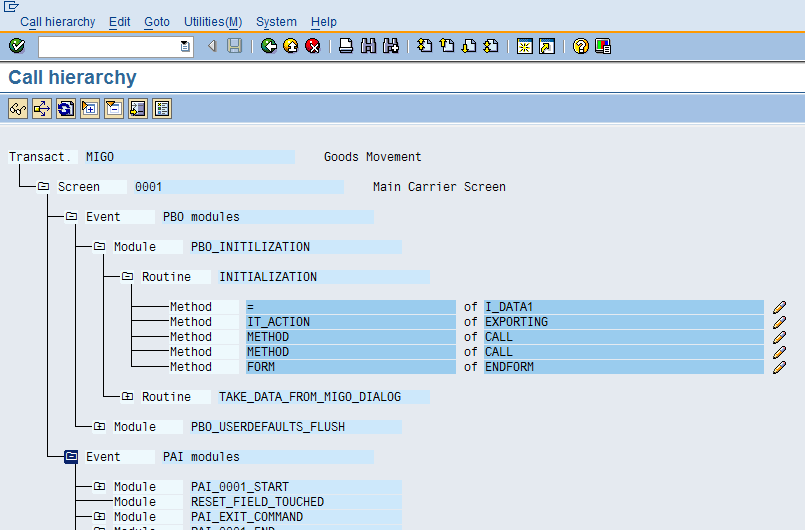
The initial screen for migo is 001. By expanding each of the nodes we can see which all modules are there. Double clicking on the module takes you directly to the screen painter and you can understand further.

This gives us a basic understanding on how the program flow is. This may not work for parameter transaction.
