
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Improved Inside-Out Modelling
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-17-2013
3:10 PM
What is inside-out modelling?
It is a design paradigm that takes a business component and models it so that it can be exposed as a service. The entities and properties thereof are generally driven by the component interface. The most common form of inside-out driver is the RFC function module, although BOR objects and others like GENIL are available.
This is in contrast to outside-in model design , where the service that is required is modelled and the appropriate backend components are located or built to serve the consumption model.
The important phrase for me is “to serve the consumption model”; conversely, inside-out design can be paraphrased as “a service imposed by the business model”. Gateway consumers should not really be concerned with or know about the business model; it is generally a lot bigger and more complex than a particular service use case would need.
I've discussed that preferred approach here: Outside-in modelling (or "rehab" for RFC addicts).
I am not a huge advocate of inside-out modelling but where it is deemed necessary, it can often be improved to work in a Gateway OData service context.
Let’s take the SAP expenses application & data concept as a starting point. “Expenses” is quite a complex beast; it has not been designed with modular access in mind, it is very monolithic in nature. Despite a revamped UI in Web Dynpro, it hasn’t really altered in the backend logic or model.
Rather than tackle the whole of the expenses component, I’m going to focus on one part – “trip options”. These are essentially the lists of options that you can choose for data entry while completing an expenses form. They are typically used to provide context and fill dropdowns or other value choice controls in a UI. What I found interesting about this part is that it mirrors certain aspects of the expenses component on a macro level.
If you wish to obtain the trip options, you can get the data from the BAPI_TRIP_GET_OPTIONS function.
This function returns 20 tables of various data! Here is a prime example of where inside-out design fails for me – how am I going to map 20 outputs to one entity? Typically one RFC is mapped to an entity to satisfy the READ operation.
At this point I would abandon any hope of providing a well-conceived service and look at the outside-in approach – but more on that later.
Back to the modelling exercise : if I have to do it this way, how do I do it well?
One BAPI, twenty collections
Do I need all 20 tables for my service? Those I don’t need to fetch I can remove from the plan.
For example, I’ll use these:
- EMP_INFO
- DEFAULTS
- EXPENSE_TYPES
- COUNTRIES
- CURRENCIES
(In reality I’ll probably need more but 25% is a good cut for an example.)
Now, the approach that the majority of beginners in Gateway will take is to try and send all five of these tables back in one read operation, based on the assumption that simple request/responses can return multiple tables (like a BAPI!).
That is not the way to do it. You can’t do it. Fundamental OData is based on flat structures.
Here’s where the promised improvement starts…
What you do is create five entities with corresponding entitysets (build sets only if required; EMP_INFO for example has a cardinality of 1:1).
Each entity/collection is read by a separate GET request.
This has the following advantages.
- The service entities are decoupled from the backend model; after all they are siblings, not part of a dependency set.
- A collection can be read when it is required, rather than obtained as part of another package of collections. One, a few or all of the entities can be accessed as required without any request constraints.
- More of the collections can be exposed if the service evolves, or conversely, deprecation is easier.
It does carry some disadvantages however;
- The BAPI logic obtains all 20 outputs regardless of those that are required; despite the outputs being optional, pretty much all data is returned.
- Using the BAPI still accesses 100% of the data when I only want 25%.
- Each read of an entityset obtains the other four entitysets again!
In performance terms, where I only want to read five collections with one BAPI call, I am reading 100 (5 calls x 20 tables). Not great!
In this inside-out model, there has to be a balance between the unnecessarily complex and unclear means of implementing a method for obtaining the five collections and the enforced constraint of excessive access.
...And the answer is..?
Moving towards a solution, some of you may ask, ”If we read the EMP_INFO entity with this BAPI, it would have read the other four data tables for the other entities. Why don’t we just store these tables in memory then use them to fill the other sets when required?”
Indeed that would be a good idea; except that the request for EMP_INFO is stateless. If we store the other four tables, they are gone when we try a request for DEFAULTS as a second request, so the BAPI will have to go and read them again, plus the EMP_INFO we already have. And so on for the other collections.
Statefulness can be introduced fairly easily. It is possible to get five entitysets in one request with one BAPI call. The key to this is using the $expand option – when a request is “expanded” the required feeds for the expansion are evaluated in the same connection session, therefore the state is maintained for the duration of the request.
One drawback is that the client needs to know how to place the call in the right way to take advantage of this feature, however the feature is at least available!
The final model design
$expand is commonly used to obtain related entities, however it can be used to chain “unrelated” GET’s into one request as well.
In order to place an expand request, there has to be some relation – but there is no clear relation between the entities, they are not hierarchical.
I’ll now take a technique from the world of outside-in modelling in order to help me realise the model. If the entity design is coming from the outside, it does not have to have a direct (or any!) correlation to a data model on the inside. As long as I can devise a way to place meaningful data in the feed or response, that entity is valid.
What I need is a common relation for all of my five (or even the full 20) chosen entities. This is quite obvious – the entities are all BAPI outputs, so it follows that I should look at the input.
In order to provide those 20 outputs, all I require is an employee number. To properly qualify the context I should also add a date and language, which are optional inputs but can make a difference.
Based on this information, I design an entity called TripContext with properties for employee number, trip date and language – I also make sure they are all keys.
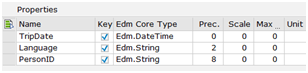
I can then provide an association from my TripContext to each entity and collection in the trip option service.
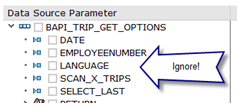
Because I am going to relate my collections to another entity, I do not pay any attention to the input parameters during the RFC wizard steps. Choosing and realising inputs is another feature of this process that creates a lot of confusion if the RFC is not “mapping friendly”.
I can create all five entities with one import.


Ignore the inputs and choose the five collections from outputs.
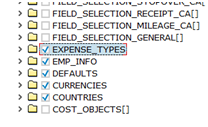
Mark a key set within each entity block.

Returned entities need to be renamed (they are upper case and refer to multiples in some cases).


Create the sets.
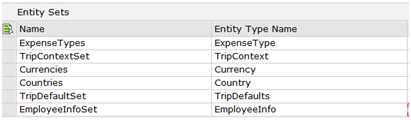
Create associations from TripContext to each of the options collections.

Finally, assign navigation properties to TripContext. Referential constraints are not required and could not be maintained in any case.

With the right implementation, I can now obtain all of the five sets of options with one request.
TripContextSet(PersonID='00000005',Language='EN',TripDate=datetime'2013-10-01T00:00:00.0000000')?$expand=Defaults,TripEmployeeInfo,TripExpenseTypes,TripCountries,TripCurrencies
Explanations:
TripContextSet(PersonID='00000005',Language='EN',TripDate=datetime'2013-10-01T00:00:00.0000000')
The primary entity is the TripContext. The values that I use to GET the entity are actually used to establish the context, i.e. these values become known to the data provider as the initial phase of the request. The entity itself does not exist, it is a “state directive”; it is stating “this is the person in question and this is the date and language that may affect the outcome”. I do not need to access any further data in relation to this entity data, and the returned entity is the same as the request key.
The trick here is that I have now established the input for the following entities that I wish to obtain.
$expand=Defaults,TripEmployeeInfo,TripExpenseTypes,TripCountries,TripCurrencies
The expand option will locate each of the endpoints of the navigation properties that I defined. In the case of Defaults and TripEmployeeInfo, these are single entity feeds (cardinality 1:1) and the corresponding ‘GET_ENTITY’ method will be called. For the remainder, the corresponding ‘GET_ENTITYSET’ methods will be called.
Data Provider logic
I’ll make some assumptions for my DPC class.
- I’ll only ever want to access a single entity of type TripContext; no collection logic is required.
- I’ll only ever want to access TripContext in order to provide the context for an expanded feed. The return form this request is pointless without an expand option.
- None of the trip options feeds will work unless the TripContext has been established.
- The more expanded elements per request, the more efficient the provider is; however the returned feeds must be required for consumption for this to hold true!
Based on the above assumptions, I can introduce some efficiency.
When TripContext is requested, what is really being requested are the trip options that fit into that context. At this point (TRIPCONTEXT_GET_ENTITY) it would be a good idea to call the BAPI, as we have the input values for it.
There is a slight problem here – the returned data from the BAPI isn’t required just now, the return feed is a TripContext. However I do know that the DPC is going to continue running during this RFC connection; the $expand option is going to invoke calls of the other GET methods.
I’ve got the entity data for those feeds already – so I’m going to store them.
In order to separate the concerns somewhat, I create an access layer class to manage the trip options.
The trip options manager object is then attached to my DPC as an attribute. It reads the BAPI and stores the results in its object space.
When I reach the second (implied by $expand) GET in the process, I can now ask the trip options manager to give me the return data.
I repeat this for each expected feed.
Improved?
I consider this a much better implementation of an inside-out design. A typical implementation of this service, solely based on the BAPI, would not have been very elegant, efficient or as simple to consume.
What could have been a very inefficient and cumbersome implementation is now well-scaled and fairly simple. In traced tests this service can return the full feed in under 100 milliseconds.
However, it still reads more data than required and could be written even more efficiently using the outside-in modelling approach. I intend to tackle this same scenario in an outside-in manner in a future blog.
Regards
Ron.
- SAP Managed Tags:
- SAP Gateway
26 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
4 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
1 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
11 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
2 -
Capgemini
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
3 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
Cyber Security
2 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
Digital Transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
5 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
1 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
Research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
1 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
20 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
5 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
1 -
SAP CDC
1 -
SAP CDP
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP SuccessFactors
2 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
SuccessFactors
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Tips and tricks
2 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Vector Database
1 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q4/2023) in Technology Blogs by SAP
- Partner-2-partner collaboration in the construction industry in Technology Blogs by SAP
- Details of SAP Data and Analytics Advisory Methodology Phase II (Business Outcomes & Solution Req.) in Technology Blogs by SAP
- Sneak Peek in to SAP Analytics Cloud release for Q1 2024 in Technology Blogs by SAP
- Replication Flow Blog Series Part 4 - Sizing in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 8 | |
| 8 | |
| 7 | |
| 6 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 |