翻译自:SAP HANA Text Analysis
随着SPS05的发表,SAP实施了一定程度的改变,并且发布了一系列新功能。其中一些功能是许多程序员翘首以盼的,像是debug的功能(终于出现了!)。但是从我的角度来说,SPS05里最酷的功能就是文本分析。这项新功能的主要目的是从文本里提取有用的信息。换句话来说,公司现在可以处理大量数据源并且从中提取有用的信息而不用读任何一句话。那么,什么才是有用的信息呢?提取的过程会从非正式组成的数据中认定“谁”、“什么”、“哪”和“多少”,这使你可以增多你的结构数据。
如果你想深入地了解它是怎么运作的,你需要参照SAP HANA用户指导“
“文本分析提供了许多可能的entity种类,以及20种语言编写的的许多产业的分析法则。但是,当你分析你自己的文件集合时,并不需要处理这些繁琐的工序。软件中的语言模块包含了系统字典并且提供了大量的预先定义的entity种类。提取的过程可以用这些特定的entity序列来提取entity。它还可以使用语言模块来发现新的entity。提取的过程可以将每个提取的entity根据种类分类,并且用标准方式呈现数据。”
文本分析中最令人满意的就是容易操纵。接下来我会带你了解我的操纵步骤。
首先,我创建了一个非常简单的包含列的表,像这样:
CREATE COLUMN TABLE "PRESS_RELEASES" (
"File_Name" NVARCHAR(20),
"File_Content" BLOB ST_MEMORY_LOB,
PRIMARY KEY ("File_Name"));
在这个表里,我将会存进去一些PDF文件,包含美国航空行业的信息。为了实现这一点,我写了一段非常简单的python语句,它们在BLOB域(“File_Content”)储存着PDF文件:
- con = dbapi.connect(‘hanahost', 30015, 'SYSTEM', '********') #Open connection to SAP HANA
- cur = con.cursor() #Open a cursor
- file = open('doc.pdf', 'rb') #Open file in read-only and binary
- content = file.read() #Save the content of the file in a variable
- cur.execute("INSERT INTO PRESS_RELEASES VALUES(?,?)", ('doc.pdf',content)) #Save the content to the table
- file.close() #Close the file
- cur.close() #Close the cursor
- con.close() #Close the connection
现在我的表里有着非正式组成的数据供我开始文本分析。我唯一需要做的是运行以下语句:
Create FullText Index "PDF_FTI" On "PRESS_RELEASES"("File_Content")
TEXT ANALYSIS ON
CONFIGURATION 'EXTRACTION_CORE';
我现在要做的是在“PRESS_RELEASES”表BLOB的“File_Content”列创建一个完全的文本索引叫做“PDF——FIT”(你可以使用任何其他的名字)。我还提到,我会打开文本分析,然后我会使用叫做“EXTRACTION_CORE”的配置(你可以参照SAP HANA开发者指导来了解不同的配置)。当这段程序运行的时候,一个叫做“$TA_PDF_FTI($TA_<Index_Name>)”新的列表格出现了,它用来装文本分析返回的结果。表的结构如下表所示:
列名称 | 键 | 描述 | 数据类型 |
File_Name | 是 | 这是表格的主键。如果你的主键有超过一个列,$TA表会包括每一个列 | 像在 source table一样。 在这种情况下: NVARCHAR(20) |
RULE | 是 | 储存出产token的rule包裹。在我的情况里:“提取Entity” | NVARCHAR(200) |
COUNTER | 是 | 计算文件里所有的token | BIGINT |
TOKEN | 否 | 提取的token(“谁”、“什么”、“哪”和“多少”) | NVARCHAR(250) |
LANGUAGE | 否 | 在创建fulltext指数时你可以指定一个语言列,或者它从文本中得到。在我的情况下,它是从文本中取得的,并且是英文 | NVARCHAR(2) |
TYPE | 否 | Token的种类,无论是“谁”、“什么”、“哪”或“多少” | NVARCHAR(100) |
NORMALIZED | 否 | 储存token标准化的陈述。这是很相关的,例如对于德国的元音变音,或ß/ss。在标准化中,首字母大写不如整理这个列。 | NVARCHAR(250) |
STEM | 否 | 储存语言信息,例如名词的单数主格,或者动词指代。如果文本分析出产了一定数量的stem,只有第一个stem会被储存,默认这个是最佳匹配。 | NVARCHAR(300) |
PARAGRAPH | 否 | 文章中含有我的token的段落数量 | INTEGER |
SENTENCE | 否 | 文章中含有我的token的句子数量 | INTEGER |
CREATED_AT | 否 | 创造时间戳 | TIMESTAMP |
这是我$TA表的数据预览:
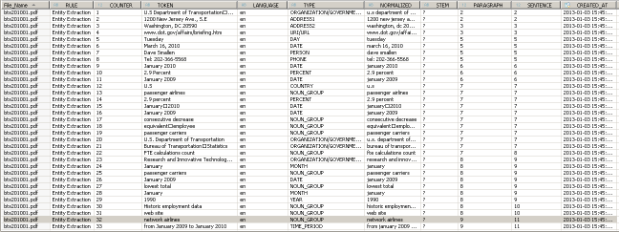
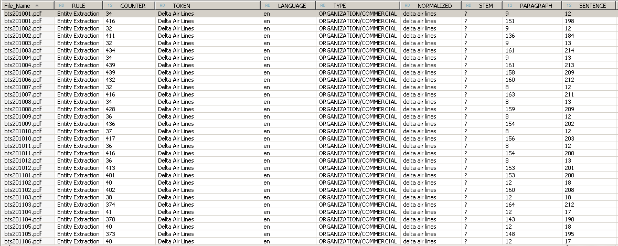
现在,假设我在航空公司工作,例如Delta航空公司,我想要知道我的公司是不是在新闻中被提到。通过过滤列TYPE=‘ORGANIZATION/COMMERCIAL’ 以及 TOKEN = ‘Delta Air Lines’我可以很容易找到答案。像你在下面的屏幕截图中看到的那样,Delta航空在bts201001.pdf文件中被提到两次(段落9和151),在 bts201002.pdf 提到两次(段落9和136)等等。
我生性多疑,所以我希望看到准确的信息。所以我写了段非常简单的XS JavaScript来展现其中一个PDF文件(bts201002.pdf) 的内容。如下所示:
- 1. var conn = $.db.getConnection();
- 2. try {
- 3. var query = "Select \"File_Content\" From \"PRESS_RELEASES\" Where \"File_Name\" = 'bts201002.pdf'";
- 4. var pstmt = conn.prepareStatement(query);
- 5. var rs = pstmt.executeQuery();
- 6. rs.next();
- 7. $.response.headers.set("Content-Disposition", "Content-Disposition: attachment; filename=bts201002.pdf");
- 8. $.response.contentType = 'application/pdf';
- 9. $.response.setBody(rs.getBlob(1));
- 10. $.response.status = $.net.http.OK;
- 11. } catch (e) {
- 12. $.response.setBody("Error while downloading : "+e);
- 13. $.response.status = 500;
- 14. }
- 15. conn.close();

像我文本分析所说的那样,Delta航空在特定段落被提到两次,正式我$TA表所说的地方:
希望这篇文章给大家提供了帮助!
