
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- How to improve the initial load
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-26-2013
10:24 AM
Hi,
we would like to share a expert guide, that describe the procedure to improve the inital load via SLT.
Chapters:
- Introduction
- Access Plan BTC Work Process Requirements
- Which Process Should You Use To Load Large Tables?
- What to know and do before you start
- ECC Source System Preparation
- Netweaver-Based SAP System Landscape Transformation (SLT) Systems
- Load Monitoring
- Process Summary Checklist
- Post Load Considerations
Introduction
This Guides describes how large tables can be loaded via SLT into HANA or also to other targets.
Here are some examples of challenges our customer have in their landscapes:
• Oracle RAC
• Complex table partitioning models for the larger tables. For example, partitioning based on a substring of the last character of a column value
• Oracle database statistics that are ‘frozen’ to remove Oracle CBO operations from the data access model.
• Complex table partitioning models for the larger tables. For example, partitioning based on a substring of the last character of a column value
• Oracle database statistics that are ‘frozen’ to remove Oracle CBO operations from the data access model.
This database architecture was recommended by SAP and has proven to be very effective for the customer.
Challenges from this architectural approach to SLT included:
• Table load rates of, in some cases, only 1 million records per day when we would expect 10 million records per hour per work process.
• The source ECC system was also consuming system-crashing volumes of PSAPTEMP.
• The statistics freeze prevented us from creating indexes for optimized parallel SLT loads.
• The source ECC system was also consuming system-crashing volumes of PSAPTEMP.
• The statistics freeze prevented us from creating indexes for optimized parallel SLT loads.
The solution to this issue is a new approach to configuring and executing SLT loads which is based on accessing data by row ID (Oracle, transparent tables) or primary key (other DB systems, and non-transparent tables for Oracle).
This guide can be used for all SAP NW supported database systems.
Access Plan BTC Work Process Requirements
It is important to understand how your table load approach may impact the need for system resources so that you can avoid resource bottlenecks.
Each access plan job requires one SAP BTC work process on both the SLT and ECC systems.
Each access plan job requires one SAP BTC work process on both the SLT and ECC systems.
Let’s assume that your SLT server has 15 BTC work processes allocated. You have configured via the SLT transaction LTR for a Total work process allocation of 10 with 8 of those 10 allocated for Initial Loads. This leaves 5 available BTC work processes.
A table to be loaded has 106,000,000 records and you want to use the 5 available BTC work processes for the access plan calculations. Using the process highlighted in this document, you could divide the access plans into 25,000,000 records each and these would run in 5 access plan (ACC*) jobs on SLT – which corresponds to 5 access plan (MWB*) jobs on ECC. Entering 25,000,000 in NUMREC will result in 5 jobs – 4 jobs processing 25,000,000 records and the 5th job processing 6,000,000 records - assuming that your record count is correct.
Let’s now assume that you are using ALL of your available BTC work processes on SLT for both SLT (Total/Initial) and access plans. Good job! But now, you want to load other tables. You have available SLT Initial/Total work process capacity but all BTC work processes are busy and so, for any new table loads, THEIR access plans, however small, cannot run. Keep this in mind when allocating your BTC work process resources!
Which Process Should You Use To Load Large Tables?
There are optional methods for loading large cluster and transparent tables. All perform well but each has its own advantages and requirements.
Cluster Tables:
Type-4 Use the process in this guide to load a large cluster table
• Table will be read by primary key
• Additional SAP batch work processes (BTC) will be needed on the source and SLT servers to handle the multiple access plan jobs.
• Table data will be divided into separate access plans by record count (NUMREC in IUUC_PRECALC_OBJ) of the physical (RFBLG, for example) cluster table, not the logical (BSEG,for example) cluster table.
• Be careful not to create too many access plans, as all of them need to be processed by yet another batch job in the sender system. As a maximum, use 8 access plans.
• Requires use of table DMC_INDXCL on source ECC system
• Simple configuration
• Additional SAP batch work processes (BTC) will be needed on the source and SLT servers to handle the multiple access plan jobs.
• Table data will be divided into separate access plans by record count (NUMREC in IUUC_PRECALC_OBJ) of the physical (RFBLG, for example) cluster table, not the logical (BSEG,for example) cluster table.
• Be careful not to create too many access plans, as all of them need to be processed by yet another batch job in the sender system. As a maximum, use 8 access plans.
• Requires use of table DMC_INDXCL on source ECC system
• Simple configuration
Type-4 Manual Delimitation Process
• Table data will be divided into separate access plans by specific select criteria (delimitations) for the given table. You have more control over the ranges of data and access plan count.
• Normally not needed, unless you not only want to parallelize the processing but also want to restrict the set of data to be processed, for example, by filtering for a certain organizational unit, or fiscal year, etc.
• Requires use of table DMC_INDXCL on source ECC system
• More complex configuration steps – contact SAP support
• Normally not needed, unless you not only want to parallelize the processing but also want to restrict the set of data to be processed, for example, by filtering for a certain organizational unit, or fiscal year, etc.
• Requires use of table DMC_INDXCL on source ECC system
• More complex configuration steps – contact SAP support
Transparent Tables:
Type-5 Use the process in this guide to load a large transparent table
• Additional SAP batch work processes (BTC) will be needed on the source and SLT servers to handle the multiple access plan jobs.
• Table data will be divided into separate access plans by record count (NUMREC in IUUC_PRECALC_OBJ). For each of them, another batch job will run in the sender system, each of them doing a full table scan of the table.
• Requires use of table DMC_INDXCL on source ECC system
• Simple configuration
• Table data will be divided into separate access plans by record count (NUMREC in IUUC_PRECALC_OBJ). For each of them, another batch job will run in the sender system, each of them doing a full table scan of the table.
• Requires use of table DMC_INDXCL on source ECC system
• Simple configuration
Type-1 – with index on source system
• Customer must create a single-field index on source ECC system. This index is only required for the initial loadand may be deleted after the load.
• Does NOT require use of DMC_INDXCL on source ECC system
• Simple configuration
• Like the standard reading type 3, this type creates more system load on the sender system, compared to reading types 4 and 5.
What to know and do before you start
- May need to request storage and tablespace from customer
- Add security profile S_BTCH_ADMIN to your SLT CPIC user on the source ECC system. Sometimes, depending on Basis SP, the user will not automatically have the ability to release batch jobs and so your SLT access plan jobs will just sit there waiting to be manually released. Therefore, make sure that you obtain the latest version of role SAP_IUUC_REPL_REMOTE and assign it to the user assigned to the rfc destination pointing from the SLT system to the source system. You can get this role from note 1817026.
- Oracle and ASSM issues - Oracle 10.2.0.4 has issues with LOB tables which will impact inserts – they hang – to table DMC_INDXCL. See note 1166242 for the work around: alter table SAPR3.DMC_INDXCL modify lob (CLUSTD) (pctversion 10);
ECC Source System Preparation
- Minimum DMIS SP: DMIS 2010 SP07 or DMIS 2011 SP02. It is much better to go with the most recent release of DMIS SP.
- For DMIS 2010 SP07 or DMIS 2011 SP02, ensure that note 1745666 is applied via SNOTE
Note: The corrections of this note is included in DMIS 2010 SP08 and DMIS 2011 SP03. - For DMIS 2010 SP07 or DMIS 2011 SP02: Ensure that note 1751368 is applied via SNOTE.
Netweaver-Based SAP System Landscape Transformation (SLT) Systems
- SLT: Minimum DMIS SP: DMIS 2010 SP07 or DMIS 2011 SP02.
- For DMIS 2010 SP07 or DMIS 2011 SP02: Ensure that note 1745666 and 1751368 are applied via SNOTE.
- For DMIS 2010 SP08 or DMIS 2011 SP03: Ensure that all notes listed in Note 1759156 - Installation/Upgrade SLT - DMIS 2011 SP3 / 2010 SP8 are applied and current.
- SLT: Add entry to table IUUC_PRECALC_OBJ
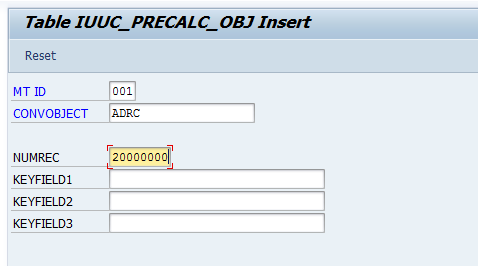
NUMREC: The number of records to be processed per access plan work process. Let’s say that we have 108,000,000 records and we want to use 5 access plan (ACC*) jobs on SLT – which corresponds to 5 access plan (MWB*) jobs on ECC. Entering 20,000,000 in NUMREC will result in 6 jobs, 5 of them handling 20M records each, the last one dealing with the remaining 8M records. So you could also specify 22,000,000 as value, in order to have a more even distribution among only 5 jobs.
Cluster Tables: NUMREC refers to the record count from the physical cluster table (RFBLG, for example), not the logical cluster table (BSEG, for example).
NUMREC should be chosen in such a way that, if the delimitation must be done using the primary key (DB other than Oracle, or cluster or pool table), not more than around 8 subsets (access plans) will be created. Keep in mind that in this case, each job will be a full table scan of the complete table, which is not very efficient if done by a large number of jobs. On the other hand, in case of Oracle ROWID parallelization, you can allow more parallel jobs, because each job will only process its specific ROWID range, rather than doing a real full table scan.
This table also includes 3 KEYFIELD columns. These can be ignored.
- SLT: Add entry to table IUUC_PERF_OPTION

parall jobs: Number of load jobs. This is the maximum number of jobs that might run in parallel for this table, both in the access plan calculation, and in the load.
Sequence number: Controls the priority of the jobs (lower number – higher priority). Usually 20 is a good value.
Reading Type:
• Cluster Table: Type 4 -> “ INDX CLUSTER (IMPORT FROM DB)”
• Transparent Table: Type 5 -> “INDX CLUSTER with FULL TABLE SCAN”
• Transparent Table: Type 5 -> “INDX CLUSTER with FULL TABLE SCAN”
NOTE: The labels change between DMIS releases/patches.
- HANA: Select table for REPLICATION in Data Provisioning
- ECC: Review Transaction SM37
• Job DMC_DL_<TABNAME> should be running (Oracle transparent tables only). Job name for all other tables/databases would start with /1CADMC/CALC_, followed by the respective table name.
• Once this job is finished, one MWBACPLCALC_Z_<table name>_<mt id> should be running.

Starting from DMIS 2011 SP5, the job names will start with /1LT/IUC_CALCSACP and also include mass transfer ID and table name.
- SLT: Review Transaction SM37
- Job ACC_PLAN_CALC_001_01 is running (Starting from DMIS 2011 SP5, the job names will be /1LT/MWB_CALCCACP_<mass transfer ID> )
Ideally, more than 1 ACC_PLAN_CALC_001_0 job should be run as soon as the first job preparing the precalculation (DMC_DL_<TABNAME>) has finished. But only the number of access plan jobs you specified in the configuration will be started automatically. Starting more, up to the intended parallelization value, has to be done manually.
Assuming that one 1 ACC job is already running, the screen below shows how you would run a total of 6 jobs concurrently.
In the older Support Packages, we normally provide only one job for the access plan calculation step. Starting with DMIS 2011 SP4, or DMIS 2010 SP9, a more flexible control of the calculation jobs is available. You can use transaction MWBMON - Steps Calculate Access Plan to schedule more jobs. In the ADRC example, with five parallel jobs, the screen would look as below. However, you need to make sure that the value in field TABLE_MAX_PARALL in table DMC_MT_TABLES is set accordingly, to allow this degree of parallelization, by providing this value in field parall_jobs when maintaining IUUC_PERF_OPTION, as shown above.
You can check which access plans are being processed in table DMC_ACS_PLAN_HDR (OWNER guid field of the corresponding records point to field GUID of DMC_PREC_HDR, the OWNER guid of which in turn points to DMC_MT_TABLES-COBJ_GUID).
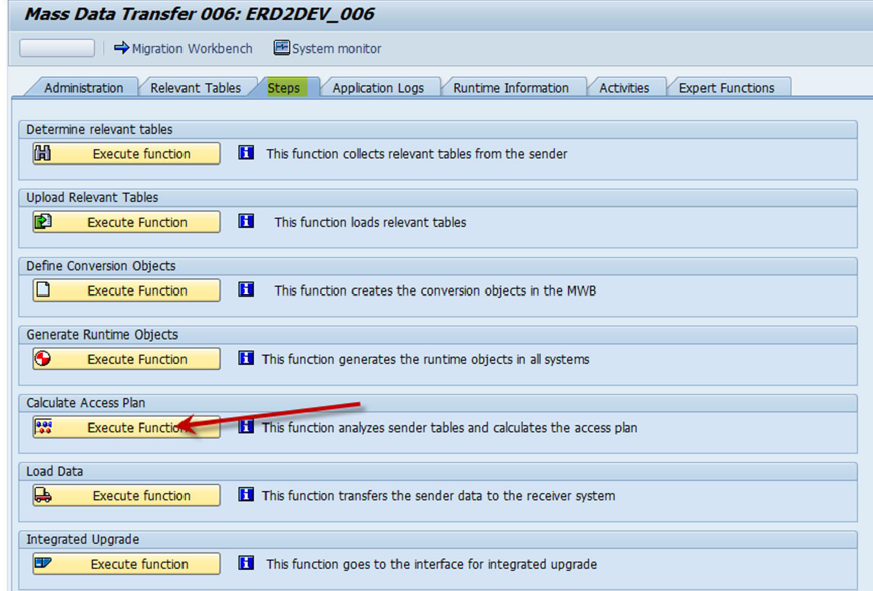

How to use the screen above to manage job count:
• We have 1 job already running. To set “Number of jobs to be scheduled” to ‘3’ is translated to starting 3 additional ACC* jobs.
• If we also select the check box for “Restart”, we are saying that we want a total of ‘3’ jobs to run and so 2 additional ACC* jobs would start.
• Assuming that we have 8 concurrent jobs and we want to reduce the count to 6: Specify 6 in the “Number of jobs to be scheduled” field, select the check box for “Restart”. As access plan jobs complete, new jobs will not be started and ultimately, only 6 jobs will run concurrently.
Load Monitoring
- SLT: Standard MWBMON processes
- ECC: SM21/ST22/SM66
- ECC: Review Transaction SM37
- Review job log for MWBACPLCALC_Z_<table name>_<mt id> to monitor record count and progress:

Process Summary Checklist
- SLT: Created entry in IUUC_PRECALC_OBJ
- SLT: Created entry in IUUC_PERF_OPTION
- SLT: SLT batch jobs are running.
- HANA: Table submitted from HANA Data Provisioning
- ECC: Job DMC_DL_<table_name> is running
- SLT: ACC* batch job is running
- ECC: Job DMC* started/finished and job MWBACPLCALC_Z_<table_name>_<mt_id> started
- SLT: All ACC* batch jobs completed
- ECC: All MWB* batch jobs completed
- SLT: Table loading (MWBMON)
- HANA: Table loaded and in replication
Post Load Considerations
After the load has completed, it is good manners to clean up DMC_INDXCL on the ECC system and remove the table data. Starting with DMIS 2011 SP4, or DMIS 2010 SP9 this is done automatically, with older SPs, you should to it manually.
On Source System:
Review your data in the DMC cluster table:
Select * from <schema>.dmc_cluptr order by 1,2,3 where convobj_id=’Z_KONV_001’
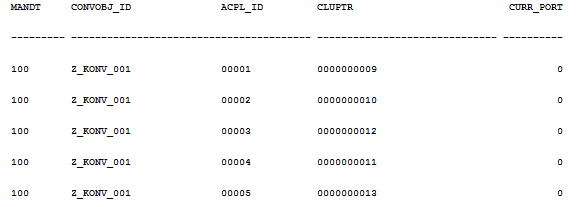
SE38->DMC_DELETE_CLUSTER_POINTER

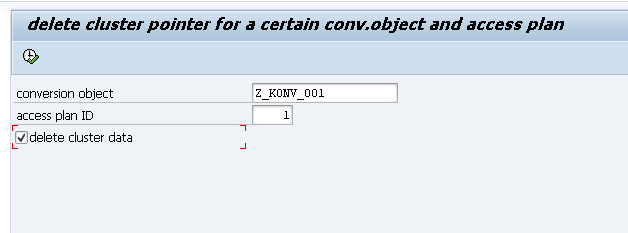
- The conversion object is the same as is listed in DMC_COBJ->IDENT on the SLT server.
- Access plan ID is listed in select statement above. Run this command for 00001-00005.
- Select 'delete cluster data'
- There is no output. If it does not fail, then it worked.
This is a techical expert guide provided by development. Please feel free to share your feelings and feedback.
Best,
Tobias
- SAP Managed Tags:
- SAP HANA,
- SAP Landscape Transformation replication server
14 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
12 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
340 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
417 -
Workload Fluctuations
1
Related Content
- SAP Datasphere Replication Flow Partition Issue in Technology Q&A
- SAP Analytics Cloud - Performance statistics and zero records in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- What’s New in SAP Datasphere Version 2024.8 — Apr 11, 2024 in Technology Blogs by Members
- Unlocking Full-Stack Potential using SAP build code - Part 1 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 33 | |
| 25 | |
| 10 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |