Business senario:
When loading hierarchy master data from BW InfoObj you get an error similar to: "Detected duplicate member ID 'xxxxxx' "
Assumption:
You have successfully completed the first step of loading the master data and text together with hierarchy nodes into BPC which implies:
1. All master data required for the hierarchy exists in the BPC dimension
2. There are no duplicate ID's in your dimension members in BPC. (This is in fact not possible since BPC will not save and process duplicate dimension members so the error does not lie in your dimension.)
Interpreting the PACKAGE STATUS
1. A duplicate ID error always indicates an issue with the reading and converting of data resulting in the error and not the fact that the ID already exists in your BPC dimension members. The OVERWRITE and UPDATE option control the destination but the error is specific to the read and convert task.
2. Pay particular attention to where the error is occuring. When you look at the PACKAGE STATUS notice the various TASK headings under which the error occurs. 5 Tasks are being executed MASTER DATA SOURCE, TEXT SOURCE, CONVERT, MASTER DATA TARGET and TXT DATA TARGET.
a) The most basic result is the reading of base data and text nodes for the hiearchy. The result shown below indicates that although there is success the hierarchy nodes were not selected because the text source = master data source i.e. NO text nodes selected. You immediately know your data selection options are not correct. Try using a selection of attribute selection, hiearchy selection and "OR" selection to read the hiearchy nodes. Make sure delimeter is set to TAB and HEADER is YES.
Task name MASTER DATA SOURCE:
Record count: 3
Task name TEXT SOURCE:
Record count: 3
Task name CONVERT:
No 1 Round:
Reject count: 0
Record count: 3
Skip count: 0
Accept count: 3
Task name MASTER DATA TARGET:
Submit count: 3
Task name TXT DATA TARGET:
Submit count: 3
model: XXXX. Package status: SUCCESS
b) A result like this indicates that although the selection was correct i.e. 3 base members and 1 hierarchy text node the text node was not written to BPC because there was a problem with the conversion settings. 4 Text nodes were available for writing but only 3 were written i.e. only the base members.
Task name MASTER DATA SOURCE:
Record count: 3
Task name TEXT SOURCE:
Record count: 4
Task name CONVERT:
No 1 Round:
Reject count: 0
Record count: 3
Skip count: 0
Accept count: 3
Task name MASTER DATA TARGET:
Submit count: 3
Task name TXT DATA TARGET:
Submit count: 3
model: XXXX. Package status: SUCCESS
c) A result like this indicates success. Both selection and convertion settings were correct and both base members and text nodes were written to BPC in preparation for importing the hierarchy.
Task name MASTER DATA SOURCE:
Record count: 4
Task name TEXT SOURCE:
Record count: 4
Task name CONVERT:
No 1 Round:
Reject count: 0
Record count: 4
Skip count: 0
Accept count: 4
Task name MASTER DATA TARGET:
Submit count: 4
Task name TXT DATA TARGET:
Submit count: 4
model: XXXX. Package status: SUCCESS
How can I tell which records have been updated?
You can use a simple technique of adding a property to the dimension called "CHANGE_ID" and in the *MAPPING section add a line CHANGE_ID=*STR(20130831_1200) which is a hard-coded date + time you maintain manually just before you run the package. If the package is successful you can sort or filter the dimension members on this property.
Possible errors:
1. The source data does not have duplicate records but syntax in your *MAPPING section of the transformation file or conversion file is causing the creation of a duplicate record. e.g. Consider two Cost Centre numbers like 0000012300 and 0001230000. They will appear as different nodes in the BW hierarchy but your conversion routine for eliminating leading/trailing zero's may be faulty and creating an identical destination ID. This becomes aggrevated when the source ID is more complex and may contain segments and alphanumeric characters.
2. A common problem would be a compounded BW characteristic like 0GL_ACCOUNT or 0COSTCENTER or 0COSTELMNT. In the source there could be two identical ID's belonging to different compounding characteristics which you have not accounted for in your translation.
3. Notice in the error message below that it reads "Dimension member is an invalid member ID". There is an extra space between "member" and "is". It is very common practice in planning data to have a BLANK ID in BW even if it is a compounded characteristic. Make sure you cater for eliminating this in your conversion. A statement like this in your *MAPPING section can help: ID=*IF(ID=*STR() THEN *STR(XXXX);ID=*STR() THEN *STR(XXXX);ID) i.e. direct the blank member to an equivalent value in BPC.
Task name MASTER DATA SOURCE:
Record count: 2935
Task name TEXT SOURCE:
Record count: 2970
Task name CONVERT:
No 1 Round:
Error in Admin module or a component used by Admin module
Dimension member is an invalid member ID
model: XXXX. Package status: ERROR

4. There might be a technical error on the hierarchy in BW. Check by following these steps:
a) Select the characteristic in BW and double-click
b) In the menu select EDIT --> ANALYZE INFOOBJECT
c) Double-click the CHECK INDIVIDUAL HIERARCHY test to select it in the right part of the window
d) Click on the test once it is in the right selection box and enter the hiearchy name you want to check
e) Execute the test and correct any error that might appear
5. The error message may be correct. BW hierarchies allow nodes to be of various types. They can be text nodes, nodes of the same characteristic type you are sourcing or even nodes of a different characteristic. BW also allows the same characteristic to be inserted multiple times under different nodes in a hierarchy. This being the case the translation & convesion routine could be deriving duplicate destination ID's and unable to write the result.
Finding the problem node can be difficult. In a large hiearchy there is no search facility in RSA1 under hierarchies to sort and find the problem ID reported by BPC.
One alternative could be the following:
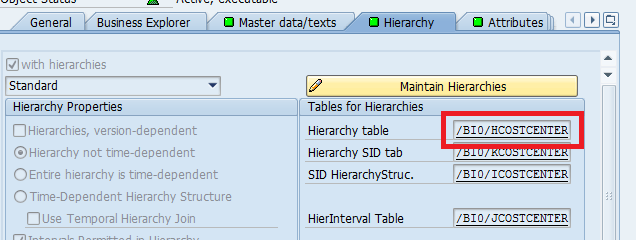
1. In RSA1 goto the characteristic and double-click it to display the maintenance screen. Click on the "Hieararchy" tab.
2. Double-click the Hierarchy table
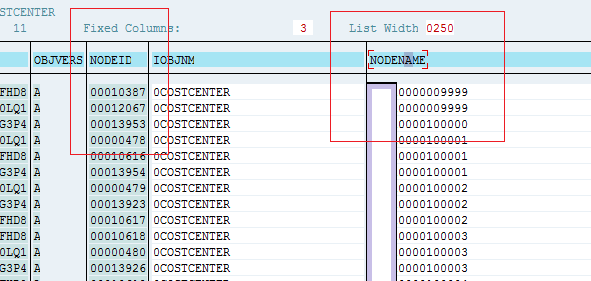
3. Click on the "Contents" icon. Remove the "Maximum No. of Hits" and display.
4. Now sort by NODENAME and find the ID which is duplicated.
5. The NODEID can be recorded so in a very large hierarchy there is no need to manually try to find the duplicate.
6. Go back to the hierarchy maintenance screen and lookup the NODEID. Use (1) to display the technical ID and use (2) to search the NODEID. This will take you to the exact place in the hiearchy where the duplicates reside.