
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Data Profiling and Data Cleansing - The initial st...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-12-2013
8:43 AM
This blog is the starting point for a series of blog articles of a guest lecture at the Hasso-Plattner-Institut für Softwaresystemtechnik in Potsdam, Germany.
Within the first part (http://scn.sap.com/community/enterprise-information-management/blog/2013/06/12/data-profiling-and-da... ) of this three article series I talked about the general concepts of Total Data Quality Management and some of the most common use cases that are applying these concepts.
I also presented the process wheel for a Total Data Quality Management initiative, including the following six implementable steps:
- Discover your enterprises data assets to get a clear understanding where your data is stored within the organization and how it is moved and consumed as well as look deeper into the systems and tables to get also first insight of the content of your d ata containers.
- Define your data standards, data policies, data qualty requirements to set the goal or target where you what to go with your data qualt management initiative. Also use this definition phase to define a common business term glossary to ensure that everyone within the company is talking about the same thing avoiding unnecessary and painfull missunderstanding
- Assess the existing sthe currently level of data quality based on the data standards and validation rules that you have setdefined, approved by your data stewar or business experts and bound to the data sources. Get away from rule of thumb or stomach feeling about the quality level of your data. Put figures and numbers to the to the data quality questions so you have some measures that allow you to prioritize also your upcoming cleansing strategy.
- Analyze the root cause of your identified bad data as well as identify the impact of the bad data to further downstream systems like from the data warehouse staging area to your individual reports. The data quality issue root cause analysis is an important piece to understand where e.g. in your operational system bad data is stored, that is then moved to your data warehouse data warehouse b the ETL processes.
- Improve your data quality by defining the right data cleansing strategy. After you are aware of the root causes of your bad data quality, decide on where, when and how to take action. Set up the data quality firewall for your systems and applications to avoid that any new data entering your systems is not compliant with your requirements. Be it transactional , real-time entry of data by employees or customer self services or batch loading processes of external data or sources. Also define your cleansing strategy for the existing data by internal batch processes.
- Monitor your data quality constantly. Apply your data validation rules to your data sources on a regular schedule to get a historical trend analysis and see how your data quality scores change over time. Prove the benefit (and cost) of data cleansing or improvement activites by showing the increase of data quality on the scorecards. React early and proactively on slight decreases of your given data quality scores, even before your employees or even worser your suppliers or customerare unhappy and dissatisfied.

Obviously a Total Data Quality Management initiative never ends, it is an ongoing project, so you will continue following the circle, as potentially new data sources are created within your system landscape, maybe through merger & acquisition projects, or further roll-out of the initiative scope to other data domains, or your organizations data quality requirements are changing over time, new external regulations or federal laws enforce further policies, and also take care that the real world is changing over time, when e.g. every year a significant percentage of your customer base is just relocating and moving to a new address.
Based on this introduction of the circle of Total Data Quality Management, let me give you some more details on the initial three steps that enable you to get clear transparency on your existing data assets within the organization, how they are related to each other and how good or bad the data quality level of your existing data really is.
Discover, understand and centrally catalog your enterprise data
The first step in your Total Data Quality Management initiative is to discovery of the existing data assets within your system landscape. By integrating the technical metadata information of your BI Solutions, ETl tools, relational database systems, data modeling tool, etc. into one central metadata repository and creating the relationships between the technical objects a searchable catalog of all data assets is created and provides data lineage and impact analysis visualization by liking the data mappings and relationships from the data sources all the way down to the end reports or further downstream applications.

In addition to the insight into the technical metadata information, as a next step it is helpful to also take a look into the columns and records that are stored within the tables and files. Getting the information that field 25 is having the label "PO Box" is fine, but only when using the basic profiling capabilities you can get the insight what is really stored in this colum. The Basic profiling provides the data analyst with a set of statistical information on the column's content like the minimum and the maximum values, minimum and maximum string length, percentage of empty or NULL value fields and frequency distribution information of field content, field format or words in the fields. Quite a small number of additional information about the data (you might call the profiling results also metadata information) but very powerful. When you have a phone number field and your minimum value represents "1 800 4352 5698" and your maximum value represents "999-9999-9999" you might already have identified two outlines that you want to follow up with a data quality validation rule, one on defining that your phone numbers need to always have a international phone number format with a leading country code number, the other to check for these typical dummy phone numbers. Or when your maximum string length of a field equals the defined field length of the field, this is the perfect candidate of including trimmed or cut off content e.g. when during a data migration or batch load process, the source field has been longer than the target field.

Beyond the single column profiling, the dependency, redundancy and uniqueness profiling provides insight how multiple columns or records are related to each other and have dependencies. So you can quickly check of all the products referenced in your sales order table are also existing in your product master table and vice versa, if there are products existing that your sales team has never sold. All visible in a Venn diagram showing the intersection of the product ids and the number of not overlapping product ids.
A very recent extension of SAP Information Steward provides the capability of Semantic Profiling or Content type discovery. Based on an extensive knowledge base with reference data information, the solution provides best guess, suggestions on what kind of party data (first name, last name, city, country, ...) can be identified within a column of a table, all based on the statistical analysis of the content of the field. Theses findings are by the way also core information for the Data Quality Advisor a tool that supports business users to set up a data cleansing batch job with wizard support to walk through data cleansing, address cleansing and matching setup, where based on the outcome of the semantic profiling validation and cleansing rules are automatically suggested for the identified content types.
Define your information policies
For successful information management projects it is essential that everyone within the organization is having the same understanding and definition of technical terms and business terms. When you talk to five employees of your company from different departments about the definition of the term "Revenue" it is very likely you get five different definitions. That said, it is absolutely essential that you set up a central glossary for your organization that includes business terms, their exact definition and description, who is responsible for approval and changes of the terms and so on. As your information governance project will bring together technical and business guys, your business terms need to be associated to the technical metadata information like tables, columns, or other technical objects, to describe these objects from a pure technical as well as from a business perspective. SAP Information Steward enables organizations to centrally create, manage and associate business terms and their definition to collected technical metadata objects and cross-link these terms for reference and easy search and lookup functionalities.
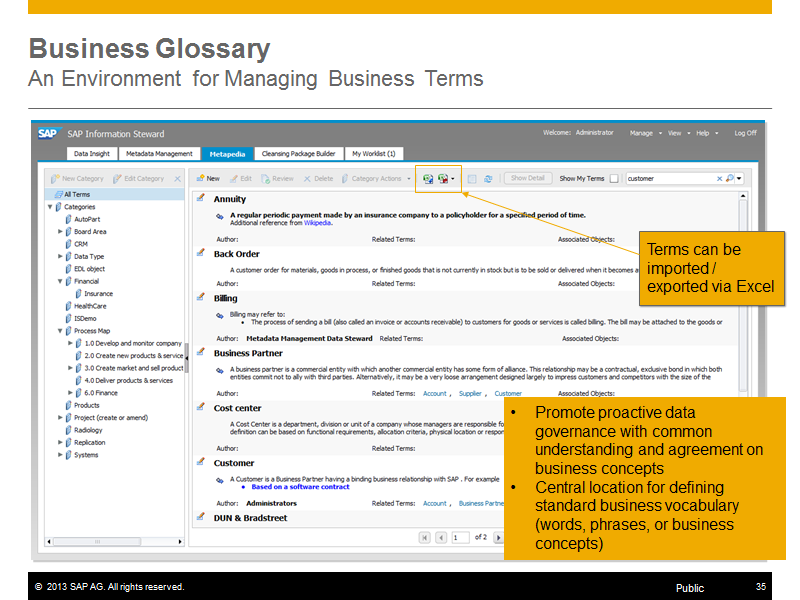
Beyond solving the "Esperanto" in the terminology and definitions, the other big area of policies and standards is around the central definition of the existing data quality requirements. Based on externally given regulations, organizations own standards and requirements or on the findings within the data profiling activities on the own data organizations will set up and centrally maintain their data validation rules representing their core requirements on their most valuable assets, their data. SAP Information Steward validation rules are centrally defined, approved by the responsible data stewards or business experts and then bound to the individual data objects (tables or files) that contain the relevant fields or columns. A validation rule for the valid telephone number format is defined and approved only once representing the organization wide data quality requirement and will then be bound to the customer, supplier, employee and marketing database for execution and calculation of the data quality score.

Assess your overall data quality
After the validation rules have been defined and bound to the specific tables, it is time to execute the so called rule tasks which can be executed immediately or also be scheduled to be e.g. executed overnight. Within a rule task, the tables views or files are selected for which the new data quality scores should be calculated. During the rule task execution all records are checked against the validation rules bound to the tables, views or files. Based on the number of failed records for every rule, the basic data quality scores are calculated. SAP Information Steward offers different perspectives to view the results of the data quality assessment. Technical users from IT can drill down from a data source or database level into the individual tables, columns in the tables and rules bound to the columns to understand how good or bad the database systems are. Business users responsible for specific areas or validation rules can view the data quality scores for their validation rules and drill down to the individual tables, views or files, where the rules have been bound to.

With these first three steps of the circle of Total Data Quality Management, you are reaching the point, where you can always quickly answer the question about your current state of data quality with figures and numbers rather than just stomach feeling or fuzzy numbers and feelings.
Within the SAP Information Steward Product Tutorials available here Learning Information Steward on the SAP Customer Network, you can find helpful click-through demos how the first three steps of your Total Data Quality Management initiative are supported by SAP Information Steward.
Stay tuned for the third part of this article series, where I will talk about the ways how you can analyze the root cause systems for your bad data and also the impact of your bad data on further downstream applications and systems lie, e.g. your reporting landscape. With this information you will be able to define and prioritize your data cleansing activities and data quality firewall setup to ensure your data is getting clean once and stays clean over time. And at the end I will talk about the need for ongoing data quality monitoring to not only be able to view and track the increasing data quality scores after you have defined your data cleansing actions and justify the invest, but also to be alerted early when the data quality is slowly decreasing, being able to react before your customers are blaming your organization for bad data or your employees stop working with your data because they are losing the confidence into the data.
Related links including detailed Product Tutorials:
- SAP Managed Tags:
- SAP Data Quality Management,
- SAP Data Services,
- SAP Information Steward
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
324 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
402 -
Workload Fluctuations
1
Related Content
- Empowering Retail Business with a Seamless Data Migration to SAP S/4HANA in Technology Blogs by Members
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- GRC Risk Management Series: Risk Analysis profile in Technology Blogs by Members
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- What are the use cases of SAP Datasphere over SAP BW4/HANA in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 4 |