Datasets often include many columns and it is a challenge to focus on the ones that are most relevant for a certain analysis. Hence the elimination of irrelevant columns helps simplifying the task and helps producing better results. Such elemination of columns, that can also be called variables or attributes, is often called feature selection.
The Chi Squared Test of Independence is a common approach to eliminate individual variables. It tests whether there is a significant association between two categorical variables or whether the distribution of data appears to be as expected (proportional). If there is no association, then this indicates that a column can probably be eliminated.
To give an example, imagine we want to find predictors for people's voting habits. The Chi Squared Test of Independence can now indicate whether the gender for instance (first factor variable) has an impact on the party voted for (second factor variable). If the variables are independent, then the male and female voters have the same voting pattern and we can eliminate the gender as predictor variable. If the variables are not independent, then men and women appear to vote differently and we want to investigate the gender impact further.
The test's null-hypothesis states that the factors are independent. The test's most important output is the p-value, which indicates the probability of the null-hypothesis being true. If the p-value is below the chosen significance (often 0,05) then the null-hypothesis of independent variables has to be rejected in favour of the alternative hypothesis that the variables are indeed dependent. The p-value is one of the fields returned by the Custom R Component described below.
| p-value | Interpretation |
|---|
| < 0.05 | Reject null-hypothesis that variables are independent. |
| >= 0.05 | The null-hypothesis holds and cannot be rejected.. |
During the calculation of the p-value a so called contingency table is created by the algorithm. This table counts the occurance of each combination of the two variables' values. So sticking to the above example, it shows how many votes each party got from male voters and from female voters. The Chi Square Test of Independence should only be used if there are at least 5 occurances of each combination. Each party must have received at least 5 votes from men and 5 votes from women. This component returns the miniumum value of a cell in this table as column called 'Min Occurance Count'. If after the execution of the model you see a value below 5 in this column, you should discard the outcome of the test. You can consider grouping some of the less common combinations into a 'Others' value which will increase the occurance count within the contingency table.
The Custom R Component described below is an implementation of the Chi Square Test of Independence for SAP Predictive Analysis.
Here is an example of working with this component. We take a common business challenge and want to analyse the results of a Marketing campaign. Our aim is to understand what customer characteristics might or might not have had an impact on purchasing a certain product. Our dataset holds information about 1000 people that were contacted during a marketing campaign. We can see some demographic characteristics of those contacts such as age and martial status. The OUTCOME column states whether the person purchased the product we had promoted.

We want to find out now whether there is a dependency between the martial status and whether the person purchased the product.

Running the analysis shows a p-value in exponential notation well below the 0,05 threshhold. The miminum value in the contingency table is 65, so above the 5 that is needed. Therefore we can conclude that the null-hypothesis of independence has to be rejected. The success of the Marketing campaign was different depending on the contact's martial status. Therefore we decide to keep the martial status in our dataset.
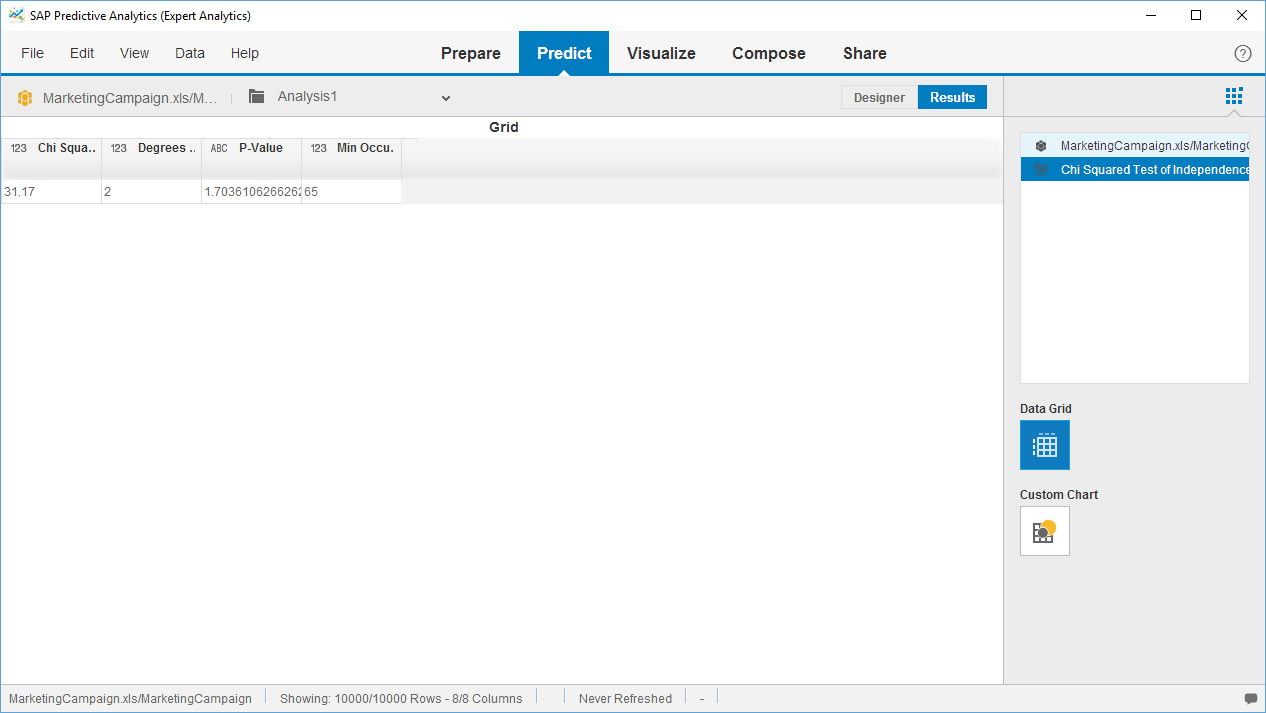
You can click on the 'Charts' tab to see a mosaic plot of the contingency table.

If the miminum value in the contingency table is below 5 you can consider grouping some entities in a common bucket.
How to Implement
The component can be downloaded as .spar file from GitHub. Then deploy it as described here. You just need to import it through the option "Import/Model Component", which you will find by clicking on the plus-sign at the bottom of the list of the available algorithms.
Disclaimer
Please note that this component is not an official release by SAP and that it is provided as-is without any guarantee or support. Please test the component to ensure it works for your purposes.
