Hi,
the load from archives is available as of DMIS 2010 SP7, or DMIS 2011 SP2.
Prerequisite for an archive load is that the tables for which data should be transferred from the archive into HANA have been added to the replication. So this is the very first step.
In the example of archive object SD_VBAK, there are very many tables involved. For simplification, only a small subset of them is selected. This is done, as usual, in the data provisioning UI provided by the HANA studio:
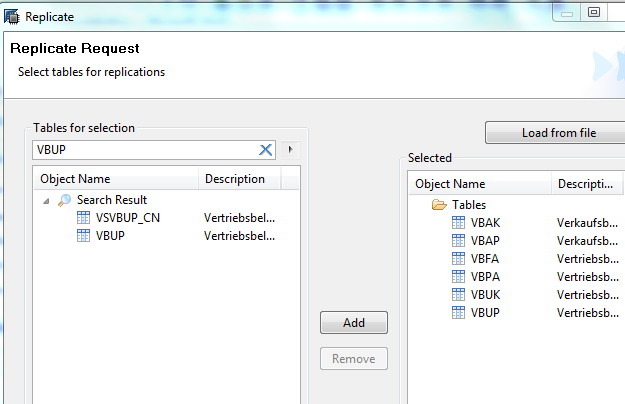
Only if those tables are processed in the normal initial load and replication processing, it is possible to use report IUUC_CREATE_ARCHIVE_OBJECT to define a migration object to load data from the archive.
Usage of report IUUC_CREATE_ARCHIVE_OBJECT is explained in its online documentation. In our example, the parameters would be supplied as shown below:
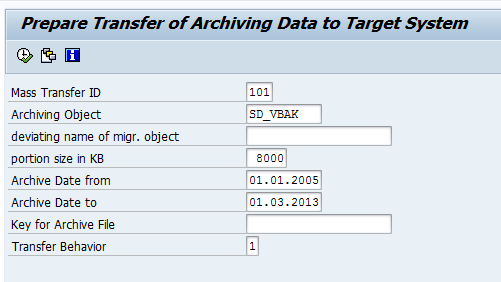
The mass transfer ID to be specified here is the one assigned to the respective HANA replication configuration and can be seen from the WebDynpro started with transaction LTR.
Transfer behavior 1 means that we want to transfer data to HANA. If the data should be deleted, the transfer behavior can be set to 8.
Pressing the “execute” button for this report will then show a selection screen where all those tables which are both being replicated and are part of the archive object are shown. The user could select a part of those tables, or all of them, to be loaded from the archive:

After having chosen the relevant tables, press ENTER to have the corresponding migration object created, and its runtime objects generated. Then, you will see the new object in the “data transfer monitor” tab of transaction LTRC, the name will be exactly the name of the archive object, if not specified otherwise.

Currently it is still necessary to invoke step “Calculate Access Plan” manually from the “Steps” tab of transaction MWBMON. Only the two highlighted fields need to be manually filled:

After that, the data from the archive will be automatically transferred.
Necessary authorizations
Please note that the rfc user assigned to the rfc destination pointing from the SLT system to the sender system requires an additional authorization which is currently not part of role SAP_IUUC_REPL_REMOTE. The authorization check is:
AUTHORITY-CHECK OBJECT 'S_ARCHIVE'
ID 'ACTVT' FIELD '03'
ID 'APPLIC' FIELD l_applic
ID 'ARCH_OBJ' FIELD object.
That means, for authorization object S_ARCHIVE, we need an authorization with activity 03 (display), the respective archive object, and the application to which the archive object belongs.
Filter or mapping rules not available
Note that the automatic assignment of filter or mapping rules which is done for other migration objects (initial load and replication) by means of table IUUC_A S S_RUL_MAP will not work for the archive load objects. If any filtering and / or mapping is required for such objects, the corresponding rules need to be manually assigned to the migration object.
Relevant Notes
Hope this helps to understand the load from archives much better. Special thanks to Günter for these details.
Best,
Tobias
