Typically you will want to work on detailed data, but sometimes aggregations are needed. This little "R Extension" enables you to aggregate your data within the analytical workflow.
This can come in handy for instance for Time Series Forecasting when your dataset is too detailed but does not have a true date field. (If you have a date field then the native 'Triple Exponential Smoothing' component can take care of the aggregation)
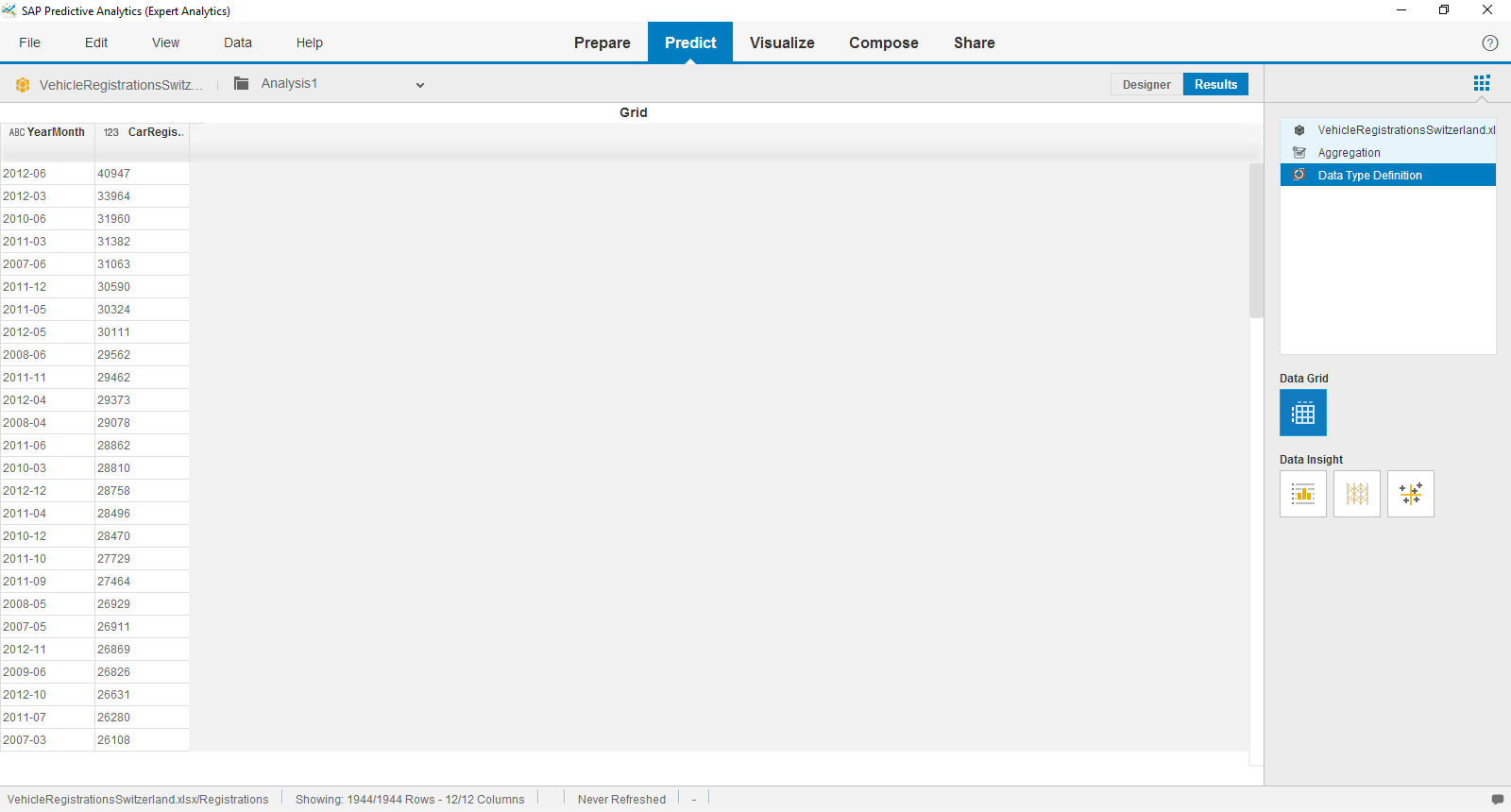
Here is an example. My data sets contains information about how many cars were registered in Switzerland from 2007 to 2012 each month in each region (called Canton).

Now I want to predict how many cars will be registered in future each month. So I need to aggregate by month, taking the Canton out of the data set.
The new R Extension (here called Aggregation) allows you to select
- The field to aggreate: Car Registrations
- The aggregation type: Sum
- The column to group by: Year-Month
Available aggregation types in this component are: Sum, Minimum, Maximum, Count, Mean and Median.

The component outputs two columns named GROUP_BY and AGGREGATED_MEASURE. If you like you can use the standard 'Data Type Definition" Component from the 'Data Preparation' tab to rename the columns to something more meaningful. This step is optional.

Execute the flow and you see the aggregates, which could be used for intsance in forecasting.
How to Implement
The component can be downloaded as .spar file from GitHub. Then deploy it as described here. You just need to import it through the option "Import Model/Extension", which you will find by clicking on the plus-sign at the bottom of the list of the available algorithms.
Disclaimer
Please note that this component is not an official release by SAP and that it is provided as-is without any guarantee or support. Please test the component to ensure it works for your purposes.
