在将HANA作为数据库创建universe建模时,有一条最佳实践,利用JOIN_BY_SQL特性。
这要从头说起,从一个另外相关的设置 - "Multiple SQL statements for each measure"。它的作用如同名字所表示的,对于使用的每一个measure单独生成一条SQL语句。目的是什么的?在基于数据库表设计universe建模的时候,有时候会遇到CHASM。在某些特殊场合下,报表的结果会不准确,比如产生笛卡尔积。解决方案之一便是将分别存在于不同表中的measure单独取出并在WEBI里面进行UNION操作。仅仅勾选这样一个选项,很棒。
我们看下面这样的例子来更好地理解(这里没有CHASM或者FAN,只是为了演示这个参数)
这是一个很简单的data foundation,而measure存在于两张表中

如果在WEBI的query panel里选择了这两个measure,而没有勾选这个选项,那么生成的SQL是什么样的呢?
SELECT
sum(Table__2."Quantity"),
sum(Table__1."GrossAmount"),
Table__1."OrderId",
Table__2."OrderItem"
FROM
"OPENSAP.workshop::header" Table__1 INNER JOIN "OPENSAP.workshop::item" Table__2 ON (Table__1."OrderId"=Table__2."OrderId")
GROUP BY
Table__1."OrderId",
Table__2."OrderItem"
我们看到是一条SQL语句,利用INNER JOIN来连接的,这就是可能产生CHASM的SQL。
那么我们勾选这个选项,再次运行同样的WEBI,结果如何呢?我们发现WEBI生成了两条SQL,然后用自己的UNION操作将他们组合起来。
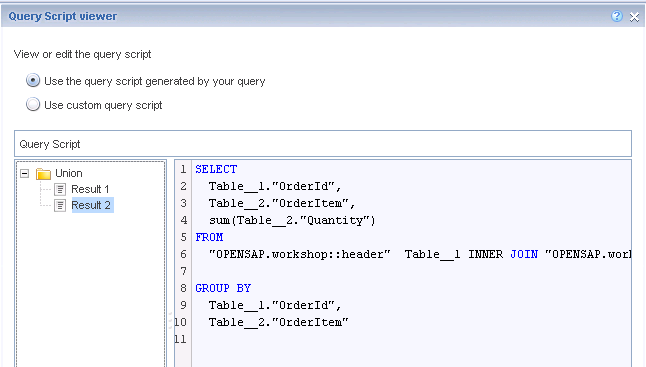
但是如果每个查询返回的数据很多会怎样?在WEBI里面做UNION效率一定不高,这时就可能产生性能问题。
这时候我们就可以借助JOIN_BY_SQL,将操作推到数据库层面去做。那么问题是,这与最开始没有勾选‘Multiple SQL statements for each measure“默认产生INNER JOIN语句时的区别在哪呢?我们先去universe里设置一下看看结果再说。

再次运行同样的WEBI报表,获得的SQL语句:
SELECT
COALESCE( F__1.Axis__1,F__2.Axis__1 ),
COALESCE( F__1.Axis__2,F__2.Axis__2 ),
F__1.M__3,
F__2.M__3
FROM
(
SELECT
Table__1."OrderId" AS Axis__1,
Table__2."OrderItem" AS Axis__2,
sum(Table__1."GrossAmount") AS M__3
FROM
"OPENSAP.workshop::header" Table__1 INNER JOIN "OPENSAP.workshop::item" Table__2 ON (Table__1."OrderId"=Table__2."OrderId")
GROUP BY
Table__1."OrderId",
Table__2."OrderItem"
)
F__1
FULL OUTER JOIN
(
SELECT
Table__1."OrderId" AS Axis__1,
Table__2."OrderItem" AS Axis__2,
sum(Table__2."Quantity") AS M__3
FROM
"OPENSAP.workshop::header" Table__1 INNER JOIN "OPENSAP.workshop::item" Table__2 ON (Table__1."OrderId"=Table__2."OrderId")
GROUP BY
Table__1."OrderId",
Table__2."OrderItem"
)
F__2
ON ( F__1.Axis__1=F__2.Axis__1 AND F__1.Axis__2=F__2.Axis__2 )
我们看到操作是通过数据库的FULL OUTER JOIN进行的。这样既保证了单独为每一个measure取数又能够保证整个操作在数据库层面进行,提高效率。
由于HANA处理的高效率,所以在基于HANA建模时,我们都建议利用这样的设置进行操作。
不过没有万能的设计。如果取回的数据量足够小,小到WEBI可以很快速的处理UNION,而数据库本身处理UNION操作又造成了一定的问题,比如大量内存的消耗,CPU时间的消耗,这个时候就不要坚持JOIN_BY_SQL了。
