
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- PI Alerting on AAE/AEX
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-27-2013
1:38 PM
The new component-based message alerting for PI, available with release 731 (http://help.sap.com/saphelp_nw73ehp1/helpdata/en/2c/f0a3d4540c4c9a9af65139801ef826/content.htm) is eliminating dependency to ABAP PI stack and allows to benefit from alerting on pure JAVA PI installations, like AEX. Even more, by starting a dedicated java scheduler job on your AEX you are in position to immediately receive emails for erroneous situation almost out of the box. The older alerting solution is completely based on PI Integration Server(http://help.sap.com/saphelp_nw73ehp1/helpdata/en/4b/b30db925cc3c1de10000000a42189b/content.htm?frame...).
The new solution is decomposing alert evaluation to each PI component, where a local alert engine is generating alerts based on rules maintained and distributed from PI Directory. Local alert engine is then keeping the alerts in a dedicated storage until some consumer (Alert Inbox solution) process them.
I will briefly cover some aspects of component-based message alerting, accenting on its JAVA side.
Alert store
Local alert stores are actually defined during configuration time, inside alert rules. Any consumer in an alert rule will result in local alert store, once the rule is distributed to corresponding PI component, during activation and standard PI cache refresh procedure (alert rule is configuration object in PI directory). If alert rule is enabled, then it is distrubuted to local CPA cache of components selected in alert rule. Its now accessible from local alert engine during evaluation of alerts in case of erroneous events coming from PI runtime.

Local alert stores are created dynamically during runtime by local alert engine, with the first alert evaluated for particular consumer. On AAE/AEX, the alert store is JMS queue. Each alert is actually a JMS text message, which text content is encoded to JSON format (alert payload) and instrumented with custom JMS header fields for error label, component, rule ID and scenario ID. The latter allows for fast access (browse or consume) of alerts for example by particular error label or component, ignoring natural queue order with the usage of JMS selector.
Any JMS destination (including alert queues), could be accessed remotely via P4 by standard JMS API. There is also WS on each AAE/AEX for consuming alerts - http://host:port/AlertRetrieveAPI_Service/AlertRetrieveAPIImplBean?wsdl.
For troubleshooting there might be situations where you want to just scan the alert store, without touching the alerts there, thus WS is not quite useful. The recommended way is to use some open source tool for browsing JMS destinations like for example Hermes JMS - http://www.hermesjms.com. I tried it, and to be honest, it is really buggy. In order to save your time I would recommend to use the preconfigured (replace the one in your .hermes home folder after installation) configuration file, I managed to figure out during my exeprience with installation version 1.15 but shall be compatible with any version I hope. It is attached to this post as hermes-config.xml. Just adjust principal, credentials, host and P4 port (providerURL property) as well as local path to required j2ee client jar libraries. In case you like to be able to browse more alert queues add them too, beside ALERT-TO-MAIL. You may also use browse with selector based on ErrLabel, ScenarioId, RuleId and Component header fileds of alerts. Another important remark is that you do not need to trigger and wait for JNDI lookup with that file I already preconfigured what is necessary, so this really saves an hours :smile:

Just to mention that every (remote) alert consumer shall have the role SAP_XI_ALERT_CONSUMER (or Administrator), otherwise will get exception when try to access alert storage, for example:
“javax.jms.JMSSecurityException: You do not have permissions: action alertingVP.queue and instance:name alertingVP.queue
action browse
instance jms/queue/xi/monitoring/alert/ALERT-TO-MAIL”.
In this example I am using User-Defined Message Search (UDS) scenario with failed PI message, which is resulting in alert, containing UDS attributes as part of JSON format. This is feature which could be enabled or disabled during alert rule definition on configuration time. Please note that you can not have the whole payload of the failed PI message in the alert JSON, but only the UDS attributes, if have any. This is how main tools involved (PI directory alert rule, UDS configuration in NWA, PI message payload and alert payload displayed with Hermes JMS) looks like:
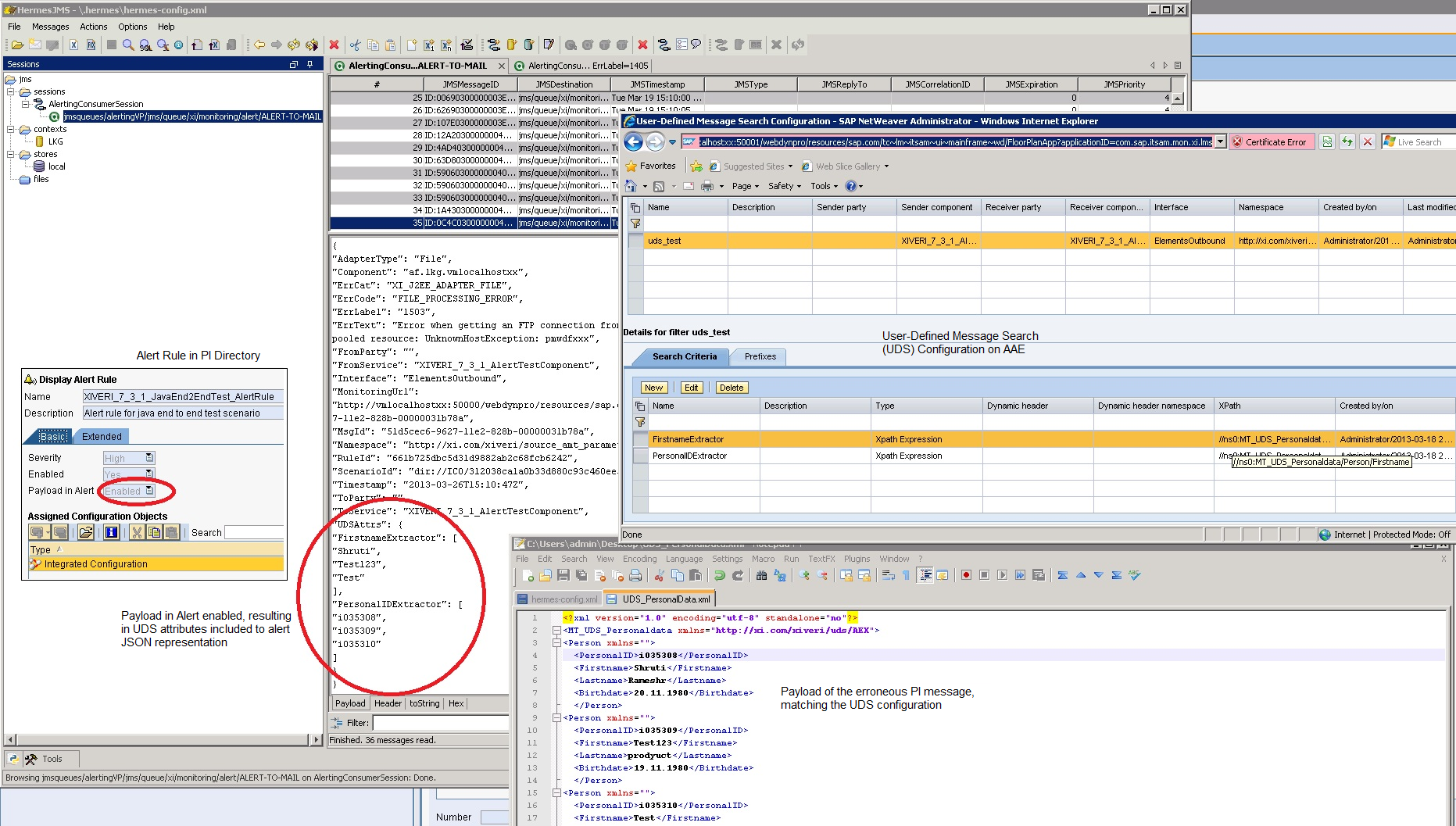
Default traces example
In case you are not receiving alerts for particular erroneous situation you might want to know what is going on and where processing got stuck. For this I am attaching sample traces helping to validate all important steps during alert evaluation. Please check attached text document - default_traces_example.txt for more details.
Housekeeping alerts
Housekeeping alerts are marking situation which you might want to address, as it indicates either too many alerts are received for short time interval, or the consumption of alert is too slow (or completely missing). Both situations might lead to consumption of lot of memory to store the alerts. The housekeeping alert might look like this:
{
"Component": "af.qx2.uctvt783",
"ErrCat": "HOUSEKEEPING_ERROR_CATEGORY",
"ErrCode": "HOUSEKEEPING_ERROR_CODE",
"ErrLabel": "1033",
"ErrText": "109 alerts were deleted for component af.qx2.uctvt783 and
rule ID fd2ab54d40f933b5ad2a2454e49e80d0",
"RuleId": "fd2ab54d40f933b5ad2a2454e49e80d0",
"Timestamp": "2013-02-05T20:17:15Z"
}
If housekeeping is triggered then the alerts will be removed from the storage and aggregation based on component and rule will produce just a few reserved alerts instead. This way the storage will be prevented from overload and the consumer will be notified about potentially dangerous situation. In the example above there had been 109 alerts per the specified component and rule which had been removed and replaced by this one when housekeeping had been triggered at the timestamp specified. In general this means that either some scenario or set of scenarios are producing lots of errors and alerts for short time interval, or alerts had not been consumed for quite long time from the storage.
The boundaries for detecting housekeeping situation are configurable as service properties in alert service:
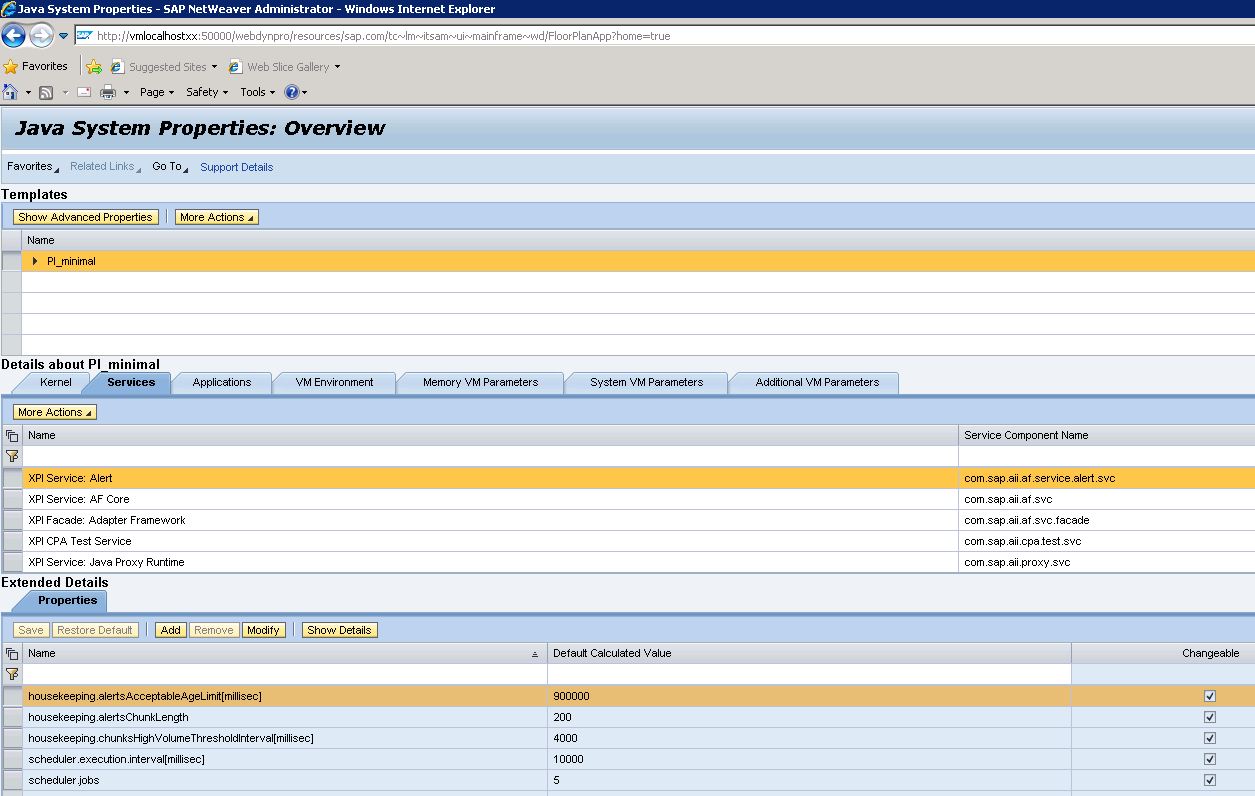
By default housekeeping checks are performed at any chunk end (by default on every 200 alerts). If two consecutive chunks are sent faster than threshold interval (by default about 2*200 alerts per 4 seconds) then housekeeping will be triggered. The other condition to trigger housekeeping is that for some reason no alert had been consumed more than 15 minutes (900000 milliseconds), in this case assumption is that consumer might be completely missing or is consuming too rarely. As mentioned, all these intervals and numbers from above are configurable as online modifiable service properties and no JAS restart is necessary to apply them. Just change, and after pressing “Save” button it shall be immediately applied.
Known fixed issues
- SAP Note 1803857: https://websmp230.sap-ag.de/sap/bc/bsp/spn/sapnotes/index2.htm?numm=1803857 - AlertConsumer regular developer traces for alerting
- SAP Note 1670625: https://websmp230.sap-ag.de/sap/bc/bsp/spn/sapnotes/index2.htm?numm=1670625 - Exceptions from JMS provider due to lack of permissions
- Internal Message Number 0120031469 0000448654 2013 - JMS permission checks does not work
And finally, I hope you already find out this quite nice troubleshooting guide:
http://wiki.sdn.sap.com/wiki/display/TechTSG/%28PI%29+Component-Based+Message+Alerting
PS: In case you have ABAP proxies, which are still generating error events and you would like to benefit from this new alerting, despite it is not downported to releases lower than 731, do not worry, it is still possible to configure them so that to send their error events to any AAE/AEX, where local alert engine will still evaluate alerts for those older ABAP components and still the alerts could be consumed in the same fashion from local alert store of AAE/AEX - http://help.sap.com/saphelp_nw73ehp1/helpdata/en/ce/d9b40646464dc78d750169d25d7278/content.htm?frame...
- SAP Managed Tags:
- Cloud Integration
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- Part 2:- SAP Basis OS support on SUSE Linux for beginners in Technology Blogs by Members
- Getting a clipboard alert while importing Excel files to SAP in Technology Q&A
- New webcast series on “SAP BTP DevOps and Observability in Action” in Technology Blogs by SAP
- Getting ready to start using SAP Focused Run in Technology Blogs by SAP
- HIRING ALERT in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |