
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Multi-Tenant Database Architecture - Part 5
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member19
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-01-2013
9:42 PM
This set of articles was first published on my Sybase blog in 2009. Since that time, this 5 part series has been one of the most requested set of articles. As part of Sybase's integration with SAP, I am republishing them on the SAP SCN, and taking the opportunity to update them.
Previous posts (Part 1, Part 2, Part 3, and Part 4) in this series outlined the factors to consider and 4 architectures to consider when implementing a multi-tenant database system. Each of the previously described architectures kept one tenant’s data isolated from other tenants, either by storing it in completely separate databases, or in separate schemas. The last model to discuss is the Shared Schema model, where all tenants share a single schema, and a given table will have data from multiple tenants intermixed.
Shared Schema
In this architecture, all data is stored in one set of tables. Each table must have a column used to identify the owner the row. Any application accessing the row must refer to this column in every query to ensure that one tenant is not able to see another tenant’s data.
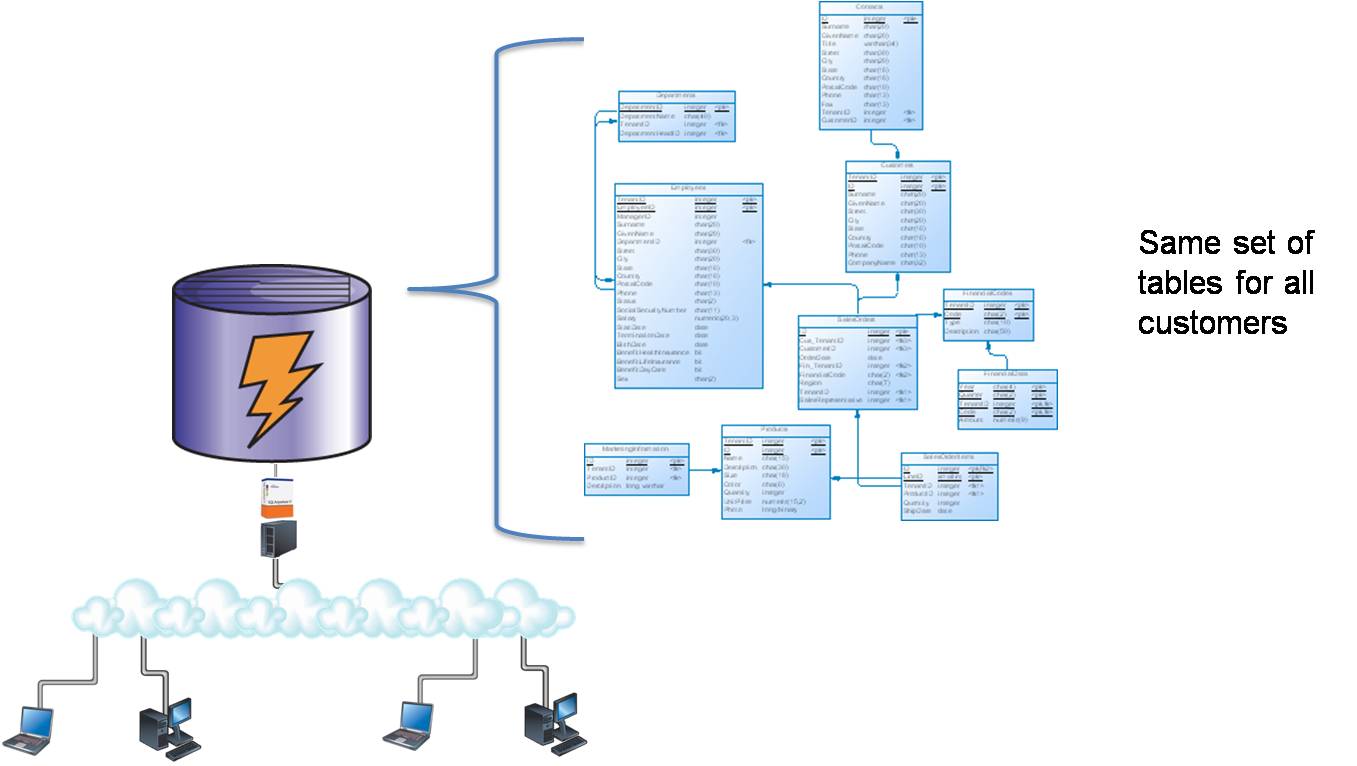
Because of the extensive changes required, applications must be carefully tested to ensure that data security is preserved. If an existing application is being ported to a shared schema environment, the use of VIEWs might ease the development effort. Query performance will have to be carefully examined, and additional INDEXes may be required.
While application development will certainly be more challenging, there are many benefits to a shared schema model:
- Development time – As discussed above, all application queries will have to be carefully coded to refer to columns in every table that identify the tenant owner of every row.
- Hardware cost – This architecture allows for high utilization of machine resources. In general, this will provide the cheapest option for implementing a multi-tenant environment.
- Application and database performance – The performance of one tenant may be impacted by the activities of other tenants. Query performance will have to be carefully examined to ensure the proper indexes exist.
- Security – The application must use specially coded queries to select or restrict the data based on the tenant. Robust testing must be used to ensure that a user is not able to see data from other tenants. Unique data encryption for each tenant is not possible.
- Customization requirements – All tenants share the schema, so it is much more difficult to allow for customization. There are a variety of approaches that can be used to provide customization. One approach is to enable a number of generic columns in each table that can be used in different ways by each tenant. Another approach is to make all tables generic, and allow each tenant to describe the complete schema. Application development can become much more challenging using this method.
- The number of tenants – This model is able to handle many more tenants than the previous models. Migration of tenants that require improved performance or capacity may be challenging, as data will have to be extracted from each table in separate operations. Also the ability to restore data for a tenant may be more challenging.
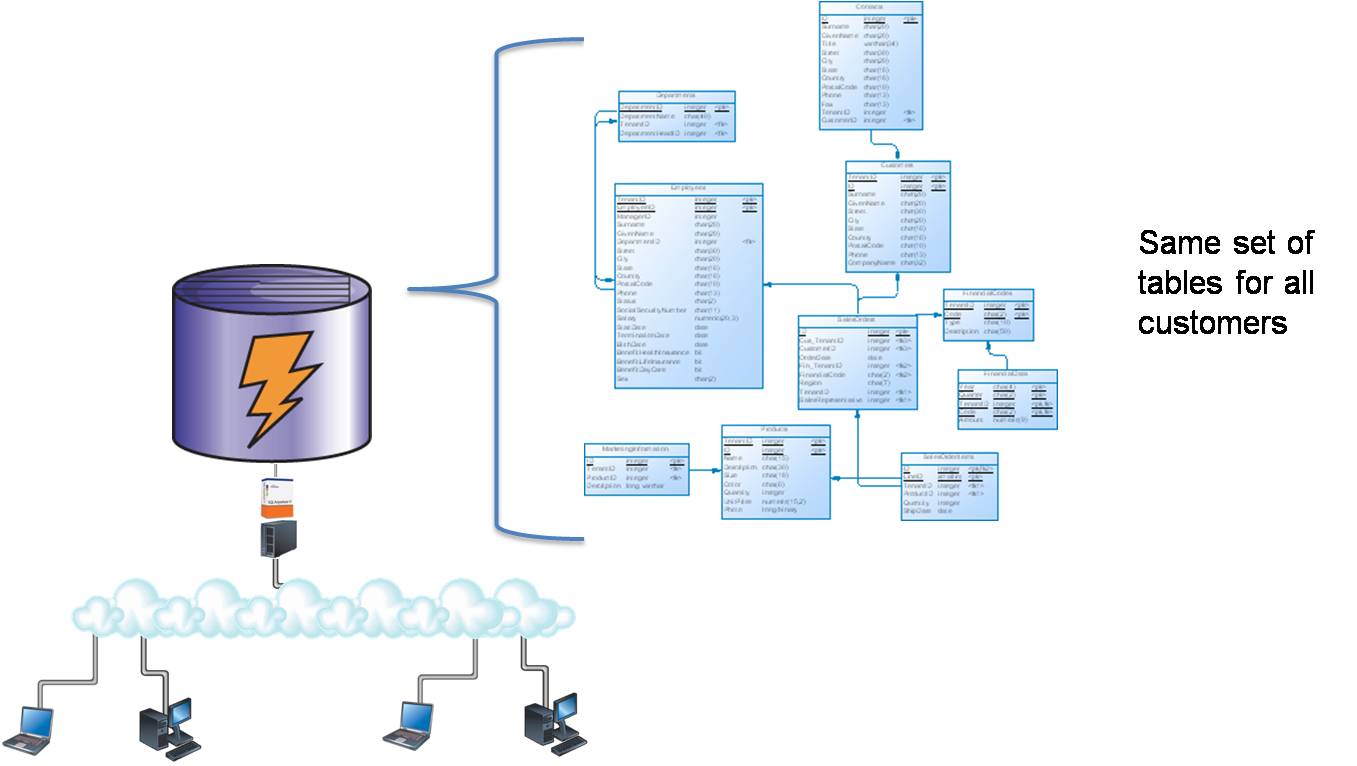
Each table must refer to the TenantID.
As mentioned above, the use of VIEWS may ease application development. In this example code, designed for SQL Anywhere, a VIEW is created to allow access to the Employees table. First a mapping table is created that maps a USER to a specific TENANT.
CREATE TABLE "TABLEOWNER".UserTenantMap (
TenantID INTEGER NOT NULL,
TenantUser CHAR(255) NOT NULL,
CONSTRAINT "UserTenantMapKey" PRIMARY KEY ("TenantID", "TenantUser" )
);
Next, the base table is defined with a TenantID column, and a VIEW is defined, joining with the UserTenantMap table:
CREATE TABLE "TABLEOWNER"."BaseDepartments" (
"TenantID" INTEGER NOT NULL
DEFAULT ( CAST( '1' AS INTEGER ) ),
"DepartmentID" INTEGER NOT NULL,
"DepartmentName" CHAR(40) NOT NULL,
"DepartmentHeadID" INTEGER NULL,
CONSTRAINT "DepartmentsKey" PRIMARY KEY ("TenantID","DepartmentID")
);
CREATE VIEW "TENANTVIEW"."Departments" (
"DepartmentID",
"DepartmentName",
"DepartmentHeadID"
) AS SELECT
"DepartmentID",
"DepartmentName",
"DepartmentHeadID"
FROM "TABLEOWNER"."BaseDepartments"
JOIN "TABLEOWNER"."UserTenantMap"
ON "BaseDepartments"."TenantID" = "UserTenantMap"."TenantID"
WHERE
"UserTenantMap"."TenantUser" = CURRENT USER;
The application can be coded to simply SELECT from the Departments table as before. Inserts or Deletes can be handled using an INSTEAD OF trigger defined on the view. INSTEAD OF triggers allow alternate actions to be performed, rather than the DML that caused the trigger to fire. Read more about SQL Anywhere’s implementation of INSTEAD OF triggers here. Here is an INSTEAD OF trigger to handle inserts on the Departments VIEW:
CREATE OR REPLACE PROCEDURE "tableowner"."InsertDepartmentProc"
(IN new_DepartmentID INTEGER,
IN new_DepartmentName CHAR(40),
IN new_DepartmentHeadID INTEGER,
IN insertingUser CHAR(255)
)
BEGIN
DECLARE new_TenantID INTEGER;
SELECT TenantID INTO new_TenantID
FROM "TableOwner"."UserTenantMap"
WHERE TenantUser = insertingUser;
INSERT INTO "TableOwner"."BaseDepartments" (
TenantID,
DepartmentID,
DepartmentName,
DepartmentHeadID )
VALUES (
new_TenantID,
new_DepartmentID,
new_DepartmentName,
new_DepartmentHeadID
);
END
;
GRANT EXECUTE ON "TableOwner"."InsertDepartmentProc" TO "TENANTVIEW";
CREATE OR REPLACE TRIGGER Insert_Departments
INSTEAD OF INSERT ON "TenantView"."Departments"
REFERENCING NEW AS new_row
FOR EACH ROW
BEGIN
CALL "TableOwner"."InsertDepartmentProc" (
new_row.DepartmentID,
new_row.DepartmentName,
new_row.DepartmentHeadID,
CURRENT USER
);
END
;
I encourage anyone interested in the Multi-Tenant database topics I have discussed in this series of articles to check out the SQL Anywhere on-demand edition.
- SAP Managed Tags:
- SAP SQL Anywhere
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
92 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
294 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
341 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
419 -
Workload Fluctuations
1
Related Content
- SAP CAP: Controller - Service - Repository architecture in Technology Blogs by Members
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Kyma Integration with SAP Cloud Logging. Part 2: Let's ship some traces in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 36 | |
| 25 | |
| 16 | |
| 13 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |