
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- When SAP HANA met R - What's new?
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member18
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-18-2013
4:56 PM
Since I wrote my blog When SAP HANA met R - First kiss I had received a lot of nice feedback...and one those feedbacks was..."What's new?"...
Well...as you might now SAP HANA works with R by using Rserve, a package that allows communication to an R Server, so really...there can't be too many new features...but...the cool thing is that SAP HANA has been tested with R 2.15 and Rserve 0.6-8 so any new features added on R and Rserve and instantly available on SAP HANA :wink:
But hey! I wouldn't write a blog is there wasn't at least one new cool feature, right? You can read more about it here SAP HANA R Integration Guide.
Of course...for this you need SAP HANA rev. 48 (SPS5)
So what's the cool feature? Well...you can store a train model like lm() or ksvm() directly on a table for later use. This is really cool, because if you have a big calculation to be made, you only need to store the model and use it later without having to reprocess everything again.
Let's make an example...and hope all the R fans doesn't kill me for this...because when it comes to statistics...I'm really lost in the woods :sad:
Let's say we have two tables from the SFLIGHT package...SPFLI and STICKET, so we want to predict how many times a customer is going to flight to different destinations (CITYFROM-CITYTO) depending on how many times all the customers has flights to those very same locations.
We're going to create one SQLScript file to get the information, transform it, create the model and store it in the database...
| Build_Flight_Model.sql |
|---|
--Create a TYPE T_FLIGHTS to grab the information from the SPFLI and STICKET tables. DROP TYPE T_FLIGHTS; CREATE TYPE T_FLIGHTS AS TABLE ( CARRID NVARCHAR(3), CUSTOMID NVARCHAR(8), CITYFROM NVARCHAR(20), CITYTO NVARCHAR(20) ); --Create a TYPE FLIGHT_MODEL_T and a table FLIGHT_MODEL to get and store the model in the database. DROP TYPE FLIGHT_MODEL_T; CREATE TYPE FLIGHT_MODEL_T AS TABLE ( ID INTEGER, DESCRIPTION VARCHAR(255), MODEL BLOB ); DROP TABLE FLIGHT_MODEL; CREATE COLUMN TABLE FLIGHT_MODEL ( ID INTEGER, DESCRIPTION VARCHAR(255), MODEL BLOB ); --This R procedure will receive the T_FLIGHTS information, create table containing a field call FLIGHT_NAME that will contain the concatenation --of the CARRID, CITYFROM and CITYTO. ie: AA-NEW YORK-SAN FRANCISCO. --We're going to convert the table into a data.frame, so all the similar values in FLIGHT_NAME are going to be summarized. --Using the subset() function, we're going to get rid of all the FLIGHT_NAME's that has a frequency lower or equal than 0. --We're going to use the nrow() function to count all the FLIGHT_NAME occurrences and multiply that by 10 (Stored in f_rows) --We're going to use the sum() function to sum all the frequencies and the divide it by f_rows (Stored in f_sum) --We're going to use the mapply() function to divide each of the frequencies by f_sum --We're going to use the order() function to sort by FLIGHT_NAME --We're going to use the colnames() function to assign names to our data.frame --We're going to use the lm() function to generate a Linear Regression based on the FLIGHT_NAME and it's frequency --Finally, we're going to use the generateRobjColumn() custom created function to store the result of the model in the buffer. DROP PROCEDURE FLIGHT_TRAIN_PROC; CREATE PROCEDURE FLIGHT_TRAIN_PROC (IN traininput "T_FLIGHTS", OUT modelresult FLIGHT_MODEL_T) LANGUAGE RLANG AS BEGIN generateRobjColumn <- function(...){ result <- as.data.frame(cbind( lapply( list(...), function(x) if (is.null(x)) NULL else serialize(x, NULL) ) )) names(result) <- NULL names(result[[1]]) <- NULL result } tab<-table(FLIGHT_NAME=paste(traininput$CARRID,traininput$CITYFROM,traininput$CITYTO,sep="-")) df<-data.frame(tab) ss<-subset(df,(df$Freq>0)) freq<-ss$Freq f_rows<-(nrow(ss)) * 10 fsum<-sum(freq) / f_rows ss$Freq<-mapply("/",ss$Freq, fsum) flights<-ss[order(ss$FLIGHT_NAME),] colnames(flights)<-c("FLIGHT_NAME","FREQUENCY") lmModel<-lm(FREQUENCY ~ FLIGHT_NAME,data=flights) modelresult<-data.frame( ID=c(1), DESCRIPTION=c("Flight Model"), MODEL=generateRobjColumn(lmModel) ) END; --This SQLSCRIPT procedure will grab all the needed information from the tables SPFLI and STICKET and will assign it to flights --We're going to call the R procedure FLIGHT_TRAIN_PROC --We're going to do an INSERT to finally store the model from the buffer into the database DROP PROCEDURE POPULATE_FLIGHTS; CREATE PROCEDURE POPULATE_FLIGHTS () LANGUAGE SQLSCRIPT AS BEGIN flights = SELECT SPFLI.CARRID, CUSTOMID, CITYFROM, CITYTO FROM SFLIGHT.SPFLI INNER JOIN SFLIGHT.STICKET ON SPFLI.CARRID = STICKET.CARRID AND SPFLI.CONNID = STICKET.CONNID; CALL FLIGHT_TRAIN_PROC(:flights, FLIGHT_MODEL_T); INSERT INTO "FLIGHT_MODEL" SELECT * FROM :FLIGHT_MODEL_T; END; CALL POPULATE_FLIGHTS(); |
When we call POPULATE_FLIGHTS(), our FLIGHT_MODEL table should look like this...

If you are wondering why we have an "X"...it's because the content is serialized and stored in a BLOB field...if you inspect the content, you will receive a bunch of weird hexadecimal numbers...
Anyway...it took 6.165 seconds to SAP HANA to process 1,842,160 records.
Now the we have our model safely stored in the database, we can move to our next SQLScript file...
| GET_AND_USE_FLIGHT_MODEL.sql |
|---|
--We're going to create a TYPE T_PREDICTED_FLIGHTS and a table PREDICTED_FLIGHTS to store the information of the current number of flights and --the estimated (according to our prediction) number of flights DROP TYPE T_PREDICTED_FLIGHTS; CREATE TYPE T_PREDICTED_FLIGHTS AS TABLE ( CUSTOMID NVARCHAR(8), FLIGHT_NAME NVARCHAR(60), FREQUENCY INTEGER, PREDICTED INTEGER );
DROP TABLE PREDICTED_FLIGHTS; CREATE TABLE PREDICTED_FLIGHTS ( CUSTOMID NVARCHAR(8), FLIGHT_NAME NVARCHAR(60), FREQUENCY INTEGER, PREDICTED INTEGER ); --In this R procedure, we're going to receive the flight for a given customer, the model stored in the database and we're going to return the result so it can be --stored in our PREDICTED_FLIGHTS table. --We're going to use the unserialize() function to extract the model. --We're going to create a table containing a field call FLIGHT_NAME that will contain the concatenation of the CARRID, CITYFROM and CITYTO. --ie: AA-NEW YORK-SAN FRANCISCO. and also the CUSTOMID --We're going to convert the table into a data.frame, so all the similar values in FLIGHT_NAME are going to be summarized. --We're going to use the colnames() function to assign names to our data.frame --We're going to use the nrow() function to get the number of records in the data.frame (Stored in dfrows) --We're going to use the rep() function to repeat the CUSTOMID value of the first record dfrows times --We're going to use the predict() function to predict the amount of flights based on our model (retrieved from the database) and the new data that we recovered --Finally, we're going to create a data.frame containing all the information that should be stored in our table PREDICTED_FLIGHTS DROP PROCEDURE USE_FLIGHT; CREATE PROCEDURE USE_FLIGHT(IN flights T_FLIGHTS, IN modeltbl FLIGHT_MODEL_T, OUT out_flights T_PREDICTED_FLIGHTS) LANGUAGE RLANG AS BEGIN lmModel<-unserialize(modeltbl$MODEL[[1]]) tab<-table(FLIGHT_NAME=paste(flights$CARRID,flights$CITYFROM,flights$CITYTO,sep="-"),CUSTOMID=flights$CUSTOMID) df<-data.frame(tab) colnames(df)<-c("FLIGHT_NAME","CUSTOMID","FREQUENCY") dfrows<-nrow(df) customid<-rep(df$CUSTOMID[1],dfrows) prediction=predict(lmModel,df,interval="none") out_flights<-data.frame(CUSTOMID=customid,FLIGHT_NAME=df$FLIGHT_NAME,FREQUENCY=df$FREQUENCY,PREDICTED=prediction) END; --This SQLSCRIPT procedure will select the information from the FLIGHT_MODEL table and store in the flight_model variable --We're going to select all the needed information from the table SPFLI and STICKET based on the customer ID number --We're going to call the R procedure USE_FLIGHT and it will return us the PREDICTED_FLIGHTS that we're going to store in the database
DROP PROCEDURE GET_FLIGHTS; CREATE PROCEDURE GET_FLIGHTS(IN customId NVARCHAR(8)) LANGUAGE SQLSCRIPT AS BEGIN flight_model = SELECT * FROM FLIGHT_MODEL; out_flights = SELECT SPFLI.CARRID, CUSTOMID, CITYFROM, CITYTO FROM SFLIGHT.SPFLI INNER JOIN SFLIGHT.STICKET ON SPFLI.CARRID = STICKET.CARRID AND SPFLI.CONNID = STICKET.CONNID WHERE CUSTOMID = :customId; CALL USE_FLIGHT(:out_flights, :flight_model, PREDICTED_FLIGHTS); INSERT INTO "PREDICTED_FLIGHTS" SELECT * FROM :PREDICTED_FLIGHTS; END; |
Now that we have all our Stored Procedures ready...we can create the last SQLScript file to actually fill our PREDICTED_FLIGHTS with some data...
| PREDICT_FLIGHTS_FOR_CUSTOMERS.sql |
|---|
CALL GET_FLIGHTS('00000156'); CALL GET_FLIGHTS('00002078'); CALL GET_FLIGHTS('00002463'); |
As you can see...we only need to call the GET_FLIGHTS procedure, passing the Customer ID's...
This process took only 970ms and generate 122 records for the 3 customers...
Now I'm sure you realize how cool is this...if we haven't stored our model in the database...then we would have to calculate the model for each customer...and it would have took us around 7 seconds for each (get the lm(), plus the predict)...that would have been around 21 seconds for the 3 customers...while we can say that the whole process took us only 7 seconds...if you needed to calculate the prediction for all the more than 1 million customers...you will be in sort of trouble :smile:
Let's see the content of our PREDICTED_FLIGHTS table...of course, I'm going to only show a part of it...
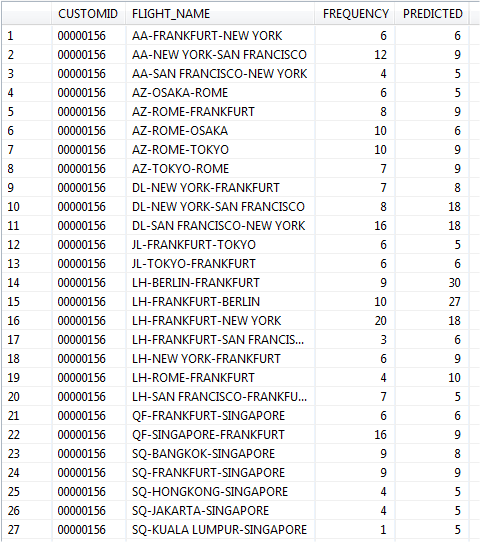
We can dump this information to a CSV file from SAP HANA Studio and let's say...use it on SAP Visual Intelligence to generate a nice graphic...

Hope you like it :smile:
- SAP Managed Tags:
- SAP HANA
11 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
275 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
329 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
407 -
Workload Fluctuations
1
Related Content
- SAP BTP, Kyma Runtime internally available on SAP Converged Cloud in Technology Blogs by SAP
- SAP Fiori Frontend 6.0 App installation and connection to SAP Business Suite in Technology Q&A
- Kyma Integration with SAP Cloud Logging. Part 2: Let's ship some traces in Technology Blogs by SAP
- Análise Combinatória de dados de bancos diferentes in Technology Q&A
- 体验更丝滑!SAP 分析云 2024.07 版功能更新 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |