
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- SAP TechEd 2012 – ABAP for SAP HANA: what the heck...
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-11-2012
1:11 PM
(2nd part of SAP TechEd recap blog)
In my last blog I have written about why we need ABAP for SAP HANA, about what we have already done as well as what we are planning to do in order to facilitate the integration between ABAP and the in-memory database technology and about which possibilities SAP HANA offers to ABAP (custom) development.
In this blog I want to write about the concrete impact SAP HANA has on the ABAPer.
Key innovations introduced with SAP HANA
To understand the impact SAP HANA has on the ABAPer, it can be helpful to revisit some of the key innovations introduced with the in-memory database technology. Since you will find plenty of information around these innovations, I will try to keep it short and focus on five innovations built into SAP HANA that I consider being of particular importance for this blog’s subsequent paragraphs. For details on in-memory database technology in general you can, for example, take a look at the home page of HPI (where you also find the original copies of the pictograms I have used).
 | The first important innovation is (I am sure that you have heard about it) that SAP HANA is capable of storing all relevant business data in main memory. That does not mean that SAP HANA does not support storing data on disk. It does mean that SAP HANA (typically) does not need to access the disk during query execution. |
 | SAP HANA supports multi-core architectures by distributing queries across multiple CPU cores (and across multiple server nodes). Applications running on SAP HANA hence can benefit from massive parallelization. To give you an idea of what is technically possible: during SAPPHIRE in Orlando vishal.sikka demonstrated SAP HANA running on a system with 4.000 CPU cores. |
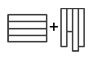 | Within SAP HANA data can be organized either in row store (like in ‘traditional’ databases) or in column store. While both stores have specific advantages and disadvantages, the bulk of business data resides in the column store where it can be quickly searched and aggregated. |
 | SAP HANA can compress business data (in row store). This not only reduces the amount of main memory needed, but also the amount of data to be transferred between main memory and CPU. The latter is important to handle the bottleneck of in-memory database technology: CPU waiting for data to be loaded from main memory into cache (in contrast to disk I/O which used to be the bottleneck in the past). |
 | Last not least, I want to mention SAP HANA’s capability to partition datasets. Partitioning is of particular interest for large database tables. It supports the parallelization of queries. For example, if a database table is spread across multiple partitions (on one server node), the aggregation of one column can be done in two steps. In the first step all partitions are aggregated simultaneously. In a second step the results of the first step are added up. |
Remark: while I have described the innovations one by one, it is the combination of them that really accounts for power of SAP HANA.
A new paradigm for ABAP emerges: “code-2-data”
To leverage the outlined innovations introduced with SAP HANA from ABAP, the database access becomes very important. And it is crucial – not so say compulsory – for ABAP applications to move data intense operations (i.e. costly calculations on large datasets) to the database layer. This is in some respects a paradigm shift, which is often referred to as “code pushdown” or “code-2-data” approach (in contrast to the “data-2-code” approach ABAP programs followed in the past).

The above diagram illustrates the two approaches: the “data-2-code” approach on the left and the “code-2-data” approach on the right.
What is the difference between the two?
In the past (based on traditional database technology) ABAP applications considered the database to be the bottleneck. Hence the complete business logic – including costly calculations – was implemented on the application layer. Very often a large number of records was transferred from the database to the application server to calculate only a few results there (for example to aggregate many line items to only a handful of key figures).
Now and in the future (based on SAP HANA) the database is not the bottleneck anymore. ABAP applications need to move – at least – parts of the business logic to the database layer. This not only reduces the amount of data to be transferred between database and application server, but it also ensures that the part of the business logic moved to the database (implicitly) benefits from the innovations built into SAP HANA.
However – especially when looking at existing ABAP programs – rewriting the business logic completely in the database might not be reasonable due to the efforts involved. Instead the “code pushdown” should mainly focus on costly calculations on large datasets (aka ‘number crunching’). Orchestration, process and display logic – that cannot be implemented in SAP HANA as of today or that will not benefit significantly from rewriting it in the database – should stay on the AS ABAP.
What does all that mean for the ABAPer?
Ok, now you might want to understand what all that means in terms of your skills and competencies as ABAPer. tobias.trapphas already touched this in his blog ‘First experience with ABAP for HANA’. I like to add a few thoughts.
During SAP TechEd I have heard questions like:
- Do I have to forget everything I know about ABAP development?
- Does Open SQL also work on SAP HANA?
- Will all function modules be re-implemented as database procedure?
You can put your mind at rest. As already mentioned in the first blog of this series, existing ABAP programs (developed for traditional databases) continue to run on SAP HANA. That implies that also a lot of your ABAP knowledge stays relevant. You can use Open SQL to access SAP HANA just like you access any traditional database. You can work with function groups (even though I personally prefer classes) when running on SAP HANA. And you should not attempt to re-implement all your function modules as database procedures. In five words: many things stay the same.
Even performance guidelines given by us for traditional databases in the past remain valid for SAP HANA to a large extend. But certain performance guidelines become more (‘use field lists’) or less (‘avoid access using non-key fields in WHERE clause') important.
We definitely like to encourage you to apply your ABAP knowledge to business problems also when running on SAP HANA. In fact, when optimizing an existing ABAP program for SAP HANA you should first try to do the optimization by ‘standard’ ABAP means. Only if that does not do the trick, you should consider using SQL features beyond Open SQL (i.e. Native SQL / ADBC), SAP HANA views or database procedures from within ABAP (which is planned to be quite easy in SAP NetWeaver AS ABAP 7.4).
At the same time you need to look beyond your own backyard. I like to encourage you to brush up your SQL knowledge (beyond Open SQL features), gain experience with performance optimization and familiarize yourself with modeling and scripting in SAP HANA.
Now eric.westenberger will take over. In the remaining two blogs Eric will deepen some of the thoughts, give you background information on the database architecture of the AS ABAP and show you some concrete examples.
- SAP Managed Tags:
- ABAP Development
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
8 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
4 -
ABAP in Eclipse
1 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
8 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
4 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
7 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
4 -
DMS
1 -
dynamic logpoints
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
IBM watsonx
1 -
Integration & Connectivity
10 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
13 -
Restful webservices Using POST MAN
1 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
text editor
1 -
Tools
16 -
User Experience
5
Top kudoed authors
| User | Count |
|---|---|
| 6 | |
| 5 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 |