
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Data Services code migration & maintenance: simpli...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
scott_broadway
Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-06-2012
6:00 PM
For so many of my customers, SAP Data Services is a relatively new tool. A typical DS project is mainly focused on ensuring the solution works for the business and is launched on time. Unfortunately, many of these projects fail to utilize some of the built-in features of Data Services to help simplify how code is managed in the solution. This is an architecture gap that adds hidden costs to owning and operating the solution.
In this article, I outline the framework for managing Data Services code that I have taught to dozens of the largest customers in the Americas. Ideally, you should implement this during the blueprint phase so that you provide your developers with the tools and processes to create better code the first time. However, you can still benefit from this framework even if you are approaching the testing phase of a Go-Live.
The elements of this framework include:
1. Implement multiple central repositories
In Data Services, a "central repository" is a different type of repository used only for version control of objects. This is comparable to version control systems like CTS+, Visual SourceSafe, Apache Subversion, BusinessObjects LCM, etc. You can check in new code, check it out to work on it, check in new versions, and get copies of specific versions.
Many customers do not use central repositories. Instead, they create their code in a local repository, export the code to an ".atl" file, and import it into the test or production local repository. You can save backups of the .atl file and keep track of them in a number of ways...even Apple Time Machine and Dropbox can keep track of multiple versions of a file through time. However, this is likely not a scalable or trustworthy solution for enterprise IT.
If you want to learn how to work with a central repository, the Data Services Tutorial Chapter 12 "Multi-user Development" does a fantastic job at demonstrating all the techniques. The "Using a Central Repo" Wiki Page also captures some of the basic techniques. But neither will tell you why, or discuss how you should set up your landscape or processes.
[Note: There are two different types of central repositories: non-secure and secure. Secure central repositories allow only specific users permissions on specific objects and provide an audit trail of who changed which objects. Non-secure central repositories lack these features. Due to this gap, I never recommend the use of non-secure central repositories. In this article, whenever I refer to a central repository, I am talking about secure central repositories. Chapters 23-24 in the Data Services Designer Guide discuss these differences.]
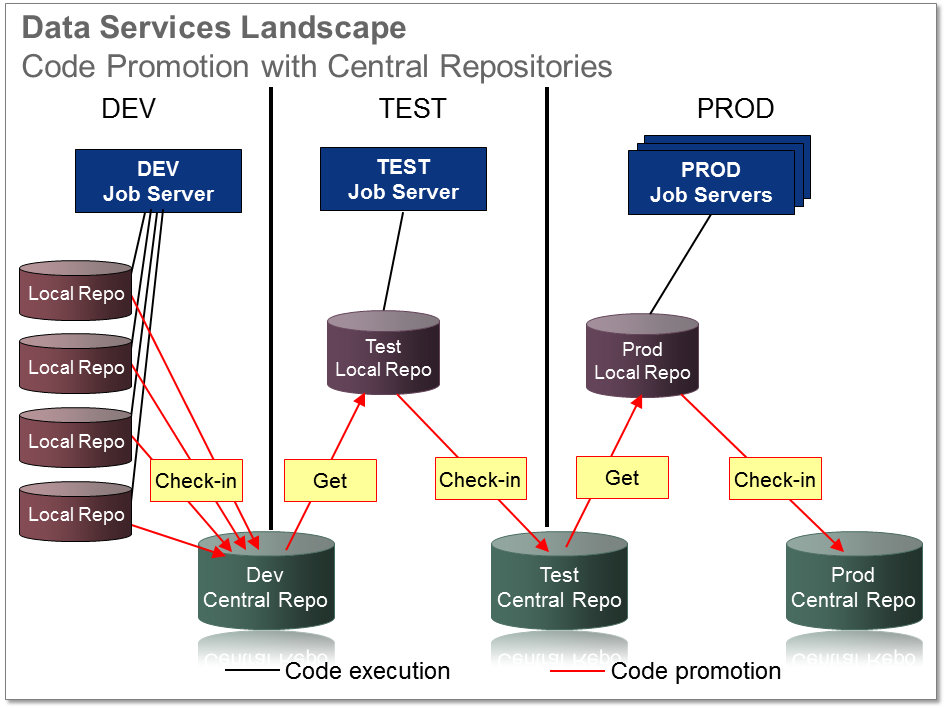
This is how I recommend for you to configure up your secure central repositories.
- Development Central – a central repository that can be accessed by developers and testers. Developers create content in their local repositories and check in this content into the development central repository. Each logical set of code should be checked in with the same label (e.g. "0.1.2.1a") so that they can be easily identified and grouped together.
During a test cycle, a tester logs into a local repository dedicated to testing and connects to the development central repository. The tester gets all objects to be tested from the development central repository. The tester deactivates the connection to the development central repository and then connects to the test central repository. - Test Central – a central repository that can be accessed by testers and production administrators. During the test cycle, testers check in development objects before and after testing, labeling them appropriately (e.g. "0.1.2.1pretest" and "0.1.2.1passed"). Thus, the test central repository contains only objects that have been promoted from development to test and have passed testing.
- Production Central – a central repository that can be accessed only by production administrators. When testers certify that the code can be migrated to production, a production administrator logs into a production local repository. The administrator activates a connection to the test central repository and gets a copy of all objects to be promoted to production (e.g. "0.1.2.1passed"). The administrator deactivates the test central repository and then activates the production central repository. All objects that were promoted into production are then checked into the production central repository (e.g. "0.1.2.1prod"). Thus, the production central repository contains only objects that have been successfully put into production.
Remember, central repositories are only for version control, storing your code, and helping you migrate it. You never run batch jobs or launch real-time services from a central repo -- only from a local repo.
This tiered approach plan looks like this:
The repositories themselves are just database schemas -- you can put them in any supported database. Check the Product Availability Matrix for Data Services to see which databases are supported. However, I would recommend for you to group them together within the same physical database within your specific tier. For instance:
- Dev database -- dev local repositories, dev central repository, and dev CMS database. Co-located with the dev Data Services hardware.
- Test database -- test local repository and test central repository, and test CMS database. Co-located with test Data Services hardware.
- Prod database -- prod local repository and prod central repository, and prod CMS database. Co-located with prod Data Services hardware.
1.1 Additional best practices for central repositories
- Security -- Set up group-based permissions for repository authentication and for individual objects. Refer to the Designer Guide section 24.1.1, Management Console Guide section 3.3.1, and Administrator's Guide section 4.1.
- Checking out datastores -- Using the security features of secure central repositories, make sure that only specific groups have read+write permissions on datastores. Everyone always has permissions to edit datastores in their local repository, but it would be disorganized to let all of them check in these datastore changes to the central repository. Thus, you should have administrators create your datastores and check them into your local repository. Anyone can get them from the central repo but only administrators have permissions to check them out, modify them, and check in their changes. For more info on defining datastores, see below "3. Defining datastore configurations".
- Backup -- These repositories contain most of your investment in your DS solution! Make sure to back up these databases regularly as you would with any other database. Too often I see no backups taken on the development central repository because "it's not part of the productive tier." This is a terrible business decision! What if your development central repository database crashes and your developers lose everything?
- Designer performance -- DS Designer requires a database connection to the local and central repositories. I always meet people who complain about Designer being too slow. Okay, but you are using Designer on your laptop in the Toronto airport from a VPN connection to your Seattle network hub and the repo database is in your Chicago datacenter. Designer performs numerous small transactions that each require network round-trips -- if the connection is slow, Designer is going to be slow to save anything to your local repository or interact with a central repository.
Are you regularly using a thick-client Windows app like Designer from remote locations? Maybe you should think about putting Designer on Citrix Presentation Server -- check the Installation Guide for Windows section 6.6. Additionally, Designer 4.1 introduces the ability to use DS under multiple Windows Terminal Server users. - Concurrent usage -- I often hear issues about developers connected to the same central repo who have their Designer hang up on them whenever their colleagues do anything ("Get Latest Version", "Check-Out by Label", etc.). To protect the code from being corrupted by multiple people trying to do multiple things at the same time, Designer performs table locking on certain central repo tables. While one user has an exclusive table lock on a central repo table, any other users trying to interact with the same table will be queued until the first user's exclusive table lock is released. How to work around this? Simple -- don't keep your connection to the central repo active all the time. There's a Designer option that allows you to activate a central repo connection automatically, and you should disable this option. Only activate your central repo connection when you need to get code from or check code into the central repo.
2. Define substitution parameters & multiple substitution parameter configurations
Substitution Parameters are such a handy feature, but I seldom see them used to their full potential! If you know C++, they are similar to compiler directives. They are static values that never change during code execution (so we don't call them variables). They are called "substitution" parameters because their values get substituted into the code by the optimizer when you run the job. They can thus change the run-time behavior of your code.
Often I see many programmers use a script block at the beginning of a job to set global variable values. These global variables are then used to control the logic or mappings later in the job. However, in 90% of these cases the global variables NEVER CHANGE during runtime. So now you have several problems in your code:
- You hid your global variable declarations in a script somewhere in your job. How do you expect other people to understand what you did in your code?
- A global variable is specific to one job only. Other jobs do not inherit global variable names, types, or values. So if you have 100 jobs that use a variable named $START_DATE, you have to declare $START_DATE in every one of those 100 jobs.
- Global variables have no way of being set quickly en masse. You can override them individually at run-time, but this introduces the risk of human error.
Substitution parameters fix all of these global variable short-comings. They are defined for an entire repository, not per individual job. Their values are controlled at a repository level, so you don't have to include scripts to set them. They cannot change through run-time, so they don't have the risk of being modified erroneously. Lastly, they don't just have one default value -- you can set up multiple substitution parameter configurations for your repository so that you have multiple different sets of run-time values.
Here are some common uses for substitution parameters:
- File paths and file names -- tell jobs where to find files in a specific staging area or target location. If you always set flat file and XML file sources and targets to use substitution parameters instead of hard-coded paths, you can change all file locations at once globally instead of having to find every single object, drill into it, and change the path. This is also used to specify reference data locations.
- Control logic -- tell the same job how to run differently if a different substitution parameter value is found. You can use this to set up one job that does both initial loading and delta loading. You can have a conditional block evaluate a parameter named [$$IS_DELTA] and decide whether to process the "delta" workflow or the "initial" workflow. This lets you have fewer jobs and simplifies your life!
- Transform options -- tell transforms to behave in a specific way. This is often used in Data Quality transform options to set country-specific options, engine options, performance parameters, or rules. However, you can use them in most of the transforms and mappings to override hard-coded values with your own substitution parameters.
Substitution Parameter Configurations are helpful because they let you set multiple different sets of substitution parameters. You can use this to set up multiple configurations for:
- Dev / Test / Prod
- Initial vs. Delta
- Enabling verbose debug code in your own script blocks or custom functions
- Specifying multiple file paths, e.g. fileshares in Chicago, L.A., Shanghai, Wrocław, and San Leopoldo.
Substitution Parameters are not objects that can be checked into a central repository, since they aren't actually code objects. As such, there is a specific way to move them between local repositories. You must export them to an ATL file and import them into another local repository. Please refer to the example below:

This is an additional step to include in your migration plans from Dev -> Test -> Production. However, it is relatively quick procedure for an administrator.
3. Define datastore configurations
Datastore mistake 1: In many customer environments, I log into a local repository and see several datastores named similarly ("HANA_TARGET_DEV", "HANA_TARGET_QA", and "HANA_TARGET_PROD"). Or maybe I see many SAP datastores named after their SIDs ("BWD", "BWQ", "BWP). If you make this mistake, you need to go through the following unnecessary steps:
- If you move a job from development to test, you have to edit every single dataflow and delete every single table object, replacing the table objects from datastore "HANA_TARGET_DEV" with the ones from "HANA_TARGET_QA".
- This increases the risk of human error -- what if you pick the wrong table by mistake?
- This increases the number of table objects to maintain -- you have to import the same table object 3 different times, one from each different datastore.
- You risk having differences in the table metadata from the different development/test/production datastores. Don't you want to ensure that the code is always the same?
Datastore mistake 2: Since this gets to be so time-consuming, many developers realize that they can just reuse one datastore from dev to test to production. So you see a datastore named "HANA_TARGET_DEV" or "BWD" in a production local repository. In this case, the administrators just explain how they change the hostname, username, and password of the datastore when they move it to test or production. Though this sounds simple, you still run the risk that you must change more than just username/password. In the case of an SAP ECC source datastore, are the transport file paths the same between your different ECC sources?
The solution to both of these mistakes? Datastore configurations.
Datastore configurations are very powerful. They allow you to have a single datastore that can connect to multiple different sources. They work very similar to substitution parameter configurations: at run-time, the optimizer selects a single configuration, and this connection information is used for the entire execution of the job and cannot be modified. You set them up in the datastore editor...the Data Services Wiki shows a good example.

I would strongly urge you to avoid the two mistakes above by starting your project with the following principles:
- Give datastores meaningful names that describe their data domain. Do NOT name them after a specific tier (dev/test/prod) or a specific region (AMER/EMEA/APJ) or a specific database ("DB2", "HANA", "SYBASEIQ") or a specific SAP SID (ECD/ECQ/ECP). Just name them after their data: "SALES", "VENDOR", "MATERIALS", "VERTEX", "BANKING". This is important because you cannot rename a datastore once it is defined.
- Set up multiple datastore configurations inside of each datastore. Multiple datastore configurations should be used when the same metadata exists in multiple systems. If the metadata is different between two systems, they belong in separate datastores.
- If you have Dev/Test/Prod tiers, make sure to set up separate datastore configurations for Dev/Test/Prod in your development local repositories. No, you don't have to know the correct usernames/passwords for the test or production systems (and in fact, this would be a serious risk!). Get them set up anyway! When testers and production administrators go into production, the only thing they will need to change will be the username and password. This helps avoid the risk of human error during a critical Go-Live.
For advanced users, you can even use datastore configurations to move from one database platform to another without having to re-develop all your code.
3.1 Use aliases to map table owners (optional)
If you are using database sources or targets, these tables always have an owner name or schema name (e.g. "SCOTT"."TIGER"). In the Data Services Designer interface, these owner names exist but are not usually very obvious to the user.
This is usually a problem that manifests itself when you migrate from Dev to Test or Test to Production. Let's say you developed your dataflow and used a source table named "SQLDEVUSR1"."EMPLOYEES". The username "SQLDEVUSR1" is the table owner. You also set up a second datastore configuration for the Test environment, and the username is "SQLTESTUSR5". When you run the job and set the Test datastore to be default, the job crashes at this dataflow with a "TABLE NOT FOUND" error. Why? It connected to the database specified in the Test datastore configuration as username "SQLTESTUSR5" and tried to find a table named "SQLDEVUSR1"."EMPLOYEES". This is a design problem, not a Data Services error.
Instead, you need to tell Data Services how to interpret the name "SQLDEVUSR1" differently depending on which datastore configuration is active. There is a feature called "Aliases" in each database datastore that lets you control this!
You can create one or more aliases in each database datastore to automatically change the table owner name defined in the dataflow with the table owner name of your choice. At runtime, the optimizer does a search and replace through the code for any objects from that datastore and maps an alias named 'SQLDEVUSR1" to be "SQLTESTUSER5".
Here's another example:

This is a little-known feature, but it saves you a ton of time if you have many developers who connected to various sandbox databases when developing the code. You can simply set up multiple aliases to search for various (and possibly incorrect) owner names and map them to what their "real" owner names should be within your official Dev/Test/Production datastore configurations.
4. Define system configurations to map together combinations of substitution parameters & datastore configurations
At this point, you have done the following:
- Created substitution parameters
- Created multiple substitution parameter configurations to control various aspects of run-time behavior
- Created datastores
- Created multiple datastore configurations to connect to different sources of data that have identical metadata
Your setup might look like this:

The final step is to create system configurations. These are combinations of datastore configurations and substitution parameters that let you set up job execution profiles that can be quickly and easily set at run-time. The optimizer then chooses only that combination of configurations for the execution of the entire job. If you have never defined a system configuration in a specific local repository, you will never see it as a drop-down option when you try to run a job. However, after you configure system configurations, you will now see a convenient drop-down box that shows the names of your various system configurations:

If we use the example above with the 3 datastores with 3 different configurations and the 6 different substitution parameter configurations, you can now create system configurations as combinations of these. Here is how you might set up your system configurations:
After this, when you run or schedule a job, you would see a drop-down with your 6 different system configuration names:
- DevInit
- DevDelta
- TestInit
- TestDelta
- ProdInit
- ProdDelta
To be honest, this isn't a very good example. Why would you want your production local repository to have the ability to easily execute jobs in your Dev landscape? Thus, you would probably want to set up system configurations that specifically correspond to the substitution parameter configurations and datastore configurations that you really want to use when you actually run the jobs. So in thisexample you would probably want to set up your production local repository system configurations to only include "ProdInit" and "ProdDelta" so you never make the mistake of selecting one of the Dev or Test configs.
What if you don't select a system configuration at run-time? Each datastore has a "default" datastore configuration. Likewise, there is also a default substitution parameter configuration. If no substitution parameter configuration is selected, the optimizer selects the default datastore configuration for each datastore and the default substitution parameter configuration for that repository.
Similar to substitution parameter configurations, system configurations cannot be checked into a central repository. They can be migrated in the same way you saw above with exporting substitution parameters to an ATL file. However, this is probably not necessary -- system configurations are very quick to define, and you probably only want to create them for the environment that you want to run in (e.g. "ProdInit" and "ProdDelta").
Let me know if this framework makes sense. If you see weird errors, search the KBase or file a SAP Support Message to component EIM-DS.
- SAP Managed Tags:
- SAP Data Quality Management,
- SAP Data Services
32 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
325 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
403 -
Workload Fluctuations
1
Related Content
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 7 in Technology Blogs by SAP
- It has never been easier to print from SAP with Microsoft Universal Print in Technology Blogs by Members
- S/4HANA 2023 FPS00 Upgrade in Technology Blogs by Members
- Recap - SAP ALM at SAP Insider Las Vegas 2024 in Technology Blogs by SAP
- Partner-2-Partner Collaboration in Manufacturing in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 10 | |
| 9 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |