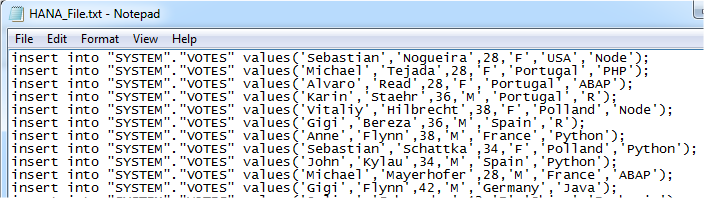
import os import sys import random names = ["Anne", "Gigi", "Juergen", "Ingo", "Inga", "Alvaro", "Mario", "Julien", "Mike", "Michael", "Karin", "Rui", "John", "Rocky", "Sebastian", "Kai-Yin", "Hester", "Katrin", "Uwe", "Vitaliy"] last_names = ["Hardy", "Read", "Schmerder", "Sauerzapf", "Bereza", "Tejada", "Herger", "Vayssiere", "Flynn", "Byczkowski", "Schattka", "Nogueira", "Mayerhofer", "Ongkowidjojo", "Wieczorek", "Gau", "Hilbrecht", "Staehr", "Kylau", "Rudnytskiy"] age = [24, 34, 40, 38, 28, 36, 35, 42, 30, 37] *** = ["M", "F"] country = ["Germany", "France", "Polland", "Peru", "Russia", "USA", "China", "Philippines", "Portugal", "Spain"] vote = ["ABAP", "Node", "Ruby", "Python", "R", "PHP", "ActionScript", "Euphoria", "Java", "C++"] def Generate_File(pSchema, pNumber): iNumber = 0 pathname = os.path.dirname(sys.argv[0]) pathname = os.path.abspath(pathname) + "\HANA_File.txt" myfile = open(pathname, "a") while iNumber < pNumber: r_names = random.randrange(0, 20) r_lastnames = random.randrange(0, 20) r_age = random.randrange(0, 10) r_*** = random.randrange(0, 2) r_country = random.randrange(0, 10) r_vote = random.randrange(0, 10) iNumber += 1 myfile.write("insert into " + pSchema + " values('" + names[r_names] + "','" + last_names[r_lastnames] + "'," + str(age[r_age]) + ",'" + ***[r_***] + "','" + country[r_country] + "','" + vote[r_vote] + "');\n") myfile.close() print 'The file ' + pathname + ' was written successfully' schema = raw_input("Schema: \n") num_files = input("How many records?: \n") Generate_File(schema, num_files) |






{kind=link}
