Millions of Indians use the Indian Railway every day to travel across India. The Indian Railways is one of the largest Railway networks in the world and it carries approx 30 million passengers daily.
Bookings in Indian Railways opens 120 days in advance from the date of travel. Some routes are not as busy as others and usually tickets are available until 30 days in advance. However, some routes are very very busy and the booking is exhausted within hours of opening - especially during peak seasons like Summer Vacations, Diwali Vacations etc.
Since the tickets are booked so fast, often passengers have to plan their travel quite early - as early as 4 months. Often these travel plans change and passengers end up paying the cancellation fee.
What do passengers need?
- Ability to forecast / estimate the traffic - taking into account the national vacations / events etc.
- Ability to forecast the chances (probability) of getting a confirmed ticket.
What does Indian Railways Organization need?
- Ability to forecast / estimate the traffic so that they could plan more trains
- Ability to estimate the number of cancellations
What can SAP HANA do?
- SAP HANA can help the Indian Railways analyze the historic passenger volumes and estimate the traffic
- SAP HANA can analyze the historic cancellation information and help the Indian Railways plan additional trains effectively.
- SAP HANA can predict the chances of getting a confirmed ticket based on historic data.
Why only SAP HANA can do it?
- On an average, approx 30 millions passengers travel daily with Indian Railways.
- More than 10000 trains run daily
- Data volume for a year will be approximately: 10 Billion ! -- Who else can analyze this?
Is this really feasible?
I asked myself, Is this really feasible? And then I decided to do a prototype. Of course, I have no access to the data of Indian Railways and I am no Hacker 😉
Hence, I decided to analyze the data available in the public domain (freely accessible to everyone).
The prototype:
Indian Railways provides an online facility to look up for the current availability in trains. The availability can be checked here:
http://www.indianrail.gov.in/seat_Avail.html

This gives only one side of the information. i.e. - the availability. Here, we do not have any cancellation information. i.e. how many tickets are cancelled each day.
However, this is good enough data to analyze. This publicly available data was uploaded into a HANA sandbox system for analysis.
For the purpose of prototype, I analyze the data of 1 train that runs from Bangalore to New Delhi. I plotted the availability (number of tickets available) on Y-Axis vs. the date on X-Axis. This shows how the availability is reduced.
Availability for travel date: 6th June:

Availability for 7th June:
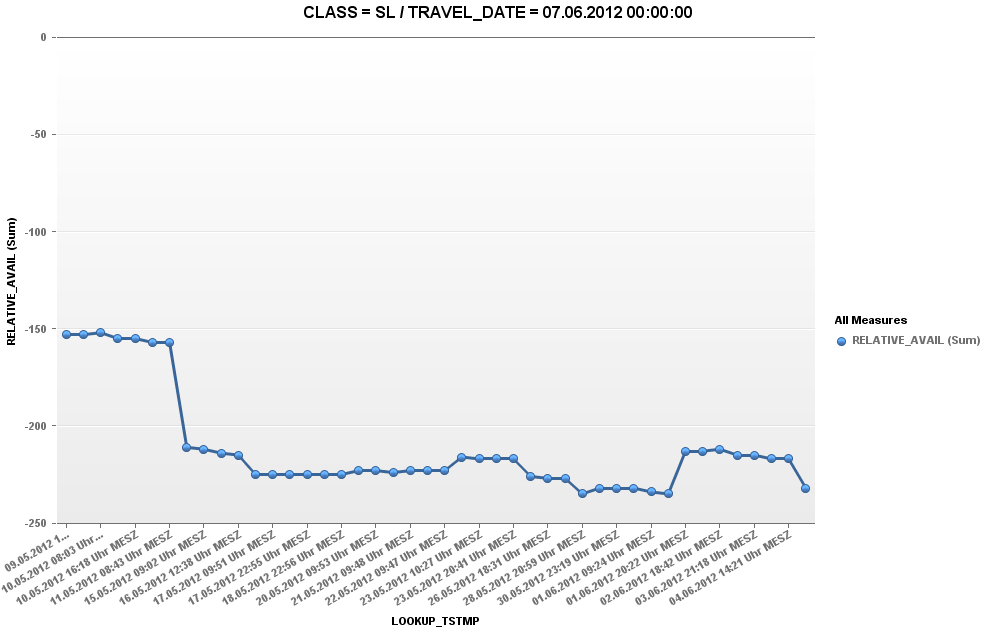
Availability for 8th June:

Availability for 9th June:

From the above graphs, it is evident that in a time span of 9th May - 4th June, more tickets were booked for travel date = 8th June as compared to other dates.
Well, that sounds very logical because 8th June is Friday :smile: .
For more technical details, feel free to contact me.
