Clustering is the known technique in the unsupervised machine learning algorithm. KMean algorithm is one of the approaches for doing the clustering of multi-dimensional instance. Clustering can be fast when we do it on small number of data element or instance; the performance starts to degrade as we increase the dimension and number of instances.
KMean Algorithm:
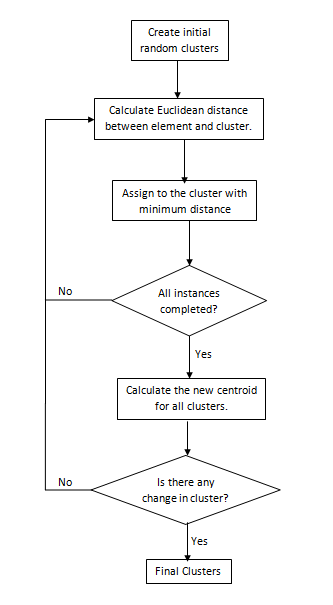
- Create the initial clusters using the random function.
- Traverse through each element or instance and find the closest cluster. In this case I take the Euclidean distance between the various dimension of cluster centroid and data element. Assign the instance or element to the closest cluster.
- After assigning all the instances to a cluster using step 2, find the new centroid of the clusters. For this I used the mean of all the elements in that cluster.
- Repeat Step 2 to 3 until no change in any cluster or maximum number of iteration completed.
- Final clusters.
When the dataset or instance is large, it becomes expensive to compute the Euclidean distance with cluster centroid for a single iteration. To solve this problem I partitioned the instances horizontally and executed them in parallel to finding the cluster for each element or instance point. Once all the thread completes than compute the new centroid.

As shown in the figure above step 2 will change as:
For Data Element 1 to 1000
Step2 Traverse through each element or instance and find the closest cluster. In this case I take the Euclidean distance between the various dimension of cluster centroid and data element.
For Data Element 1001 to 2000
Step2 Traverse through each element or instance and find the closest cluster. In this case I take the Euclidean distance between the various dimension of cluster centroid and data element.
….
Flow Chart of KMean algorithm:
One can use the KMean java implementation by adding the jar to your project and make use of the main class ‘KMeanAlgorithmThreaded.class’.
Sample Java Code to make use of the algorithm:
double [][] instances;
//Number of cluster user wants to create
int numberOfClusters;
//Number of dimension of each instance.
int dimension;
//Create the KMean algorithm object.
KMeanAlgorithmThreaded kMeanObject = new KMeanAlgorithmThreaded(instances, numberOfClusters, dimension);
kMeanObject.createClusters(100); //run maximum of 100 iteration.
- getClusterElementIDs(int index); // get the list of elements in a cluster index.
Download the KMean.jar file from - https://cw.sdn.sap.com/cw/docs/DOC-148472.
Look forward for the feedback on the library and usage scenarios for improving it further accordingly.
