One of the new options available with BW 7.30 is the ‘Data Flow Copy Wizard’. The wizard surely works out its magic when it comes to copying existing data flows. An easy step by step process to create a complete flow based on an existing flow we have in our system, with options to modify, replace or create new objects on the fly.
One of the added advantages of using the ‘Data Flow Copy Wizard’ is that it works well for process chains too. We may use the wizard to copy a process chain. It is really handy when we need to create a new data flow in parallel, while copying a process chain.
Till now we would have used the ‘COPY’ transaction for a process chain while in the change mode.

Then we would exchange the ‘Start’ variant by creating a new one and use it to replace the existing one from the original chain.

But, then our job is only half done if we are going to use the process chain for a new data flow similar to the existing one, or our job has not even started yet if we don’t have the new flow developed and ready. Of course, we would feel good if a little ‘abracadabra’ would have the flow readily copied along with the process chain. Surely it would be weird to have a transaction named such.
Now, let’s look at how the same can be done with the ‘Data Flow Copy Wizard’ without any magical chants that is.
The ‘COPY’ transaction still holds good. Using it, we get the option of doing a ‘Simple Copy’ or using ‘With Wizard’. The ‘Simple Copy’ is our existing copy process.

We may also ‘right-click’ on a process chain and use the ‘copy’ option which would directly take us to the ‘Data Flow Copy’ wizard.

To start with, we may use as template a previously copied process. For every step of the copy process a very detailed explanation is provided as well.

We may choose the number of copies that we wish to create. If we wish to create more than one copy then we have to use ‘placeholders’ to contain the names of the copied objects. A ‘&’ sign in the technical name would be replaced by the ‘placeholders’ given by us, similarly for descriptions we should use ‘&var&’.

In our case shown above, I have used simple numerals for the copied objects. A more rationale choice would be the name of domain or region that we are copying a dataflow for.
The next step would be to copy the process chains. What is used here is a ‘single chain’, if the chain contains any meta-chains below it then those are also available in the wizard to be copied. Or, we may choose a different chain to be replaced as meta-chain here.

In the above process the new chains created would have the technical names as ZSANDBOX_PC1 and ZSANDBOX_PC2, where the numbers 1 and 2 were defined in ‘step 2’ as placeholders.
Next comes the data flow objects starting from the source system and working up our way to InfoProviders and dependent processes.

A Source System cannot be newly created here, but if we choose to, we may use a different source system. If a different source system is used and it is of the same type as the existing one, then in the next step for ‘DataSources’ we may make a copy of the existing DataSource in our new Source System. Also we may create a DataSource in a flat file Source System based on a SAP Source System.

In the above steps I have used the same Source System and DataSource since the flow would only involve different InfoProviders.
All InfoProviders that are part of the data flow would be displayed. For a process chain without any DTP process involved the wizard does not include the ‘InfoProvider’ step.

I have used the copy type ‘Use a different Object’, since the data flow objects like cubes and DSOs were already copied and available. Here again my ‘placeholders’ would denote the object names T_FSHIC1 and T_FSHIC2 for the cube and similarly for the DSOs.
We may choose ‘Create with Template’ copy type which would help us to create a new dataflow in parallel while copying the process chain.
Since the data flow involves InfoSources, the next step is to copy them. If we copy a data flow without InfoSources then this step is automatically skipped by the wizard.
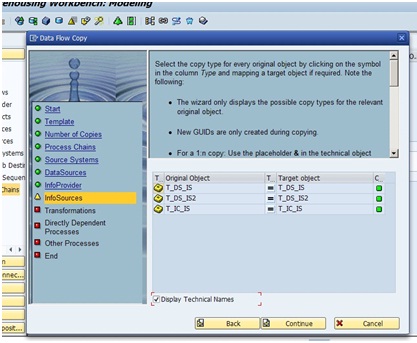
InfoSource is followed by the copy of Transformations. Now the wizard really works its charm.

It’s best to leave things to the wizard, like we see here. Two of the transformations remain the same since my Source System, DataSource and InfoSource are the same. The other three are for the Infoproviders that were added in the new flow. Since we have here two new InfoProviders with InfoSources, two new transformations would be created for each existing transformation for this part of the data flow.
Next comes the actual replication of our Process Chain components.

All the Process Chain variants that are directly related to the data flow are displayed in this step. Variants include InfoPackages, DTPs, Index deletion/creation, DSO activation etc. As we can see the ‘Start’ variant of the Process Chain is not included in this step since it is not dependent on our data flow. Also, we observe that ‘placeholders’ are used here since we would be requiring two copies of each variant for the two new data flows.
All the indirect or non-dependent processes are copied next. This includes the ‘Start’ variant and if there is any ‘Error DTPs’ or process variants that are not data flow dependent.
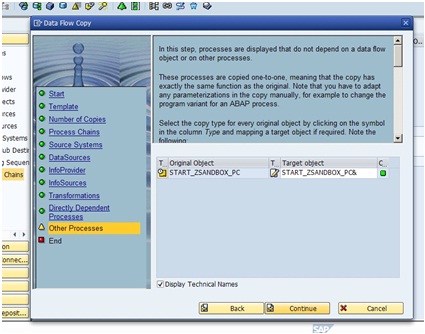
With the copying of indirect objects the whole process is done. We may go back to a particular step any time during the whole process.

Once we hit the ‘Finish’ button, we may choose to run the copy process in ‘Dialog’ or in ‘Background’

Running it in ‘Dialog’ would give us the log of the copy process up front. Else we may use the transaction ‘RSCOPY’ to view the log

All logs of the Data Flow Copy wizard are available in RSCOPY. Should we need to repeat a copy process again we may use the log as template and start creating a copy. Alternatively the logs are also displayed in the first screen of the wizard in a drop down.

Now, in RSPC we can see the copies of our original chain.

The individual variants in the copied process chains have also been modified by the wizard to include the objects specific to that particular flow. This includes DTPs, activation, index creation/deletion blocks, variants for PSA deletion etc.


We do not have to worry about missed out or misplaced variants while copying process chains using the wizard.
Truly magical, wouldn’t you agree.
