
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- BW 7.30: Modeling integration between SAP Business...
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
thomas_rinneber
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-07-2011
6:58 PM
In my BW 7.30: Modeling integration between SAP Business Objects Data Services and BW | Part 1 of 2 – Conn..., I showed how a Business Objects Data Services Source System can be created in BW 7.30. Today, I will tell you, how you continue accessing a particular table in the remote MySQL database, which we connected via data services.
We stopped after successful creation of the source system. Now let’s doubleclick it and like for any other source system, we jump to the corresponding data source tree. Disappointingly, there is no data source available yet. So let’s create one and go to the extraction tab!
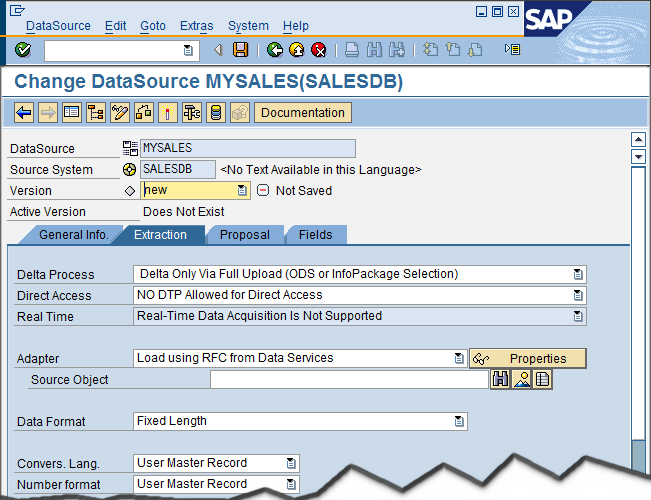
Though in general this DataSource looks similar to any other, there is a new adapter, called “Load using RFC from Data Services”. We can specify a source object, and there are three different value help buttons beside this field. Let’s type “*sales*” (our table is a sales table 😉 and try the first button (search):

Yes, this is the one we are looking for. Anyhow, what will the second button (overview) bring?
A hierarchical overview over all tables. If we expand the node, we find our table again:
Let me skip the third button for the moment and select our table, then go to the next tab of the DataSource maintenance (Proposal).

This action will do two things: First of all, the list of fields is retrieved from data services. And second, the table definition is imported into the data services repository, which is attached to our source system. Because data services does just a similar thing like BW: A metadata upload from the source into the repository. Now we understand the third button on the previous tab: It lists all sources, which are already imported into the repository. This option is useful, because for big source systems, the retrieval of the already imported tables from the repository can be a lot faster than browsing through all tables of the source. And the list is probably much smaller.
We now can go to the fields tab and finalize the maintenance of the DataSource as usual (e.g. make the PRODID a selectable field), then save and activate. This will generate structures, PSA and program, but not do any action in the data services repository.
The next thing to do is create an Infopackage. For loading from data services, as from any BAPI source system, an Infopackage is mandatory, because the data is actively sent to BW, not pulled, and hence the DTP cannot access it.

Entering selections in the infopackage when loading from data services was not possible with prior releases, because the selection condition is part of the query transform in the data services data flow, not a variable when starting the job. However now, saving the infopackage will generate the data flow in the first place. Hence we have the possibility to generate the where-statement into the query transform, reflecting the selection condition entered in the infopackage.
On the extraction tab, the information of the Extraction tab of the DataSource is repeated as usual. Let me go to the 3rd Party Selections.

None of the fields is input enabled. The repository and the JobServer are copied from the source system attributes which you maintained when you created the source system. Also the Jobname is generated. Each InfoPackage will generate a separate data flow and job named infopackage@bw-system. By this, you have no trouble with transports, because even if you use the same repository for connecting to your productive and your development BW, the generated jobs are named different and thus do not interfere. You can just transport the infopackage. The job and flow will be automatically generated when the infopackage is saved or executed the first time. If the infopackage and DataSource definition do not change (i.e. also the selection conditions stay the same), the job and flow are generated only once. Each time something changes (e.g. with dynamic selection conditions), the job and flow are re-generated before the data load request is created.
One remark to the field “Maximum connections”: This is the degree of parallelism which shall be used to load data to BW, comparable with what you can maintain in transaction SMQS for ABAP source systems. There is also the parameter for the package size available via Menu “Scheduler” – “DataS. Default Data Transfer”. Both parameters are transferred into the generated data flow, i.e. the BW target DataSource.
Now you might have one obvious question. What if you want to have a more complex data flow, e.g. containing data quality transform or joins? The answer is: In this case, you must not enter a data store when creating the source system:
Then the Data Services Adapter is not available in the DataSource and you have (mostly) a standard BAPI source system, where you have to enter the fields of the DataSource yourself as usual:
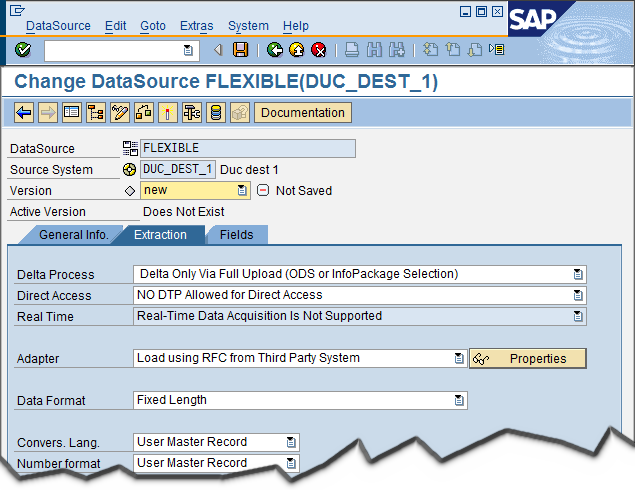
You then can create your own job in data services (and make sure it indeed loads into your DataSource) and enter the Jobname in the InfoPackage manually (resp. via value help):


The repository and JobServer still are copied from the Source System.
Don't miss any of the other Information on BW 7.30 which you can find SAP BW Developers SDN Blog Series Accompanying the BW 7.3 Ramp-Up Phase
3 Comments
Related Content
- Expanding Our Horizons: SAP's Build-Out and Datacenter Strategy for SAP Business Technology Platform in Technology Blogs by SAP
- SAP Sustainability for Financial Services - Portfolio and Solutions in Financial Management Blogs by SAP
- Configuring SAP CI/CD pipeline for Deploying ReactJS application in Cloud Foundry in Technology Q&A
- SAP Business Network for Logistics 2404 Release – What’s New? in Supply Chain Management Blogs by SAP
- SAP Build Process Automation Pre-built content for Finance Use cases in Technology Blogs by SAP