Sometimes you have to extract a large number of records from a huge database table. This was the case with a custom ABAP program that prepares F110S Payment Runs for SAP mega customers. As part of the custom ABAP program algorithm, a simple SELECT statement is executed on BSIK table that contains over 60 million records. The SELECT statement extracts information from 25 fields of 6-8 million BSIK records and manipulates it to prepare multiple F110S Payment Runs. It takes for the custom ABAP program on average over 1 hour 30 minutes to do the job on powerful production system with multiple application servers. The custom program spends around 90% of time in a single SELECT statement that extracts BSIK data. The SELECT statement was optimized. The BSIK database table and its indexes were tuned up by BASIS team to speed up the process. Three application servers server group was dedicated to the payment process. Still the process was taking a long time to complete. The entire payment process could not be squeezed into allocated time slot.
For a time it looked that nothing else could be done – that the limitation of the system was reached. However, when you look closer at task at hand, you would notice that the custom ABAP program schedules multiple F110S jobs to run standard SAP payment processes in parallel. The custom ABAP program itself runs as a single process and it seems that it cannot be divided into multiple processes because of a single SELECT statement that consumes over 90% of its total runtime. The SELECT statement pseudo-code looks as shown in the following table:

The above select statement selects BSIK records for 2 company codes and for the entire numeric vendor range 1000000000 to 9999999999, selecting 6 to 8 million records out of 60 to 80 million records BSIK table consuming more than 90 minutes of runtime.
Since the production system is a powerful multi server system, the question is how to utilize its full power for executing a single SELECT statement. If you would divide a single SELECT statement into multiple SELECT statements for unique vendor sub ranges and execute them in parallel you might get results faster even so multiple application servers will be accessing a single database server to get data.
The question is how to determine the vendor sub ranges for multiple SELECT statement jobs. If you use simple approach and define vendor sub ranges as 1000000000-1999999999, 2000000000-2999999999, 3000000000-3999999999, … you might get uneven distribution of number of BSIK records in each vendor sub range as shown on the following diagram:
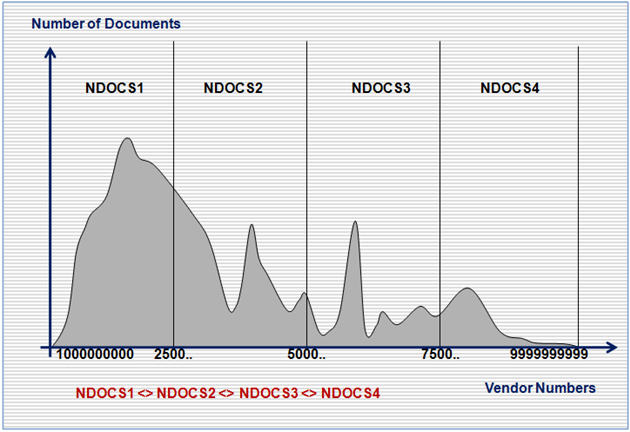
The sub-ranges as above will cause SELECT statement jobs to be unbalanced – one extracting a large number of records and running long time and another one extracting a small number of records and running short time.
It is important to balance a number of records in each SELECT statement job so they will be extracting similar number of records and having approximately similar runtime. The more balanced vendor sub range is shown on the following diagram:
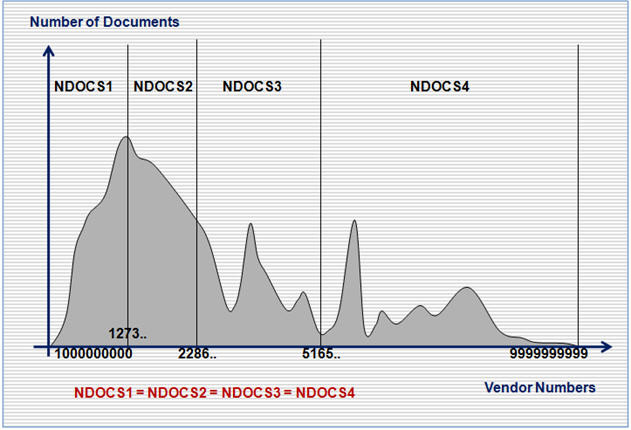
The prototype ABAP programs were written to calculate balanced vendor sub ranges and then to execute a single SELECT statement on 1000000000-9999999999 vendor range as multiple SELECT statement jobs on balanced vendor sub ranges running in N parallel processes.
The following parallel SELECT statement prototype programs were written:
- ZAWB_PARALEL_SELECT_RUN – starts the process, waits for all SELECT jobs to finish and imports retrieved BSIK data from INDX like table
- ZAWB_ PARALEL_SELECT_SCH – calculates vendor sub ranges and schedules parallel SELECT jobs
- ZAWB_ PARALEL_SELECT_GET – retrieves BSIK data for vendor sub ranges and exports it to INDX like database table
The prototype was tested on Q&A and Volume Performance Testing systems running up to 7 times than a test program with equivalent single SELECT statement. The prototype was tested with 2 to 80 parallel processes running on multiples application servers.
The best performance was achieved when number of parallel runs was equal or multiple of total number of available background processes on dedicated application servers; i.e., when running the prototype on 2 application servers with 20 available background processes, the best results were achieved when splitting SELECT statement into 20, 40, … parallel jobs.
The parallel SELECT statement jobs algorithm was implemented into the custom ABAP payment program dramatically improving its performance on the production system. The runtime was reduced on average from more than 1 hour 30 minutes to around 15 minutes.
