
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- BW 7.30: Data Flow Copy Wizard
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
thomas_rinneber
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-08-2010
8:08 AM
If you have read my blog about the BW 7.30: Simple modeling of simple data flows, you have learned already about one tool, which will ease the work to create a BW data flow. However it might be that you have done this already and heavily changed the generated objects to suite your needs. Now it comes that you need to create another data flow, which looks quite similar to the one you have already created. Only the target would be a little different. Or you need to load from another DataSource in addition. Or from another source system (maybe a dummy source system? Cf. my BW 7.30: Transport support in BW landscapes). Too bad, that you need to do all your modifications again!
No – because with BW 7.30 there also is – the Data Flow Copy Wizard.
And again, we start in the data warehousing workbench RSA1.
Let’s display the data flow graphically:

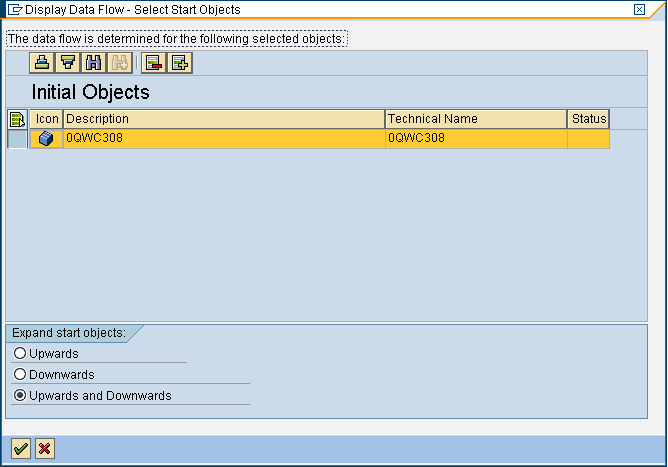
Now, if we want to copy this data flow, we just need to choose “Copy data flow” instead “Display data flow”. Again, you can choose in which direction the objects shall be collected.


The system asks you whether you want to collect also process objects or only data model objects. Why this? The process objects usually are included in a process chain. And if you intend to copy the process objects, you should start copying with the process chain. We will try this out later, but for now, let’s press “No” and sneak into the Wizard itself.
Looking at the step list on the left, it seems like the objects to be copied are divided up into the various object types. However the order is strange, isn’t it? It is by purpose, and you will (hopefully) understand, if you read the lengthy explanation in above screen shot 😉 Ok, let us start with the first step, “number of copies”!
I have already chosen two copies, else this step can be skipped. Now what do these “replacements” mean? Usually, when copies are performed, the objects are related to the original objects in terms of naming conventions. At least, for each object to be copied, you need to enter a new name. Now if you are going to create two copies at a time, you would need to enter two new names for each object. In order to simplify this, you can enter a placeholder & in the new object name and &VAR& in the description, and the placeholder will be replaced with what you specify in above screen. It could look like this:

So from an object e.g. ZWQC_& (Sales for &VAR&) two objects can be created with names ZWQC_USA (Sales for States) and ZWQC_EMEA (Sales for Europe and Asia).
Now the actual copy customizing starts. All following steps have the elements already visible on above screen: For any original object the target object can be specified in several ways when clicking on the column in the middle:

- You can use the original object uncopied. This means the original object will be included into the copied data flow. By this, you can, depending on the object that you keep
- Add a new load branch to an existing data target
- Create a new DataSource for the same source system
- Load the same DataSource from another source system
- Load an existing DataSource into a new target
- You can use a different, already existing object. This will include the specified object into your copied data flow. You might have created the InfoProvider already, but you want to copy the transformation from an already existing transformation. For object type source system like shown above, the source system must have been created before you start the wizard.
- You can create a new object as copy of the original object. This is the standard option that you would like to use, and the one, which is not available for source systems 😉
- You can exclude the object from the further copy process. This means, that also all objects dependent on the excluded object will be excluded from the copy process. So if you exclude the source system, you will automatically exclude the DataSource and the corresponding Transformation as well. It will leave only the DataStore and InfoCube to be tackled and the transformation between.

Then the wizard gives me no choice for messing up with the corresponding transformations in the next step:

This help you will especially appreciate, if it comes to deep copy of process chains. Let’s try this out. I exit the wizard.
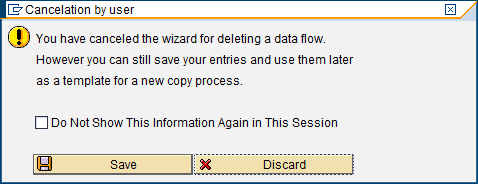
Oops, I can save my entries!? That sounds like a useful feature. Indeed, if I would have continued the wizard to the end and actually performed the copy, my entries were saved automatically. So if I am going to change something with the original objects and want to propagate this change to the copies I had made, I am offered the following additional step in the wizard:
Having this, I can very swiftly walk through the steps which carry already my settings from the chosen previous copy process. I just need to exclude some of the objects whose changes I do not want to copy over (or rather use the already copied objects). And moreover there is transaction RSCOPY, which shows me which copy processes I have already undertaken. We will come back to this later, now we wanted to look at the process chain copy. Let us choose menu “process chain” -> “copy” in the process chain maintenance:

Of course we want to use the wizard. This time we are not asked whether we want to collect process objects as well 😉 Instead, the step list contains some more steps:

Let’s fast forward to “Process Chains”.

The system assumes we want to copy the process chain (how intelligent 😉 and thus confronts us with a popup where we could change the target object name and description. Having filled it out, the wizard shows us another chain as well, the subchain of the selected one:
Let us keep that re-use subchain and fast forward to the “directly dependent processes”…
STOP! What is this? I cannot change the source system? Why can’t I change the source system? Go on: I cannot change any of the DataSources, InfoProvider and Transformations! So we tricked ourselves: By not copying the subchain, we are still referring the original data flow in our copy (in the subchain). The system ensures that the outcome is consistent so it does not let me choose another data flow. Ok, convinced. I will copy the subchain as well. Now I am allowed to do my changes concerning the InfoCube as before. Puh.

So these are the “directly dependent objects” – directly dependent on a data flow object. Since I have copied the InfoCube only, the system proposes me to keep most of the processes, but only create a new DTP for the new data flow branch plus a data deletion process. We can double click on the original object "0WQ_308_DELDELTA" to see what it looks like.
It contains both DataStore and InfoCube. If I copy it, the InfoCube would be replaced by my new InfoCube in the copy. But the DataStore would still be in it. Well, it shall be a copy… Also, if I look at the list of processes above, I see that the InfoPackages and DataStore will be loaded in my new chain as well as in my old chain. Not such a good idea. Maybe it would be better to copy the data flow only and modify my existing chain such that it drops and loads the new cube in addition to the old one. So the system does not totally relief me from thinking myself…
Ok, let us continue with our chain copy anyhow to see the outcome.
These are the data flow independent processes; we have to choose names for the triggers, alright. There is one step missing in our example, since we have no such processes in our chain, these are the “indirectly dependent processes”, which refer to a “directly dependent process” in turn.
Let us go to the end and execute.

We choose "In Dialog".
Everything worked. And what is the result?
The target chain looks quite alike the old one, except the subchain and DTP we have copied as well. And how does the data flow look like now?
That’s a nice result, isn’t it? So we have a new cube as copy of the old one, plus the transformation and DTP.
But now I had promised to show you transaction RSCOPY where we can see the logs of our copy processes:
Oops, there is a red icon. I have hidden this attempt from you, but now it comes to the bright daylight that I had made a mistake. Let’s double click it!
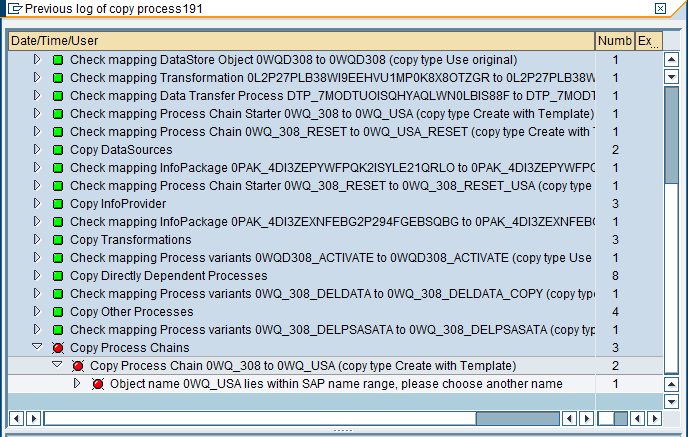
I missed to remove the starting “0” from the process chain name. And how did I recover this? I just started the wizard again, chose this failed copy process as a template (you can see it in the column “template” in the previous screen shot of transaction RSCOPY) and just corrected my fault. The copy then was executed to the end.
Don't miss any of the other Information on BW 7.30 which you can find SAP Business Warehouse 7.3
1 Comment
Related Content
- Configure Custom SAP IAS tenant with SAP BTP Kyma runtime environment in Technology Blogs by SAP
- How to build SOAP service in SAP Cloud Integration in Technology Blogs by Members
- Single Sign On to SAP Cloud Integration (CPI runtime) from an external Identity Provider in Technology Blogs by SAP
- SAP BTP SDK for Android 24.4.0 is now available in Technology Blogs by SAP
- SAP Community Datasphere in Technology Q&A