
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- BW 7.3: Troubleshooting Real-Time Data Acquisition
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-08-2010
8:07 AM
The main advantage of real-time data acquisition (RDA) is that new data is reflected in your BI reports just a few minutes after being entered in your operational systems. RDA therefore supports your business users to make their tactical decisions on a day-by-day basis. The drawback however is that these business users notice much faster when one of their BI reports is not up to date. They might call you then and ask why the document posted 5 minutes ago is not visible yet in reporting. And what do you do now? I’ll show you how BW 7.3 helps you to resolve problems with real-time data acquisition faster than ever before.
First, let’s have a look at what else is new to RDA in BW 7.3. The most powerful extension is definitely the HybridProvider. By using RDA to transfer transactional data into a HybridProvider, you can easily combine the low data latency of RDA with the fast response times of an InfoCube or a BWA index, even for large amounts of data. You’ll find more information about this combination in a separate blog. Additionally. BW 7.3 allows for real-time master data acquisition. This means that you can transfer delta records to InfoObject attributes and texts at a frequency of one per minute. And just like RDA directly activates data transferred to a DataStore object, master data transferred to an InfoObject becomes available for BI reporting immediately.
But now, let’s start the RDA monitor and look at my examples for RDA troubleshooting. I’ve chosen some data flows from my BW 7.0 test content and added a HybridProvider and an InfoObject. I know that this flight booking stuff is not really exciting, but the good thing is that I can break it without getting calls from business users.

Remember that you can double-click on the objects in the first column to view details. You can look up for example that I’ve configured to stop RDA requests after 13 errors.

Everything looks fine. So let’s start the RDA daemon. It will execute all the InfoPackages and DTPs assigned to it at a frequency of one per minute. But wait… what’s this?

The system asks me whether I’d like to start a repair process chain to transfer missing requests to one of the data targets. Why? Ah, okay… I’ve added a DTP for the newly created HybridProvider but forgotten to transfer the requests already loaded from the DataSource. Let’s have a closer look at these repair process chains while they are taking care of the missing requests.

On the left hand side, you can see the repair process chain for my HybridProvider. Besides the DTP, it also contains a process to activate DataStore object data and a subchain generated by my HybridProvider to transfer data into the InfoCube part. On the right hand side, you can see the repair process chain for my airline attributes which contains an attribute change run. Fortunately, you don’t need to bother with these details – the system is doing that for you. But now let’s really start the RDA daemon.

Green traffic lights appear in front of the InfoPackages and DTPs. I refresh the RDA monitor. Requests appear and show a yellow status while they load new data package by package. The machine is running and I can go and work on something else now.
About a day later, I start the RDA monitor again and get a shock. What has happened?

The traffic lights in front of the InfoPackages and DTPs have turned red. The RDA daemon is showing the flash symbol which means that is has terminated. Don’t panic! It’s BW 7.3. The third column helps me to get a quick overview: 42 errors have occurred under my daemon, 4 DTPs have encountered serious problems (red LEDs), and 4 InfoPackages have encountered tolerable errors (yellow LEDs). I double-click on “42” to get more details.

Here you can see in one table which objects ran into which problem at what time. I recognize at a glance that 4 InfoPackages repeatedly failed to open an RFC connection at around 16:00. The root cause is probably the same, and the timestamps hopefully indicate that it has already been removed (No more RFC issues after 16:07). I cannot find a similar pattern for the DTP errors. This indicates different root causes. Finally, I can see that the two most recent runtime errors were not caught and thus the RDA daemon has terminated. You can scroll to the right to get more context information regarding the background job, the request, the data package, and the number of records in the request.

Let’s have a short break to draw a comparison. What would you do in BW 7.0? 1) You could double-click on a failed request to analyze it. This is still the best option to analyze the red DTP requests in our example. But you could not find the tolerable RFC problems and runtime errors.

2) You could browse through the job overview and the job logs. This would have been the preferable approach to investigate the runtime errors in our example. The job durations and the timestamps in the job log also provide a good basis to locate performance issues, for example in transformations.

3) You could browse through the application logs. These contain more details than the job logs. The drawback however is that the application log is lost if runtime errors occur.
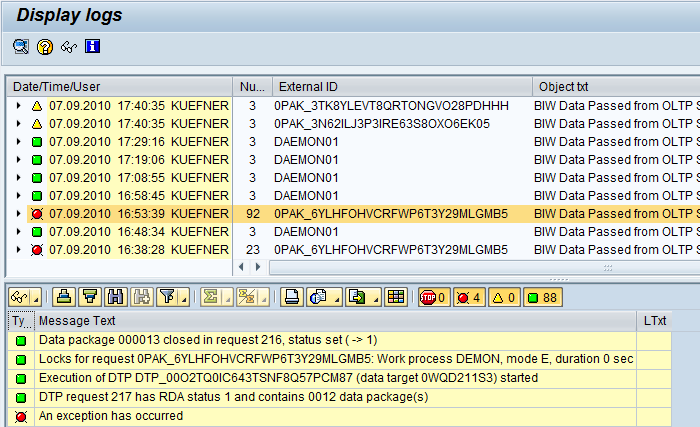
These three options are still available in BW 7.3 – they have even been improved. In particular, the job and application logs have been reduced to the essential messages. Locating a problem is still a cumbersome task however if you don’t know when it occurred. The integrated error overview in the RDA monitor, BW 7.3 allows you to analyze any problem with the preferred tool. Let me show you some examples.
Unless you have other priorities from your business users I’d suggest starting with runtime errors because they affect all objects assigned to the daemon. RDA background jobs are scheduled with a period of 15 minutes to make them robust against runtime errors. In our example, this means the RDA daemon serves all DataSources from the one with the lowest error counter up to the one which causes the runtime. The job is then terminated and restarted 15 minutes later. The actual frequency is thus reduced from 60/h to 4/h, which is not real-time anymore. Let’s see what we can do here. I’ll double-click on “10” in the error column for the request where the problem has occurred.

I just double-click on the error message in the overview to analyze the short dump.

Puh… This sounds like sabotage! How can I preserve the other process objects assigned to the same daemon from this runtime error while I search for the root cause? I could just wait another hour of course. This RDA request will then probably have reached the limit of 13 errors that I configured with the InfoPackage. Once this threshold is reached, the RDA daemon will exclude this InfoPackage from execution. The smarter alternative is to temporarily stop the upload and delete the assignment to the daemon.

The overall situation becomes less serious once the DataSource has been isolated under “Unassigned Nodes”. The daemon continues at a frequency of onc per minute although there are still 32 errors left.

Note that most of these errors – namely the RFC failures – can be tolerated. This means that these errors (yellow LEDs) do not hinder InfoPackages or DTPs until the configured error limit is reached. Assume that I’ve identified the root cause for the RFC failures as a temporary issue. I should then reset the error counter for all objects that have not encountered other problems. This function is available in the menu and context menu. The error counter of an InfoPackage or DTP is reset automatically when a new request is created. Now let’s look at one of the serious problems. I’ll therefore double-click on “2” in the error column of the first DTP with red LED.

When I double-click on the error message, I see the exception stack unpacked. Unfortunately that does not tell me more than I already knew: An exception has occurred in a sub step of the DTP. So I navigate to the DTP monitor by double-clicking the request ID (217).

Obviously, one of the transformation rules contains a routine that has raised the exception “13 is an unlucky number”. I navigate to the transformation and identify the root cause quickly.

In the same way, I investigate the exception which has occurred in DTP request 219. The DTP monitor tells me that something is wrong with a transferred fiscal period. A closer look at the transformation reveals a bug in the rule for the fiscal year variant. Before I can fix the broken rules, I need to remove the assignment of the DataSource to the daemon. When the corrections are done, I schedule the repair process chains to repeat the DTP requests with the fixed transformations. Finally I re-assign the DataSource to the daemon.
The RDA monitor already looks much greener now. Only one DataSource with errors is left. More precisely, there are two DTPs assigned to this DataSource which encountered intolerable errors, so the request status is red. Again, I double-click in the error column to view details.

The error message tells me straight away that the update command has caused the problem this time rather than the transformation. Again, the DTP monitor provides insight into the problem.

Of course “GCS” is not a valid currency (Should that be “Galactic Credit Standard” or what?). I go back to the RDA monitor and double-click on the PSA of the DataSource in the second column. In the request overview, I mark the source request of the failed DTP request and view the content of the problematic data package number 000006.

Obviously, the data is already wrong in the DataSource. How could this happen? Ah, okay… It’s an InfoPackage for Web Service (Push). Probably the source is not an SAP system, and a data cleansing step is needed – either in the source system or in the transformation. As a short-term solution, I could delete or modify the inconsistent records and repeat the failed DTP requests with the repair process chain.
That’s all. I hope you enjoyed this little trip to troubleshooting real-time data acquisition, even though this is probably not part of your daily work yet. Let me summarize what to do if problems occur with RDA. Don’t panic. BW 7.3 helps you to identify and resolve problems faster than ever before. Check the error column in the RDA monitor to get a quick overview. Double-click wherever you are to get more details. Use the repair process chains to repeat broken DTP requests.
Disclaimer
http://www.sdn.sap.com/irj/sdn/index?rid=/webcontent/uuid/b0b72642-0fd9-2d10-38a9-c57db30b522e
3 Comments
Related Content
- SAP Datasphere News in August in Technology Blogs by SAP
- Sustainability with SAP S/4HANA Cloud, Public Edition 2308 in Enterprise Resource Planning Blogs by SAP
- GRC Tuesdays: How To Calculate the ROI of an Integrated Risk and Control Platform to Justify Investment in Financial Management Blogs by SAP
- ABSO TType 105/160 doesn't reverse the accumulated dep. in area 02 in Enterprise Resource Planning Q&A
- Data Architecture with SAP – Data Lake in Technology Blogs by Members