
- SAP Community
- Products and Technology
- Additional Blogs by Members
- Performance optimization of SQL statements in ABAP
Additional Blogs by Members
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member20
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-24-2010
3:35 AM
In this session I have explained the concepts of DB optimizer and how it parses a SQL query to create an evaluation path. I have given examples of how to improve the performance of SQL statements in ABAP by changing the WHERE clause. I am assuming readers are familiar with transactions SE30 and ST05.
Note: below SQL traces are from DB2 database and results may vary for other Databases.
Consider simple select statement:SELECT * from MARA where MATNR = ‘ACFBAS2’ .
Here Database has 3 possible search strategies to find the record and which path to choose is decided by the optimizer.
- search the entire table
- use the Primary index for search
- use secondary index of search
Optimizer: optimizer is database program that parses the SQL statement and considers each access path (full scan, primary index, secondary index) and formulates an execution plan for the SQL statement. There are 2 types of optimizers
Rule-Based Optimizer: based on available indexes and the fields used in WHERE clause, RBO creates its execution plan. The most import criteria in the WHERE clause are the fields that are specified with an EQUALS condition and that appear in an index.
Cost-Based Optimizer: to create the execution plan for an SQL statement, the CBO considers the same criteria as RBO plus
- Table Size: for small tables, the CBO decides to avoid indexes in favor of a more efficient full table scan. Large tables are more likely to be accessed through index.
- Selectivity of the index fields: the selectivity of a given index field is the average size of the portion of the table that is read when an SQL statement searches for a particular distinct value in that field. Ex:- if there are 200 contract types and 10,000 actual contracts in VBAK table, then the selectivity of the field doc type is 10,000 divided by 200 which is 50 or 2% of 10,000. The larger the number of distinct values in a field the more likely the optimizer will use the index based on that field.
- Physical Storage: the optimizer considers how many index data blocks or pages must be read physically on the hard drive. The more physical memory that needs to be read, the less likely that an index is used.
Example 1: create a database table ZKUM_TEST with fields F1,F2,..to F10. And F1,F2,F3,F4 are key fields of the table i.e. primary keys. Now consider below selects

1. SELECT * FROM ZKUM_TEST INTO TABLE ITAB WHERE F2 = '1' and F3 = '3' :Here optimizer will not use the primary index for the search operation because F1 is missing in the where clause. so a full table scan is performed.
2. SELECT * FROM ZKUM_TEST INTO TABLE ITAB WHERE F1 = '2' and F2 = '3' : Here if there is no secondary index on fields F1 and F2 then optimizer will choose primary index as two fields out of 4 are matched.
3.SELECT * FROM ZKUM_TEST INTO TABLE ITAB WHERE F1 <> '2' and F2 = '3' and F3 = '3': here optimizer will not use the primary index as theoperator NOT is used for comparision for column F1. If there is any secondary index on columns F2, F3 then optimizer will use secondary index.
To make the right decision on optimal access, the CBO requires statistics on the sizes of tables and indexes. The statistics must be periodically generated to bring them up to date. Standard SAP reports are available to generate these statistics (transaction DB13).The advantage of CBO is its flexibility, because it considers the selectivity of specified fields.
ex:- SELECT * FROM MARA WHERE MANDT= ‘020’ and BISMT = ‘a1’.
Here the CBO knows that MANDT contains only one distinct value would decide on a full table scan, where as the RBO would choose the less-effective index range scan.
| Access Path | With Index based on Fields | Runtime in microseconds | |
| Without table access statistics Without secondary index based on the field BISMT | Index range scan | MANDT,MATNR | 3,500,000 |
| With table access statisticsWithout secondary index based on the field BISMT | Full table scan | N/A | 500,000 |
| With table access statistics With secondary index based on the field BISMT | Index range scan | BISMT | 3000 |
Rules for efficient SQL programming:
- SQL statements must have a WHERE clause that transfers only a minimal amount of data. Avoid using NOT conditions in the WHERE clause. These cannot be processed through an index. Avoid using identical selects, you can identify this in ST05
- Use SELECT column1 column2 ….instead of SELCT *
- The WHERE clauses must be simple; otherwise the optimizer may decide on the wrong index or not use an index at all. A where clause is simple if it specifies each field of the index using AND and an equals condition
- Use FOR ALL ENTRIES instead of SELCTS inside LOOPS. When using FAE make sure internal table is not empty and must not contain duplicates.Depending on the database system, the database interface translates a FAE into various SQL statements, it can translate into SQL statements using an IN or UNION operator
If you are pulling large volumes of data from multiple tables, then better to create a data base view rather than using FOR ALL ENTRIES.
Example 2:
Run SQL trace for below select statements .
- SELECT mandt vbeln posnr FROM vbap INTO TABLE itab WHERE erdat in s_erdat.
- IF itab[] IS NOT INITIAL.
select mandt vbeln posnr from vbap into table itab
for ALL ENTRIES IN itab
where vbeln = itab-vbeln and posnr = itab-posnr.
ENDIF.
First Select:
For the first SELECT, whole table is scanned as there is no matching index found (because the columns mentioned in the WHERE clause are not part of either primary key or seconday key). To know the no.of hits to Database, click on ‘Summarize Trace by SQL statements’ from menu path ‘Trace List’ , this will group the identical selects .
For the first select only one hit to DB where as for second select 3210 hits to DB, see below for details. column 'Executions' gives you no.of hits to DB.

Click on ‘Explain’ button for first select to know the access path i.e. which index is used. here no matching index found , so entire table will be scanned.
In below screen shot you can see only one column i.e. MANDT is matched out of 3 columns of the primay index. so whole table is scanned.

Second Select :![]() internal table ITAB[] is having around 32K records.
internal table ITAB[] is having around 32K records.
in SQL trace click on display for second SQL, you will notice the FOR ALL ENTRIES IN TABLE construct is changed to 'UNION ALL ' and a subquery by the DB optimizer.
No.of hits to DB is 3210

UNION : The UNION command is used to select related information from two tables, much like the JOIN command. The UNION ALL command is equal to the UNION command, except that UNION ALL selects all values.
In the above example a single SELECT statement is split into multiple selects by the DB optimized and with a sub-query (i.e UNION ALL) and passed to the database.
In this example ITAB is having around 32K records and 10 records are passed with each select resulting in 3210 hits to database.
Total duration for first SELECT : 2,167,664 micro seconds
Total duration for second SELECT : 6,739,983 micro seconds.
Now change the second select such a way that optimizer will not use sub-query with UNION ALL construct. POSNR is commented out.
Modified code:
SORT ITAB BY VBELN.
DELETE ADJACENT DUPLICATES FROM ITAB COMPARING VBELN.
SELECT mandt vbeln posnr FROM vbap INTO TABLE itab
for ALL ENTRIES IN itab
where vbeln = itab-vbeln ." and posnr = itab-posnr.
No.of hits to DB came down to 189 and total duration came down to 453,742 micro seconds.

click on 'Explain' button to know the access path. Here in this case FOR ALL ENTRIES IN TABLE construct is changed to 'IN' clause by the DB optimizer.
Bunch of values (around 30 contract numbers ) are passed in each select there by reducing the no.of hits to database. Optimizer still used the primay index as two columns mentioned in WHERE clause (MANDT,VEBLN) matched with the primary keys of the table.

The runtime shown in the trace includes not only the time required by the database to furnish the requested data, but also the time required to transfer data between database and the application server. If there is a performance problem in network communication, the runtimes of SQL statements increase. So take the trace 2-3 times before you come to any conclusion.
As explained above, if there is any performance problems with SELECT statements, first thing you need to check is WHERE caluse, modify the WHERE clause and see if the optimizer uses any available index or not. In case if no available index is used then better create a secondary index to improve the performance.
Please note: when you are pulling data from multiple tables, it is better to join these tables using INNER JOIN, as INNER JOINs perform better than FOR ALL ENTRIES.
Example:3
consider below select: here I am pulling contract line item VC characteristic details. VBAP-CUOBJ is line item VC config number
SELECT a~instance b~in_recno b~symbol_id c~atinn c~atwrt c~atflv
FROM ( ( ibin AS a INNER JOIN ibinvalues AS b ON a~in_recno = b~in_recno )
INNER JOIN ibsymbol AS c ON b~symbol_id = c~symbol_id )
INTO TABLE gt_char_val
FOR ALL ENTRIES IN l_cabn
WHERE a~instance = it_vbap-cuobj AND c~atinn = l_cabn-atinn .
Instead of writing 3 individual select statements on IBIN, IBINVALUES and IBSYMBOL it is better to use INNER JOIN.
SQL trace shows available index is used for each table i.e for table IBIN index 'C' is used , for table IBINVALUES index 'SW0' is used and for table IBSYMBOL index 'SEL' is used, so the performance of the query is good.

So when you are using INNER JOIN on multiple tables better to take SQL trace and check the access path to see if available index is used or not.
Index: IBIN~C is on columns MANDT and INSTANCE
Index: SWO on table IBINVALUES is on columns MANDT, IN_RECNO, SYMBOL_ID, ATZIS and ASSTYP.
Index : SEL on table IBSYMBOL is on columns MANDT, ATINN, ATWRT, ATFLV and SYMBOL_ID.
Creating Seconday Index:
Creating or changing a secondary index can improve or worsen the performance of SQL statements, before creating secondary index check if you can rewrite the ABAP program in such a way that an available index can be used.
Never create a secondary index on SAP basis tables without recommendations from SAP, examples D010,D020, DD*.
Rules for creating Secondary Index:
- Include only selective fields in the index: ex customer number, Material, Contract number
- Include few fields in the index
- Position selective fields to the left in the index
- Index should be Disjunct , avoid creating two or more indexes with largely the same fields
- create few indexes per table
if the SQL statement that searches by means of particular index field would cause more that 5% to 10% of the entire index to be read, the cost-based optimizer does not consider the index is useful and instead chooses the full table scan as the most effective access method.
Example 1: consider below select statement
SELECT MANDT VBELN posnr FROM VBAp into TABLE ITAB WHERE VGBEL IN s_VGBEL.
VGBEL (reference doc number ) is not part of PRIMARY key and also no seconday key exist for that. SQL trace for above select in DB2.
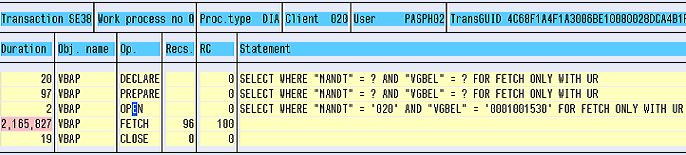
SQL trace:

If you look at access path no matching index found. So we need to check if creating a seconday index on MANDT and VGBEL is a good candidate or not.
Now go to transaction DB05 and input table name and specify the fileds on which you want to create index, and click execute

select the check box 'Submit analysis in background' if table size is large.
output:

ouput showed that VBAP is having 317,272 rows and the No.of distinct VGBEL values out of these 317K records is 5644.
out of these 5644 distinct values
- 4430 ref. documents are having less than 10 enties in VBAP table : means if you do count(*) FROM VBAP and input any of these 4430 ref. document number then line item count will be between 1 to 10.
- 1099 ref. documents are having entries between 10 to 100
- 101 ref. document are having entries between 101 to 1000
- 13 ref. documents are having entries between 1001 to 10,000
- only 1 ref. document is having records more that 100,000 in VBAP: means if you do a count(*) FROM VBAP and input this ref. doc number you get line item count >= 100,001
DB05 analysis showed that most of the ref. documents are having record count between in 1 to 1000 means this is a good candidate for secondary INDEX creation.
Now create a seconday index on VBAP on columns MANDT and VGBEL in SE11 transaction and then run the same query again.

SQL Trace showed run time came down from 2,165,827 ms to 2,026 ms , huge difference.
Example 2: If you want to create index on multiple columns of a table, then analyze the table with respect to those index fields in DB05. consider below analysis of TCURR table.

I run DB05 on TCURR table for fields MANDT, KURST, FCURR,TCURR and GDATU
explanation:
KURST row: no.of distinct exchange rate types in TCURR table is 22 out of which 2 are having record count between 1 to 10. Three rate types are having record count between 11 to 100. And 14 exchange rate types are having count between 101 to 100 etc
FCURR row: no.of distinct values for combination of KURST & FCURR is 1014, out of which 785 combinations are having record count between 1 to 10. And 137 combinations of KURST & FCURR are having record count between 11 to 100. etc
TCURR row: no.of distinct values for combination of KURST , FCURR & TCURR is 1019 out of which 790 combinations are having record count between 1 to 10. etc
GDATU row: no.of distinct values for combination of KURST , FCURR & TCURR and GDATU is 35K i.e only one record per combination as these are part of primary index.
This way DB05 analysis will help you decide whether the columns you choose for index creation is a good candidate or not. If you see in DB05 more records are having record count > 10,000 then it is not a good candidate for index creation.
consider below analysis of BKPF table on TCODE column, definitely this is not a good candidate

Some useful tcodes
DB20
ST04, ST05
SE30
DB05
DB02 for missing indexes.
SE14 for recreating indexes
4 Comments
Related Content
- Kyma Integration with SAP Cloud Logging. Part 2: Let's ship some traces in Technology Blogs by SAP
- SAP Commerce Best Practices for Performance in CRM and CX Blogs by SAP
- Capture Your Own Workload Statistics in the ABAP Environment in the Cloud in Technology Blogs by SAP
- RISE with SAP Advanced Logistics Package in Supply Chain Management Blogs by SAP
- RISE with SAP advanced asset and service management package in Supply Chain Management Blogs by SAP