I'm working on slides for a presentation we're giving at the ASUG 2010 Annual Conference in Orlando next month, realizing that a project lasting more than a year is hard to summarize in under an hour. Then an Oracle consultant suggested I add slides on "block dumps", and while that would be pretty cool stuff for the technically heavy attendees of the Sapphire crowd, oh wait, that's SAP TechEd. So I decided to show those slides in a blog, like a teaser film trailer.
Our session is titled "[Stanley] Black & Decker compresses database objects to save space and money"; I'm merely the co-speaker -- the primary speaker is our lead DBA. My part will be a small section on the performance metrics around the project, though Donna will be drilling into more than a few numbers. Check the Agenda Builder to put the session on your schedule, searching either for Hall or Spath, or Black & Decker, or Session 1014. Oh wait, someone has renamed our session title to "Black & Decker: Compressing Database Objects, Saving Space and Money". Hmm. One downside is that we have the last time slot of the last day of the conference, and are scheduled against Thomas Jung. On the other hand, you could think of our session as the warm-up act for Santana.
Soon after we got our project going a year ago, I post a blog called "Indexes lose weight, wait, waist, and waste". At the time, I drew conclusions about the impact of index compression on our system performance. There were a few comments, particularly from people who have used this on their own systems and done their own measurements. I think the conclusion was you should use compression where it suits your installation the best, and the negatives are rather minor. In our presentation, I'll show updated performance trending, across both software upgrades and hardware changes. We may compare this to fuller system changes like Unicode or platform architecture moves.
One area to consider is local impacts vs. global impacts, especially when deciding where to tune. Large objects are one thing, frequently used and/or business critical transactions are another. Though we'll talk about our project planning thinking, others have started their own in the past couple years since this was available through SAP, supported by Oracle. I've listed pertinent SCN forum posts I found, in a table below, on the primary SAP note [1109743 - Use of Index Key Compression for Oracle Databases].
Stefan Kohler's blog
Stefan wrote nearly 2 years ago about [Oracle] Index key compression. It's a very thorough analysis of the underlying technology, and a bit of testing. Stefan went on to implement this in his production system, as documented in later blog and forum comments. There's not much I can add, but I'll try. We tend to look both at the SAP interfaces, such as ST04, and the "BR" tools, but also through SQL*Plus and OEM. Your shop may nor may not have the licenses, or the expertise to best leverage these techniques.
One example would be object statistics. We're probably not going to collect new statistics, even after doing index compression. I'll show one example below where we've done some custom tuning.
SAP Note Update
As I read and re-read Note 1109743 in order to prepare slides, and to prepare to speak intelligently, I learned a couple things that might not have been known a year or 2 ago when index compression was first discussed on SDN.
The first new wrinkle is 2 example scripts provided in the Note, apparently with version 33 around July 2009. They're called:
- IX_COMP_OFFLINE_TYPICAL.txt
- IX_COMP_ONLINE_TYPICAL.txt
The Note text says these are suggested SQL statements, based on the experience of many SAP customers. The cool part is this chops out one of the harder parts of index compression - determining which objects can benefit from compression, and generating the code. "Cookie Cutter" recipes to the rescue!
Would we use these statements? Maybe, except we've already done our own analysis and run similar statements. How similar? Let's look, eh?
Comparison 1
Us:
alter index "SAPR3"."CDCLS~0" rebuild online compress 3 parallel 4 pctfree 1 nologging;
alter index "SAPR3"."CDCLS~0" noparallel;
ORACLE [ONLINE TYPICAL]:
alter index "SAPSR3"."CDCLS~0" rebuild online compress 2 parallel 4 pctfree 1;
alter index "SAPSR3"."CDCLS~0" noparallel;
ORACLE [OFFLINE TYPICAL]:
alter index "SAPSR3"."CDCLS~0" rebuild compress 2 parallel 4 pctfree 1;
alter index "SAPSR3"."CDCLS~0" noparallel;
Our compression factor was 3, compared to the SAP value of 2. Not a lot of difference. And we chose "nologging" which you should only do if you understand the risk and back up the object immediately.
Comparison 2
(I'll strip out the common elements, and just show any differences, now that you can see the syntax)
MSEG
| Index | SAP compression | Our compression
|
| ~0 | 3 | 3 |
| ~M | 6 | 6 |
| ~R | 2 | 2 |
| ~S | 3 | 3 |
| ~Z03 | - | 3 |
| ~Z1 | - | 3 |
Comparison 3
CHDHR
| Index | SAP compression | Our compression |
| ~0 | 3 | 3 |
| ~001 | - | 1 |
| ~002 | - | 2 |
| ~Z01 | - | 3 |
Cool - no differences in compression factor, just a few more indexes on our side than the sample script.
Generate the code
The other changed aspect of the note is a newer PL-SQL script to evaluate your systems and propose index compression code. If you downloaded the note more than 6 months ago, go back and check the version number in the code text. Here's what I see today:
| Updated by Joern Bartels Version 3.0 15-oct-2009 |
The code is called "ind_comp3p.txt" as well, but I'm not sure what the "p" means - production?
The one we used before was:
| Updated by Joern Bartels Version 1.1 15-dec-2008 |
Forum links
(newest at the top)
And now, screen shots!
The first 4 are slices of the leaf block in a compressed index. The index has one column - document line number - with about the same number of rows in this quality system as the production one. It is one we built:
S713~Z1 S713 VBELN 1 30
NUM_ROWS LAST_ANA
---------- ---------
28515650 10-MAY-08
COUNT(*)
----------
41967589
alter system dump datafile [etc.]
INDEX_NAME COMPRESS
------------------------------ --------
S713~0 ENABLED
S713~Z1 ENABLED

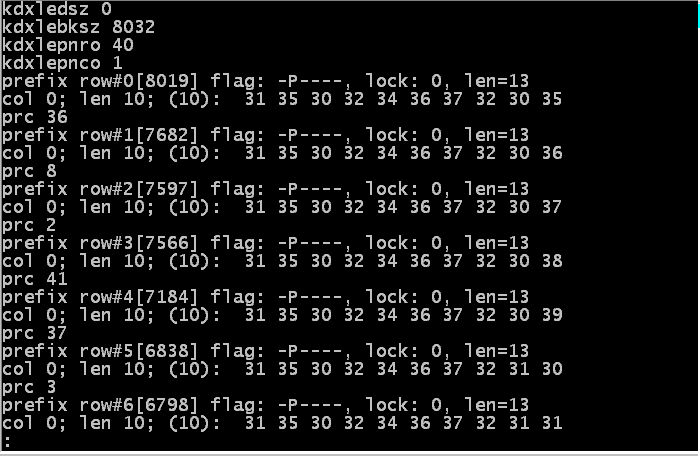


prod
the uncompressed index looks like this ( 3 images ).
INDEX_NAME COMPRESS
------------------------------ --------
S713~0 DISABLED
S713~Z1 DISABLED


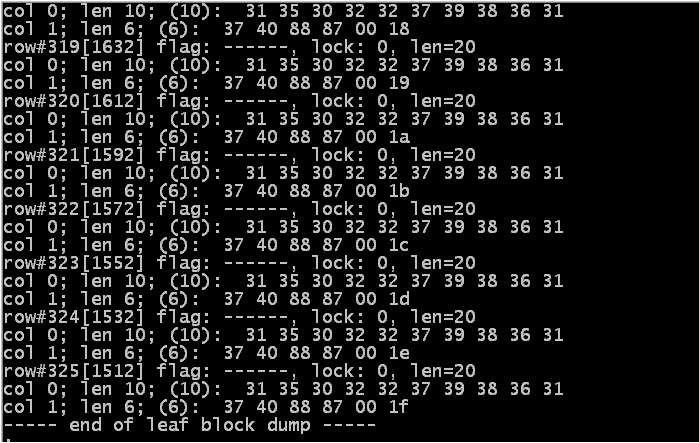
Over twice as many blocks uncompressed as compressed:
Quality:
BLOCKS
----------
76800
Production:
BLOCKS
----------
198400
I picked that one at random, the first object I could find in the QA system that wasn't already working "productively."
And, kudos to Richard Foote, going deep into index land.
http://richardfoote.wordpress.com/2008/02/17/index-compression-part-i-low/
And don't forget to visit the other side of the aisle:
- AIX DB2
- MS SQL Server
: How Microsoft Lowered SAP Landscape Storage Costs with SQL Server
: Elke Bregler, Principal Technologist/SAP Basis Team lead, Microsoft Corp.
: Juergen Thomas, Program Manager, Microsoft Corporation
: ASUG Session
: Date/Time: Tuesday, May 18, 2:00 p.m.
: Session Code: 0807
: Criteria are discussed on how the SAP Basis team decided on which tables or databases to apply page dictionary compression and row compression. Savings on volume and financial impact will be discussed.
Last but not least, thanks to Juergen Kirschner and Paul Loos of Oracle for commenting on our early slide drafts, plus years of coaching and mentoring us.
