[Portions of this blog originally appeared on the ASUG.COM site]
[ 1 | 2 | jim.spath/blog/2010/03/23/virtualizing-the-enterprise-infrastructure--part-3-the-d%C3%A9nouement ]
It's a common refrain that each new hardware generation brings new power, decreasing costs; it's also common to hear that processing demands grow faster than systems can be deployed.
Once every few years, a technology team has the opportunity to do some serious architectural remodeling of their infrastructure. Often, the only chance to improve systems are cosmetic changes, or moving a little hardware here or there. But other than switching vendors or CPU types, or doing a massive change like Unicode, hardware upgrades are typically low impact processes that swap model A out and swap model T in. Not this time.
As we looked toward the end of our hardware useful life (read: lease) about 18 months ago, we began the planning process for what our next generation data center would look like. For decades, every new hardware generation has brought about performance improvements, to the point that these are considered practically birthrights of the "new model." However, we've been seeing predictions of limits being reached, real ones like the speed of light, not just economic ones about specific fabrication methods being high cost, low yield. I won't document the choices we looked at, but let's just say all options were on the table.
What has been trending for the last several years has been increased virtualization. I won't repeat the benefits and justifications for this, though it is important to look at competing factors. Combining many applications into one infrastructure means that any downtime affects all users of those applications, whereas separating them isolates the impact to the specific fault zone. And unless you're prepared to pay premium prices for the most fault-tolerant systems on the planet, disaster avoidance should be in your playbook. Our prior generation of big systems separated non-production from production systems. Our concern was that testing of anything from basic software patching, to firmware, to cluster software, were all risks that needed to be tested in isolation. Our confidence with the stability of the outgoing hardware, in comparison to anything we'd seen in the last several generations, grew to the point we decided to combine non-production and production. The advantage of this move is we gained the performance overhead of having more CPU and memory available for production systems to take when needed.
Once the general plan was established, my role in capacity planning and benchmarking kicked in. We have redundant data centers, so all designs called for us to allocate sufficient resources to either site alone to run the business. I came up with the "rule of threes" where each rack or frame could be thought to contain 3 parts - highly available production, non-highly available production, and development/quality systems. In case of a data center outage, dev/QA goes away (or shrinks to a very small allocation) on the remaining nodes, highly available systems come up if their primary location went away, then we decide which other production gets started based on business rules, or manual intervention. High availability designs are not free, so that's part of the allocation model.
For benchmarking and metrics, I took several avenues, from interviewing peers, to downloading spec sheets and published benchmarks, to running my own tests on remote systems virtually, to running tests on loaner hardware in house. With these data came massive spreadsheets and what-if scenarios, talking through the options with my team mates, with the hardware vendors, and with SAP contacts. In order to size the system, I ran extensive measurements of existing application performance, including low-level system usage, application run-times from dialog response time to batch run-times to user logons to RFC function call and data transfer values.
Chart #1 below is one example from analyzing existing literature, where I reviewed published benchmarks for several hardware generations so as to predict what we could expect once new machines arrived. In a way, it is a moving target, as benchmarks may show systems not yet available, and at the end of the procurement process newer systems will be announced. You can't depend entirely on published benchmarks, you've got to run your own. I can't share them here as I worked on a few with vendors under NDA. I will say that if you get results that differ from the published specs in any way, keep asking for explanations until you are satisfied. Otherwise, you'll need to oversize your systems to compensate for the uncertainties.
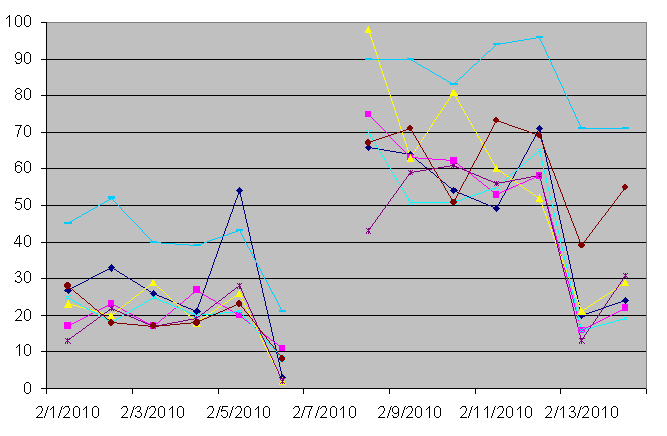
Chart #2 is one view of an analysis I performed simulating combining existing stand alone systems into virtual combinations. It can be tempting to say "2 plus 2 equals 4" - if we have 2 separate machines, we'll just get a replacement machine with twice the power and combine the loads. That will deliver enough power, though at greater expense. Trying to run the combined loads with too small a system would be cheaper, yet run the risk of slower transaction times than before. If you notice the "plateaus" on the chart, this is where older hardware was running "flat out" during background processing. When combining systems, this appetite needs to be addressed so that background wok doesn't overwhelm transaction systems.
Chart #3 and chart #4 show one of the scenarios we went through, trying to model what could run together, in what size system. In addition to handling current load, we needed to predict future loads, as well as determine a strategy for including unplanned growth like new applications currently on the drawing boards and wish lists.
Chart 5 is a little bit of a teaser - it belongs in part 3 of this series!
Then the shopping and negotiations started. One challenge we typically face in specifying how the systems will be configured is the evolution of processor families and deployment models. From the 2-way, to the 4-way, on up to the massive 64 or 128 CPU behemoths, each niche has its advantages and disadvantages. Previously, we chose 2 CPU "pizza boxes" for application servers, as our estimate was they would be inexpensive, reliable (through redundancy) and somewhat scalable, though for huge performance requirements such as a Unicode system conversion, their smaller footprint made them less useful. Not useless, just more work to set up and leverage, compared to a 12 or 16-way system, for the administrative time spent. That factor becomes important as we strive for standardization, minimizing the custom work required to deploy and maintain systems for users.
Chart 1

Chart 2

Chart 3

Chart 4

Chart 5