
- SAP Community
- Products and Technology
- Additional Blogs by Members
- How to avoid modeling errors in NetWeaver BPM? Par...
Additional Blogs by Members
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-07-2009
10:38 AM
Preface
Business processes sometimes need to process their input in batches. One then faces the challenge to iterate over the elements of some list-valued expression (the “batch”) and trigger some identical activity for each of the contained “line items”. This blog posting discusses how NetWeaver BPM (“Galaxy”) supports scenarios like that with a variety of different modeling approaches. I specifically pinpoint the pros and cons that go along with each of the proposed solutions. We start with plain sequential loops and later proceed to dynamic parallelism, just like in BPMN’s “Multiple Instance Activities”.
Sequential Loops
And in fact, when strictly sequentially looping over the list, modeling the above sketched scenario is something of a no-brainer in NetWeaver BPM. All one needs to do is add an integer-valued “index” data object to your process model. That index variable needs to get initialized as zero sometime before the looping may commence. A plain decision gateway (“XOR split”) takes care of comparing that index to the size of the batch (which is, in fact, a list-valued [mapping] expression of some sort). As long as it falls below, the “happy path” is taken where the to-be-repeated activity initially extracts the line item (at the current index) from the batch, then processes that line item and finally increments the index by one. Below, I have modeled a plain sequential loop, iteratively processing the line items contained in the "Batch" data object, holding a list of plain strings:

The "Index" data object is initialized to zero as part of the start event's output mapping. What we will also need to check if we have reached the batch's "bottom" is a custom function batchSize that determines the size of a string list (a plain string-typed element having an upwards unbounded occurrence)and another function lineItemAtIndex that returns an element of a given string list at the given index.

You can directly define those functions' signatures in your "Process Composer" project but have to supply the actual Java-based implementation in a separate EJB which you make available (register) in your CE server's JNDI directory under the specified lookup name.
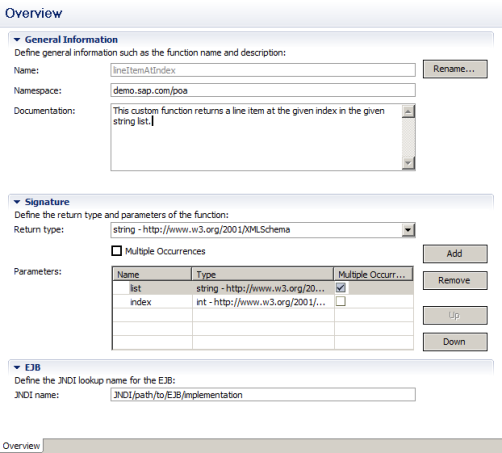
Creating custom mapping functions is easy and straightforward and here's a great article that explains in detail how this is done. Just follow the steps described in there and you are all good with your mapping functions.
The actual activity to process individual line items (which may, in fact, be a subflow invocation as depicted here) may then take advantage of that function to extract a line item and map in onto the activity's signature.

That actitity's output mapping then needs to increment the "Index" data object by one to continue iterating over the batch.
Sequentially looping over a list-valued expression is easy and there are hardly any mistakes you can make. Just make sure to increment the index in each cycle and break out of the loop as soon as you have processed all line items.
Recommendation: Go for sequential loops if the batch is small, processing an individual line item is fast, and process latencies are not all that critical. It's the right choice for getting to results quickly.
Whenever you rather want to process line items in parallel, you have to go for different modeling patterns.
Dynamic Parallelism
The rationale for doing batch operations in parallel is to mutually de-couple line item processing from one another. In this way, you may not only end up with shorter total process turnaround times but also process different line items concurrently which comes in handy to utilize resources more efficiently. For instance, you may dispatch tasks (corresponding to line items) to different people at the same time.
The initial idea of dynamically spawning concurrent flow is to make use of AND split gateways to process a line item in parallel to initiating preparation for the next line item. In order to introduce a private data object for processing each line item and, thus, avoid race conditions, forking that parallel flow happens in a separate subflow:

In there, the first (upper) branch invokes the actual processing of a specific line item whereas the second (lower) branch immediately returns to the invoking (parent) process. In my earlier postings on How to avoid modeling errors in Netweaver BPM? Part 4: Submerge in subflows and How to avoid modeling errors in Netweaver BPM? Part 2: More fun with end events!, I already introduced you to Galaxy's concept of de-coupling a subflow's final completion (when all tokens have ceased to exist) to continuing execution in the invoking process (when the first token triggers the subflow's end event). Above-depicted process is then invoked from a plain sequential loop as shown below:

Asynchronously processing line items is a great way of introducing dynamic parallelism but comes at a price:
- There is no wayof returning ad aggregating result data from processing individual line items. In fact, once the "asynchronously process line item" subflow has returned, no more data may be passed to the outer flow.
- Besides, the outer process will not even notice if and when all line items have completed processing. This is why the "confirm process completion" task was put into the outer process. An end user has to manually confirm that whatever had to happen in the line item processing has, in fact, be successfully completed.
Nevertheless, the afore-sketched pattern is a good way of introducing dynamic parallelism at low cost.
Recommendation: Use dynamic parallelism w/o synchronization whenever (1) you may parallelize line item processing, (2) you do not need to collect and aggregate output data for each line item (line when performing some asynchronous operations), and (3) you can make sure that the outer process does not complete before all line items were fully processed.
You may also use this pattern in an endlessly looping process where (instead of triggering a task), the "no more line items" process branch is redirected to some upstream activity (like to fetch another batch of line items).
Synchronizing Dynamic Parallel Flow
Caution! The approach which is described in this section is not an official statement of what we support or encourage our customers to do. At this point in time, recursive subflow invocations is an experimental feature which can have unexpected side-effects, including a crash of your CE server instance and a failure to recover from that. In particular, avoid "deep" recursive invocations having a stack depth of >10!
The remaining challenge is to also synchronize dynamically forked parallel processing "threads". This is not only crucial for collecting and aggregating results from each line item's processing activity but also to only continue executing (or completing) the outer flow when all line items were fully processed.
The idea is to make use of recursively invoking the subflow shown below to
- Extract the line item to be processed by this specific subflow instance ("extract line item") to a separate "LineItem" data object [optional step];
- Concurrently process a specific line item ("line item processing") and temporarily materialize the result in a separate data object ("Result");
- Recursively trigger processing the remaining work items before, incrementing the "Index" data object, and temporarily mapping the result (of all remaining work items) into a data object "Aggregate";
- Synchronizing both branches and ultimately merging (aggregating) the individual result of this line item ("Result" data object) and the remaining line items ("Aggregate" data object) which is then passed to the invoking process.

Mind that recursive subflow invocation is in many cases not supported. In fact, you may only define recursive invocations for non top-level processes. That is, you do need some outer process initially invoking the recursive subflow in this scenario. Also, this blog posting is not an official statement on Galaxy features that we encourage our customers to use.
So in essence, recursively invoking subflows is inherently evil and originates from the "dark side" of Galaxy. When erroneously used, your process may go hog-wild and even screw up your CE application server.
Recommendation: Only use recursive subflow invocation with extreme caution! If spawning new subflow instances in an uncontrolled fashion, you may end up spending all runtime resources in no time. Nevertheless, the afore-sketched pattern is the only way I can think of to really control and synchronize dynamic parallelism. In detail, it allows you to collect results from each individual line item's processing which is a frequent pattern in many applications.
When it comes to merging the current line item's result data ("Result" data object) with the global list-valued "Aggregate" data object, you may make use of an existing mapping feature which lets you choose between different assignment operations. In this particular case, you want to go for an "Append" assignment which adds the "Result" content as the last item to the "Aggregate" list.

Be aware that when ascendingly iterating over the batch (1st, 2nd, ..., n-th line item), results will appear in "Aggregate" as n-th, (n-1)-th, ..., 2nd, 1st result item. To enforce an identical ordering of line items and corresponding results you may simply start with the n-th line item ("Index"=number of line items in batch minus 1) and decrement by one in each recursive invocation of that subflow.
2 Comments
Related Content
- Business Rule Framework Plus(BRF+) in Enterprise Resource Planning Blogs by Members
- From Certified ABAP Developer on SAP NetWeaver to Certified Back-End Developer with ABAP Cloud in Technology Blogs by SAP
- ABAP Platform for SAP S/4HANA 2023 in Enterprise Resource Planning Blogs by SAP
- New SAP BW/4HANA Learning Journey in Technology Blogs by SAP
- SAP BW/4HANA 2023 - Release Update in Technology Blogs by SAP