In one of my requirements, I had faced problem to choose UDF Execution type Context. This motivated me to explore this area of mapping. Also a comment on my previous blog, by Mr. Prateek Srivastava, a popular contributor on SDN, inspired me to explain the practical example of UDF type Context.
I have configured a scenario to explain this concept with simplicity. In the scenario employee details, are collected on the basis of department Id. The Employee Ids were generated on the basis of employee details and department Id. I have taken a simple file-to-file scenario to demonstrate this concept. A file, which consists of department Id and Employee data, is sent to PI and the combination of department Id and Employee details facilitates the generation of Employee Id.
Before configuring this scenario, I was not able to understand UDF Execution's type context. I had written a UDF for this scenario and come to know the exact use of UDF Context type. I would like to share my experience with fellow PI consultants.
Scenario: -
The file is placed on ftp. File adapter picks it up. File contains employee data and department data. Employees are distributed in different departments. Each department has its own ID. Based on the department Id, employee Id can be generated. The Employee Id generation logic is implemented in message mapping of PI. In message mapping I have defined a UDF. It checks the department Id and generates the Id for each Employee that belongs to the department.
Below are Source and Target structures.

Fig.1
Following is the sender data file, which contains,
Department: Consist of Department records.
Employee: Consist of Employees records.

Fig.2
As we can see department Id consist of value 10. Hence, we need to send all the Employees and for each Employee, we have to generate Employee Id as, 1001,1002,1003,1004 etc. depending upon Department Id.
Department Id 10 has four Employees, so the Employee Id would be generated as 1001,1002,1003 and 1004.
Department Id 20 has three Employees, so the Employee Id would be generated as 2001,2002 and 2003.
For IR part create Data type, Message Type, Service Interfaces, Operation Mapping by normal method.
Also configure ID part for file-to-file scenario.
When we create any UDF we can see, three cache execution methods,
1) Value.
2) Context.
3) Queue.
Value is used to process individual input values (i.e. like a single variable) of a field for each function call.
Context and Queue are used to process multiple input values (i.e. like a string array) of a field for each function call.
Let's see the concept of Context type in UDF.
UDF Logic:
Following is the UDF that contains logic to generate Employee Id.
UDF logic is mainly dependant on Context Change node. Only by Context Change we can identify how many Employees are there in each Department.
As shown in Fig.4, This UDF requires input.
- employee: Employee records. (Context of this input is on Department Header)
- departmentId: Department records.
Importance of Context Change node for this requirement:
There are number of Departments and each Department has number of employees. Therefore employees can be classified on the basis of their department. Context Change node distinguishes employees based on their Department.
Working of UDF in case of Context:
Context: When Execution type is Context the Context Change node is not considered as data node. But it is considered as a separation layer between two Departments. In the UDF, logic is maintained only for one group of data (e.g. Only Employees under Department Id 10). This logic automatically gets executed to other groups (e.g. for Employees under Department Id 20) also.
Comparison between Context and Queue Type:
For Context type the function getEmployeeId (UDF name - Class) is called as many times as Context Change node occurs in the data. As shown in fig. 5, Context Change node occurs twice so the function will be call two times.
For Queue type the function getEmployeeId is called only once. Context Change is considered data node. For detail explanation refer blog no. Context and Queue in Message Mapping UDF
E.g.
As we have seen in Fig.2 and Fig.5,
Department no. 10 has four Employees.
Department no. 20 has three Employees.
For this data UDF logic works as follows.
At the beginning of code, Counter for Employee Id is initialized to Department Id.
When Department Id is 10, then 10 is assigned to counter, after applying arithmetical operation the Counter is initialized to 1000. (10 * 100)
When Department Id is 20, then 20 is assigned to counter, after applying arithmetical operation the Counter is initialized to 2000. (20 * 100) Here, only 1st element of Department Id is considered from each group. Groups are defined depending on separation of Context Change node. See the fig.3
In for loop, Counter is incremented and returns the same value for each Employee. This logic is executed only for 1stgroup of data. As soon as Context Change node is encountered, logic gets applied to next group of data from the start of UDF.
As we have seen in Fig.2 the first Department, with Dept Id 10, consists of four employees. The UDF logic executes only for four nodes and generates Employee Id as 1001,1002,1003,1004. Once the 4thId is generated, context change node is encountered and there is no further generation of Employee Ids for Dept Id 10.
If any data node is present after the Context Change node then the UDF logic is executed once again. In our case, data node is there for Department Id 20, so the getEmployeeId function is called again. The counter gets initialized and produces Employee Id as 2001,2002,2003 for three employees from Department Id 20.
So the output will look like the one shown in Fig.5
This is possible only if the UDF logic could detect the Context Change node. The context change node is significant only if the UDF execution type is context.
Lets see the practical example of this.

Fig.3
Execution Type: Context
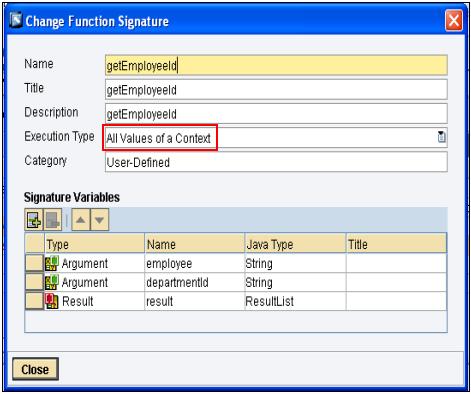
Fig.4
As you can see the first cluster have 4 values (i.e. 1001, 1002, 1003, 1004). Then there is a context change and hence the next value is reinitialized to 2001 depending upon Employee Id. This is possible only if the UDF execution type is context.

Fig.5
Output:

Fig.6
Conclusion:
The context type of the UDF can be used in case if you want to segregate data of one group to other group. So we can generalize that whenever the context change node has a significant impact on the UDF logic, context type of UDF can be utilized.
Reference:
http://help.sap.com/saphelp_nw04/helpdata/en/f8/2857cbc374da48993c8eb7d3c8c87a/frameset.htm
Context and Queue in Message Mapping UDF
